谈JVM内存问题分析总结03(200403)

大家可以看到最近几天我一直在写JVM内存问题分析内容总结,因为整个问题诊断和分析过程做到每天完整的思考内容,假设和验证内容的记录,对于日后的问题分析来说是有参考价值的。对于前面已经整理过的内容,包括问题出现的场景,初步的问题分析等我不再赘述,而是仅仅整理和总结最近一天的关键思考点。
内存持续增长和溢出根源点
对于引起内存持续增长和溢出根源点,在我们对内存数据进行jmap dump分析后,已经可以明显的看到具体的问题根源点在于java.io.file对象实例的不断初始化上面。再展开点来说,就是线程Thread-0,这是一个后台线程,这个线程会找到我们的control临时文件目录,并对这个目录里面的所有临时文件进行读取,并初始化java.io.file对象实例,从数据观察这个对象实例初始化了解决1000万个,而且内存无法回收,导致内存溢出。
因此我们解决方法是对Control临时文件目录和临时文件进行清理,这个本质上是没有问题的。但是当前Control临时目录下本身就上万个临时目录,上千万的临时文件数据,清理进展很缓慢。
对于根源点的进一步分析
在上面的基本解决方法下,我们进一步分析。即究竟是什么东西会启动Thread-0这个后台线程,对Control临时目录和临时文件进行大量读取。
应用层面是否存在定时任务和调度
因此我们进一步假设是否有相关的定时作业和调度任务在做这个事情。因此进一步查询MFT的资料,发现了在MFT里面刚好有一个Purge Schedule定时清扫的调度任务。即这个Purge调度任务可以定时的对过期的临时文件,老的任务实例数据进行清除,以提升MFT整体性能。
对于Purge Schedule,在环境初始化的时候会有一个Default Purge Schedule的默认配置。
但是我们进一步观察这个默认配置,里面有两个关键的参数,一个是每天都会定时处理一次,同时清扫的内容是7天以前过期的老数据。但是问题又出来了,我们观察了下在测试环境这个默认调度是激活状态的,但是在生产环境下,这个默认调度本身是InActive的,也就是这个任务本身就没有激活。如果没有激活,那么这个任务也没有实际运行过,也看不到具体的运行时间。
即Purge Schedule在定时清扫导致的临时文件和目录大量读取,看起来并不成立。
在这个之后,我们进一步思考,数据库层面是否存在定时任务
是否会是数据库本身有定时调度作业在处理。因此我们查看数据库是否有定时运行的任务和Job,刚好发现了数据库实际上建立了6个物化视图,这6个物化视图会每分钟都刷新一次。而且这6个视图本身的数据量也不小,已经到了几十万的数据量。
MV_MFT_PAYLOAD_INFO
MV_MFT_SOURCE_INFO
MV_MFT_SOURCE_MESSAGE
MV_MFT_TARGET_INFO
MV_MFT_TRANSFER
MV_MFT_TRANSFER_COUNT_INFO
Materialized views refresh every 1 minute. If there is a heavy load on the database server, you may want to increase the refresh frequency from 1 minute. You can view data from materialized views on the MFT console. If a high load is observed on the database server, this refresh frequency can be adjusted by using the following command:
ALTER MATERIALIZED VIEW <<MV_NAME>> REFRESH NEXT <<REFRESH_INTERVAL>>;
这几个物化视图可以看到,实际是对MFT传输实例数据进行进一步的汇总和统计,初步看下Sql语句是按小时进行汇总,包括传输的数据量,传输的实例数等信息。如果是按小时去汇总,为何要做到每分钟都去刷新物化视图。虽然从物化视图的创建来看采用的是Fast增量刷新机制,但是现在数据量刷新物化视图仍然应该是一个相当耗费资源的操作。
其次,对于物化视图这么频繁的刷新,本身还导致一个问题就是大量的redo日志生成,这个redo日志的产生量相当大,而这种Redo日志本身也造成很多的存储和归档压力。
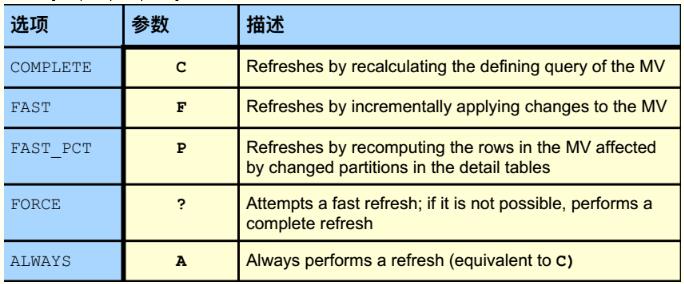
Complete:全部刷新 。相当于重新执行一次创建视图的查询语句。
Fast: 增量刷新 .假设前一次刷新的时间为t1,那么使用fast模式刷新物化视图时,只向视图中添加t1到当前时间段内,主表变化过的数据.为了记录这种变化,建立增量刷新物化视图还需要一个物化视图日志表。create materialized view log on (主表名)。(多张表时,此语句也生效,创建后,原来的表中会多出两类视图表:MLOG$_table_name和RUPD$_table_name)
Force: 这是默认刷新方式。当可以使用fast模式时,数据刷新将采用fast方式;否则使用complete方式。
一个表上存在物化视图日志和基于物化视图日志快速刷新的物化视图,如果对这个表进行DML操作,则Redolog产生量将翻数倍,并且执行时间加长,影响并发操作。
因此基于这点,我们可以考虑采用两个行动步骤,一个是对源表的历史数据进行清理,一个是调整物化视图的运行频率。现在按小时汇总完全没有必要太频繁的去运行。
对于内存Dump文件的进一步分析
重新回到问题本身,即最终的问题还是为何会启动Thread-0后台线程,这个线程大量的去读取Control临时目录和临时文件,由于临时目录和文件的数据量巨大,导致了内存溢出。
解决方法是对临时目录和文件进行清理。同时另外一个路径就是为何应用要去读这个临时目录和文件,究竟是什么定时任务和作业导致去读这个临时目录和文件。而这个问题本身又出现两个分支。
其一:我们假设MFT应用或数据库存在定时任务,按这个假设去排查。
其二:能否还是回归到Dump文件本身,从Dump文件的线程和堆栈信息能够分析出具体的代码点。
所以可以看到,实际我昨天仍然花了大量的时间在用MAT内存分析工具,不断的对内存分析结果,Thread类的调用income和outcome数据进行分析,但是仍然没有得到一个有用的结果。当然也可能是我们对MAT工具本身不熟悉,也可能是这个程序和代码本身不是自己写的,很难从分析代码中马上看