Java - 五大集合(数据结构)要点

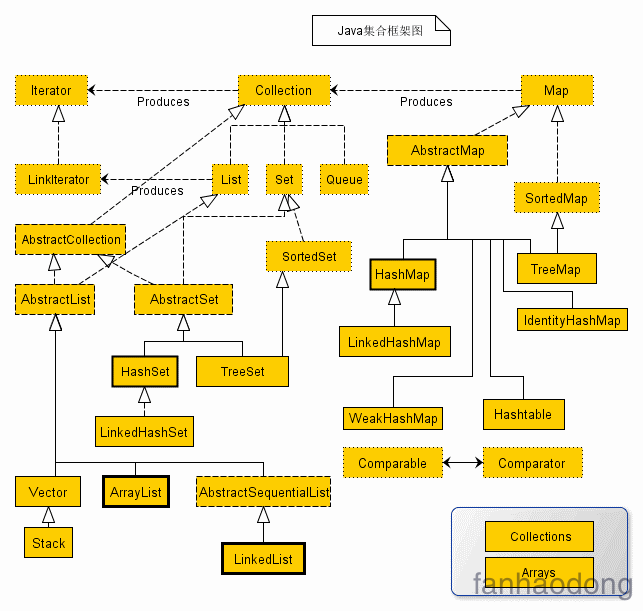
1. List
1.主要问题
- 了解一下ArrayList和CopyOnWriteArrayList的 增删改查 实现原理
- 看看为什么说ArrayList查询快而增删慢?
- CopyOnWriteArrayList 与 Vector 的选择
- LinkedList 与 ArrayList
- Arrays.asList(....) 的使用问题
- Collections这个工具类
- java9+ List.of()方法 map , set 同理 都有,不多写了
2.为什么arraylist 不安全
- 我们查看源码发现 arraylist 的 CRUD 操作 并么有涉及到锁之类的东西
- 底层是数组,初始大小为10
- 插入时会判断数组容量是否足够,不够的话会进行扩容
- 所谓扩容就是新建一个新的数组,然后将老的数据里面的元素复制到新的数组里面(所以增加较慢)
3.CopyOnWriteArrayList 有什么特点?
- 它是List接口的一个实现类,在 java.util.concurrent ( 简称 JUC ,后面我全部改成 juc ,大家注意下)
- 内部持有一个ReentrantLock lock = new ReentrantLock(); 对于 增删改 操作都是 先加锁 再 释放锁 线程安全.并且锁只有一把,而读操作不需要获得锁,支持 并发 。
- 读写分离,写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给array
4.CopyOnWriteArrayList 与 Vector 的选择
- Vector是 增删改查 方法都加了 synchronized ,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在 增删改 上加 锁 ,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。
- Vector和CopyOnWriteArrayList都是 List接口 的一个实现类
5.CopyOnWriteArrayList适用于什么情况
- 我们看源码不难发现他每次增加一个元素都要进行一次拷贝,此时严重影响了增删改的性能,其中和arraylist 差了好几百倍 我自己测试过,
- 所以对于读多写少的操作 CopyOnWriteArrayList 更加适合 ,而且线程安全
- DriverManager 这个类 就使用到了CopyOnWriteArrayList
6. LinkedList 和 ArrayList 对比
LinkedList<Integer> lists = new LinkedList<>(); lists.addFirst(1); lists.push(2); lists.addLast(3); lists.add(4); lists.addFirst(5); lists.forEach(System.out::println); // 5 2 1 3 4 复制代码
addFirst 和 addLast 方法很清楚 ,
push 方法的话 ,默认是 andFirst 实现
add 方法默认是 addLast 实现 ....
所以上面总结一下就是 add和last , push和first ,
其实我们要明白一下 , 链表相对于数组来说, 链表的添加和删除速度很快 , 是 顺序添加删除 很快,因为一个linkedList会保存第一个节点和最后一个节点,时间复杂度为 O(1) , 但是你要指定位置添加 add(int index, E element) , 那么此时他会先遍历, 然后找到改位置的节点, 将你的节点添加到他前面 , 此时时间复杂度最大值为 O(n) ,
数组呢 , 我们知道ArrayList底层实现就是数组 , 数组优点就是由于内存地址是顺序的, 属于一块整的 , 此时遍历起来很快 , 添加删除的话 ,他会复制数组, 当数组长度特别大时,所消耗的时间会很长
这是一张图 , 大家可以看一下 ,

7. Arrays.asList() 方法返回的数组是不可变得吗 ?
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5); integers.set(2, 5); // 这个操作可以 //integers.add(6); 这个会抛出异常 integers.forEach(System.out::println); // 1 2 5 4 5 1. 很显然我们是可以修改 list集合的 可以使用set方法 2. 但是当我们尝试去使用add() 方法时,会抛出 java.lang.UnsupportedOperationException 的异常, 不支持操作的异常 3.当我们使用 java9+时 可以使用 List.of()方法 ,他就是彻彻底底的不可修改的 复制代码
8.怎么将一个不安全数组换成安全数组
1. 使用 Collections这个工具类 List<Integer> integers1 = Collections.synchronizedList(integers); 2. java5+ 变成 CopyOnWriteArrayList CopyOnWriteArrayList<Integer> integers2 = (CopyOnWriteArrayList<Integer>) integers; 3. java9+ ,使用 List.of() 变成只读对象 复制代码
10. Collections 工具类
1. 创建一个安全的空集合,防止NullPointerException异常 List<String> list = Collections.<String>emptyList(); 2. 拷贝集合 Collections.addAll(list, 2,3, 4, 5, 6); 3. 构建一个安全的集合 List<Integer> safeList = Collections.synchronizedList(list); 4. 二分查找 Collections.binarySearch(list, 2); 5.翻转数组 Collections.reverse(list); 复制代码
翻转有很多方法 java.util.Collections , 可以去学一下, 有学习能力的可以去学习一下 Google的 Guava 很强的工具类 , 里面很多
2. Set
1. 问题
- HashSet、TreeSet和 LinkedHashSet三种类型什么时候使用它们
- Hashset的实现方式? HashSet去重方式 ? TreeSet 去重方式?
- 那怎么实现一个线程安全的 HashSet , 因为JDK没有 ConcurrentHashSet
- CopyOnWriteArraySet的实现
2.HashSet、TreeSet和LinkedHashSet三种类型什么时候使用它们
- 如你的需求是要一个能快速访问的Set,那么就要用HashSet , HashSet底层是
HashMap实现的 ,其中的元素没有按顺序排列. - 如果你要一个可排序Set,那么你应该用TreeSet, **TreeSet的底层实现是
TreeMap** - 如果你要记录下插入时的顺序时,你应该使用LinedHashSet
- Set集合中不能包含重复的元素 ,每个元素必须是唯一的,你只要将元素加入set中,重复的元素会自动移除。所以 可以去重 , 很多情况下都需要使用 (但是去重方式不同)
- LinkedHashSet正好介于HashSet和TreeSet之间,它也是一个基于
HashMap和双向链表的集合,但它同时维护了一个双链表来记录插入的顺序,基本方法的复杂度为O(1)。 - 三者都是线程不安全的, 需要使用 Collections.synchronizedSet(new HashSet(…));
3. HashSet和LinkedHashSet 判定元素重复的原则是相同的
- 会先去执行hashCode() 方法 ,判断是否重复
- 如果hashCode() 返回值相同 , 就会去判断equals方法,
- 如果equals() 方法还是相同, 那么就认为重复
4. TreeSet 判断元素重复原则
TreeSet的元素必须是实现了 java.lang.Comparable<T> 接口 , 所以他是根据此个接口的方法 compareTo 方法进行判断重复的, 当返回值一样的时,认定重复
5. 怎么实现一个线程安全的 hashset
我们看源码 会发现 他里面有一个 HashMap ,那为什么要用(用transient关键字标记的成员变量不参与序列化过程。) 为什么呢 ,因为 HashMap 已经实现了Serializable,
怎么实现一个 ConcurrentHashSet
- 自己写一个 实现类 实现 Set ,里面 定义一个 ConcurrentHashSet ,和 hashset的方式一样
- 直接用 第三方库 ----- com.alibaba.dubbo.common.utils.ConcurrentHashSet ,阿里的库 ....
package com.alibaba.dubbo.common.utils;
import java.util.AbstractSet;
import java.util.ConcurrentModificationException;
import java.util.Iterator;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class ConcurrentHashSet<E> extends AbstractSet<E> implements Set<E>, java.io.Serializable {
private static final long serialVersionUID = -8672117787651310382L;
private static final Object PRESENT = new Object();
private final ConcurrentMap<E, Object> map;
public ConcurrentHashSet() {
map = new ConcurrentHashMap<E, Object>();
}
public ConcurrentHashSet(int initialCapacity) {
map = new ConcurrentHashMap<E, Object>(initialCapacity);
}
...............
}
复制代码
很显然跟我说的好像 一模一样 ,哈哈哈 ,我也是看别人学的,只是看你用的巧不巧,他继承了AbstractSet这个抽象类,重写了 他部分想要改的方法, 同时也实现了 set接口
6.CopyOnWriteArraySet的实现
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
复制代码
很显然翻源码我们发现 他实现了 CopyOnWriteArrayList();
3. Map
1. 问题
- 最常见的问题就是 HashMap的底层实现 , JDK1.7和JDK1.8的差别 ,这个我不讲了,如果想要看,自己百度我提供一个我自己写的一个HashMap简单实现
- Hashtable、HashMap 以及ConcurrentHashMap 的区别
- 深度学习 ConcurrentHashMap 和 HashMap 靠你们自己了 ,这俩研究透, 你已经向大神进阶了
- ConcurrentSkipListMap 与 TreeMap 的选择
- LinkedHashMap的使用
2. Hashtable的学习
- Hashtable和ConcurrentHashMap以及ConcurrentSkipListMap 以及TreeMap 不允许key 和 value值 为空,但是 HashMap 可以 key 和value值都可以为空,
- Hashtable的方法 都加了Synchronized 关键字修饰 , 所以线程安全
- 它是 数组+链表的实现
3.ConcurrentHashMap 问题
- 取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,
- 采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
- 把Table数组+单向链表的数据结构 变成为 Table数组 + 单向链表 + 红黑树的结构。
- 当链表长度超过8以后,单向链表变成了红黑数; 在哈希表扩容时,如果发现链表长度小于 6,则会由红黑树重新退化为链表。
- 对于其他详细我不吹,看懂的么几个 ,他比HashMap 还要难,
- 对于线程安全环境下 介意使用 ConcurrentHashMap 而不去使用 Hashtable
4. 为什么不去使用 Hashtable,而去使用ConcurrentHashMap ?
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
5. HashMap 问题
-
其中部分信息咱们还能聊聊,不会的我就算了
-
内部节点分为
Node<K,V>和TreeNode<K,V>, 都直接间接的实现与Map.Entry<K,V>, 后者所占用的空间较大,所以是一种空间换时间的想法 , 前者只要保存两个节点信息, 后者需要保存四个 -
存储结构是
数组+链表或者数组+ 红黑树实现,有个阈值,当链表长度大于8,大于8的话把链表转换为红黑树,当小于等于6时会自动转成链表
原因: (反正我看不懂,只是解决碰撞概率的问题,数学问题这个是)
红黑树的平均查找长度是log(n),长度为8,查找长度为log(8)=3,链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有转换成树的必要;链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8的原因是:
中间有个差值7可以防止链表和树之间频繁的转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
-
Node[] table的初始化长度length(默认值是16),LoadFactor为负载因子(默认值是0.75), 例如为1,虽然减少了空间开销,提高了空间利用率,但同时也增加了查询时间成本;加载因子过低,例如0.5,虽然可以减少查询时间成本,但是空间利用率很低,同时提高了rehash操作的次数
-
实现链接,大家不会写可以看看
-
HashMap是非synchronized ,线程不安全
-
大家可以看看高能讲解:
6. ConcurrentSkipListMap 与 TreeMap 的选择
- ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,利用底层的插入、删除的CAS原子性操作,通过死循环不断获取最新的结点指针来保证不会出现竞态条件。在理论上能够在O(log(n))时间内完成查找、插入、删除操作。调用ConcurrentSkipListMap的size时,由于多个线程可以同时对映射表进行操作,所以映射表需要遍历整个链表才能返回元素个数,这个操作是个O(log(n))的操作。
- 在JDK1.8中,ConcurrentHashMap的性能和存储空间要优于ConcurrentSkipListMap,但是ConcurrentSkipListMap有一个功能: 它会按照键的自然顺序进行排序 。
- 故需要对 键值排序 ,则我们可以使用TreeMap,在 并发场景 下可以使用ConcurrentSkipListMap。
- 所以 我们并不会去 纠结 ConcurrentSkipListMap 和 ConcurrentHashMap 两者的选择,因为我解释的很好了
7. LinkedHashMap的使用
- 主要是为了解决读取的有序性,
- 基于 HashMap 实现的
- 可以看看我的 这篇文章 : anthony-dong.github.io/post/linked…
4. Queue
队列在于你走向高级工程师必须走的一步 . 一开始我们对于他并不了解,但是你会发现并发包里面一堆关于队列的类,你就知道了他的关键所在,先进先出的使用场景很常见的 通过我这段时间的学习,我发现在线程池这块,还有这消息队列,还有在数据库连接池这块都需要队列.这些中间件对于队列的依赖性太过于强烈. 所以学会队列是很重要的一步.这些内容我会慢慢补充的.
1. 队列是什么
我们都知道 队列 (Queue)是一种 先进先出 (FIFO)的数据结构,Java中定义了 java.util.Queue 接口用来表示队列。Java中的 Queue 与 List 、 Set 属于同一个级别接口,它们都是实现了 Collection 接口。注意: HashMap没有实现 Collection 接口
2.Deque 是什么
- 它是一个双端队列
- 我们用到的 linkedlist 就是 实现了 deque的接口
- 支持在两端插入和移除元素
- 区别与 循环队列 循环队列实现讲解
3.常见的几种队列实现
1. LinkedList
LinkedList 是链表结构,队列呢也是一个列表结构,继承关系上 , LinkedList实现了Queue , 所以对于Queue来说 ,
添加是 offer(obj) , 删除是 poll() , 获取队头(不删除)是 peek() .
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
}
// 1, 2 , 3
复制代码
2. PriorityQueue
PriorityQueue维护了一个有序列表,插入或者移除对象会进行Heapfy操作, 默认情况下可以称之为小顶堆 。当然,我们也可以给它指定一个实现了 java.util.Comparator 接口的排序类来指定元素排列的顺序。
PriorityQueue 是一个无界队列 , 当你设置初始化大小还是不设置 , 都不影响他继续添加元素
3. ConcurrentLinkedQueue
ConcurrentLinkedQueue 是基于链接节点的并且线程安全的队列。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大小 ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
4. ArrayBlockingQueue与LinkedBlockingQueue的区别,哪个性能好呢
-
ArrayBlockingQueue 是有界队列
-
LinkedBlockingQueue 看构造方法区分 , 默认构造方法最大值是 2^31-1
-
但是当 take 和 put操作时 ,ArrayBlockingQueue速度要快于 LinkedBlockingQueue原因是什么
1.队列中的锁的实现不同 ArrayBlockingQueue中的锁是没有分离的,即生产和消费用的是同一个锁; LinkedBlockingQueue中的锁是分离的,即生产用的是putLock,消费是takeLock 2.在生产或消费时操作不同 ArrayBlockingQueue基于数组,在生产和消费的时候,是直接将枚举对象插入或移除的,不会产生或销毁任何额外的对象实例; LinkedBlockingQueue基于链表,在生产和消费的时候,需要把枚举对象转换为Node进行插入或移除,会生成一个额外的Node对象,这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。
-
问题有哪些
- 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出。
- 在使用ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,
LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,
即LinkedBlockingQueue消耗在1500毫秒左右,而ArrayBlockingQueue只需150毫秒左右。
- 按照实现原理来分析, ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行 。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。
-
我们测试的是 ArrayBlockingQueue 会比 LinkedBlockingQueue性能好 , 好差不多50%起步 ,
5. BlockingQueue的问题 以及 ConcurrentLinkedQueue 的问题
-
BlockingQueue可以是限定容量的。 -
BlockingQueue实现主要用于生产者-使用者队列,但它另外还支持collection接口。 -
BlockingQueue实现是线程安全的 -
BlockingQueue是阻塞队列 (看你使用的方法) ,ConcurrentLinkedQueue是非阻塞队列区别
LinkedBlockingQueue 是一个线程安全的阻塞队列,基于链表实现,一般用于生产者与消费者模型的开发中。采用锁机制来实现多线程同步,提供了一个构造方法用来指定队列的大小,如果不指定大小,队列采用默认大小(Integer.MAX_VALUE,即整型最大值)。
ConcurrentLinkedQueue 是一个线程安全的非阻塞队列,基于链表实现。java并没有提供构造方法来指定队列的大小,因此它是无界的。为了提高并发量,它通过使用更细的锁机制,使得在多线程环境中只对部分数据进行锁定,从而提高运行效率。他并没有阻塞方法,take和put方法.注意这一点
6. 简要概述BlockingQueue常用的七个实现类
有一个是 JDK1.7才加入的, 所以常见的就六个
1. ArrayBlockingQueue
构造函数必须传入指定大小, 所以他是一个有界队列
2. LinkedBlockingQueue
分为两种情况 , 第一种构造函数指定大小, 他是一个有界队列 , 第二种情况,不指定大小他可以称之为无界队列, 队列最大值为 Integer.MAX_VALUE
3. PriorityBlockingQueue (还有一个双向的LinkedBlockingDeque)
他是一个无界队列 , 不管你使用什么构造函数 ..
一个内部由优先级堆支持的、基于时间的调度队列。队列中存放Delayed元素,只有在延迟期满后才能从队列中提取元素。当一个元素的getDelay()方法返回值小于等于0时才能从队列中poll中元素,否则poll()方法会返回null。
4. SynchronousQueue
这个队列类似于Golang的channel , 也就是chan ,跟无缓冲区的chan很相似. 比如take和put操作就跟chan一模一样. 但是区别在于他的poll和offer操作可以设置等待时间.
如果你学过golang的话. 应该理解 . 我写个例子
func main() {
ch := make(chan int, 0)
start := time.Now().UnixNano()
go func() {
time.Sleep(time.Millisecond * 500)
ch <- 1
}()
x := <-ch
fmt.Printf("msg : %d , spend : %dms/n", x, (time.Now().UnixNano()-start)/1e6)
}
// 输出
// msg : 1 , spend : 500ms
复制代码
那么换而言之 , Java呢
public class TestSync {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue<Integer> queue = new SynchronousQueue<>();
long start = System.currentTimeMillis();
new Thread(() -> {
try {
Integer poll = queue.take();
System.out.printf("receive : %d , spend : %dms./n", poll, System.currentTimeMillis() - start);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
//sleep 2000ms
TimeUnit.SECONDS.sleep(2);
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
// 输出
//receive : 1 , spend : 2060ms.
复制代码
但是他和chan不同的是, 他的poll操作吧, (类似于golang的 select case 操作) , 等不到放弃, 返回一个null.
但是唯一不同的是 他可以指定等待时间.超过等待时间再放弃.
Integer poll = queue.poll(1000,TimeUnit.MILLISECONDS); 复制代码
这个就是等待1000ms , 等不到放弃了 .
像线程池中用 SynchronousQueue 使用的是 offer(obj) 操作, 也就是说干脆插入不进去.因为他懒得等 , 但是offer可以指定等待时间的.
总结一下. take 和 put 一对,是死等待 , poll和offer灵活, 活着来
5. DelayQueue
Java延迟队列提供了在指定时间才能获取队列元素的功能,队列头元素是最接近过期的元素。没有过期元素的话,使用poll()方法会返回null值,超时判定是通过getDelay(TimeUnit.NANOSECONDS)方法的返回值小于等于0来判断。延时队列不能存放空元素。
添加的元素必须实现 java.util.concurrent.Delayed 接口
@Test
public void testLinkedList() throws InterruptedException {
DelayQueue<Person> queue = new DelayQueue<>();
queue.add(new Person());
System.out.println("queue.poll() = " + queue.poll(200,TimeUnit.MILLISECONDS));
}
static class Person implements Delayed {
@Override
public long getDelay(TimeUnit unit) {
// 这个对象的过期时间
return 100L;
}
@Override
public int compareTo(Delayed o) {
//比较
return o.hashCode() - this.hashCode();
}
}
输出 :
queue.poll() = null
复制代码
6. LinkedTransferQueue (重点)
JDK1.7 加入的无界队列 , 亮点就是无锁实现的,性能高 .
Doug Lea 说这个是最有用的 BlockingQueue 了 , 性能最好的一个 . Doug Lea说 从功能角度来讲,LinkedTransferQueue实际上是ConcurrentLinkedQueue、SynchronousQueue(公平模式)和LinkedBlockingQueue的超集。
他的 transfer方法 表示生产必须等到消费者消费才会停止阻塞. 生产者会一直阻塞直到所添加到队列的元素被某一个消费者所消费(不仅仅是添加到队列里就完事)
同时我们知道 上面那些BlockingQueue使用了大量的 condition和 lock , 这样子效率很低 , 而LinkedTransferQueue则是无锁队列.
他的核心方法其实就是 xfer()方法 ,基本所有方法都是围绕着这个进行的 , 一般就是 SYNC ,ASYNC,NOW ,来区分状态量. 像put,offer,add 都是 ASYNC , 所以不会阻塞. 下面几个状态对应的变量.
private static final int NOW = 0; // for untimed poll, tryTransfer(不阻塞) private static final int ASYNC = 1; // for offer, put, add(不阻塞) private static final int SYNC = 2; // for transfer, take(阻塞) private static final int TIMED = 3; // for timed poll, tryTransfer (waiting) 复制代码
7.(小顶堆) 优先队列 PriorityQueue 的实现
小顶堆是什么 : 任意一个非叶子节点的权值,都不大于其左右子节点的权值
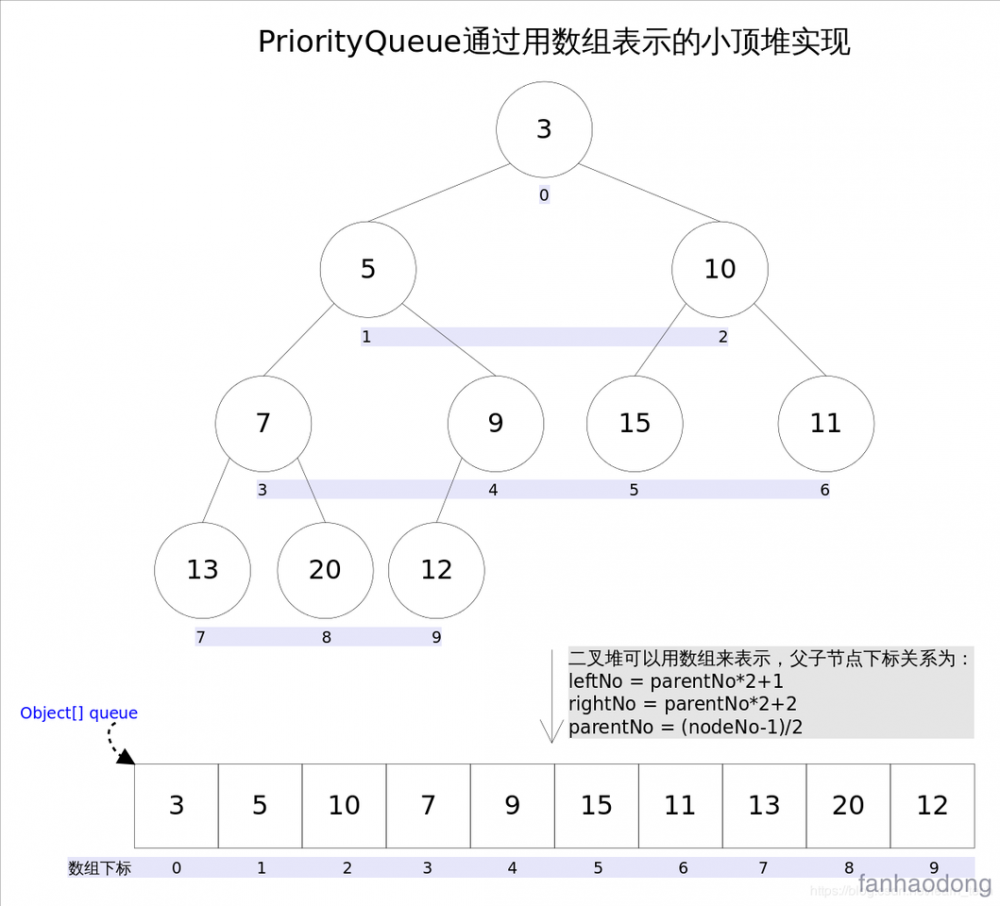
-
PriorityQueue是非线程安全的,PriorityBlockingQueue是线程安全的
-
两者都使用了堆,算法原理相同
-
PriorityQueue 的逻辑结构是一棵完全二叉树,就是因为完全二叉树的特点, 他实际存储确实可以为一个数组的, 所以他的 存储结构其实是一个数组 。
1. 首先java 中的 PriorityQueue 是优先队列,使用的是小顶堆实现
- 什么是小顶堆 (父节点,永远小于左右子节点) ,因此结果不一定是完全升序
- 什么是大顶堆 跟 小顶堆相反,
- 优先队列中 对于当offer操作,当插入的元素此时长度大于默认长度会进行数组扩容(system.copyarr()方法) 所以他其实是一个无界数列
- 所以 优先队列 是数组实现,他不需要占用太大的物理空间,而是进行了深度的排序
1. 自己实现一个大顶堆
/**
* 构建一个 大顶堆
*
* @param tree
* @param n
*/
static void build_heap(int[] tree, int n) {
// 最后一个节点
int last_node = n - 1;
// 开始遍历的位置是 : 最后一个堆的堆顶 , (以最小堆为单位)
int parent = (last_node - 1) / 2;
// 递减向上遍历
for (int i = parent; i >= 0; i--) {
heapify(tree, n, i);
}
}
/**
* 递归操作
* @param tree 代表一棵树
* @param n 代表多少个节点
* @param i 对哪个节点进行 heapify
*/
static void heapify(int[] tree, int n, int i) {
// 如果当前值 大于 n 直接返回了 ,一般不会出现这种问题 .....
if (i >= n) {
return;
}
// 子节点
int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
// 假设最大的节点 为 i (父节点)
int max = i;
// 如果大于 赋值给 max
if (c1 < n && tree[c1] > tree[max]) {
max = c1;
}
// 如果大于 赋值给 max
if (c2 < n && tree[c2] > tree[max]) {
max = c2;
}
// 如果i所在的就是最大值我们没必要去做交换
if (max != i) {
// 交换最大值 和 父节点 的位置
swap(tree, max, i);
// 交换完以后 , 此时的max其实就是 i原来的数 ,就是最小的数字 ,所以需要递归遍历
heapify(tree, n, max);
}
}
// 交换操作
static void swap(int[] tree, int max, int i) {
int temp = tree[max];
tree[max] = tree[i];
tree[i] = temp;
}
复制代码
8.常用的几个方法
- offer 添加一个元素并返回true 如果队列已满,则返回false
- poll 移除并返问队列头部的元素 如果队列为空,则返回null
- peek 返回队列头部的元素 如果队列为空,则返回null
- put 添加一个元素 如果队列满,则阻塞 BlockQueue特有的
- take 移除并返回队列头部的元素 如果队列为空,则阻塞 (像队头移除一个元素,并且整体向前移动,保证对头不为空) BlockQueue特有的
5. Stack
栈结构属于一种先进者后出,类似于一个瓶子 , 先进去的会压到栈低(push操作) , 出去的时候只有一个出口就是栈顶 , 返回栈顶元素,这个操作称为pop ,
1. Stack类
stack 继承自 Vector , 所有方法都加入了 sync 修饰, 使得效率很低 ,线程安全.
@Test
public void testStack() {
Stack<Integer> stack = new Stack<>();
// push 添加
stack.push(1);
stack.push(2);
// pop 返回栈顶元素 , 并移除
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
}
输出 :
2 , 1
复制代码
2. 通过LinkedList 实现
但是LInkedList很好的实现了这个 , 同时他是个线程不安全的类.
@Test
public void testStack() {
LinkedList<Integer> stack = new LinkedList<>();
stack.push(1);
stack.push(2);
System.out.println("stack.pop() = " + stack.pop());
System.out.println("stack.pop() = " + stack.pop());
}
输出
2 , 1
复制代码
正文到此结束
- 本文标签: 总结 并发 tar 删除 IDE CTO 高并发 快的 equals db build cat GitHub queue 消息队列 HashMap 测试 final zab http 数据 空间 id list ArrayList node 同步 线程 Google 线程池 实例 线程同步 java 锁 连接池 https DDL UI 时间 Collection value LinkedList tab dubbo 递归 数据库 多线程 文章 Select 工程师 volatile synchronized git src map 需求 IO key ConcurrentHashMap unix 百度 HashSet swap API ACE 遍历 模型 开发 构造方法 ip lib 安全 代码 深度学习 Collections HashTable 源码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

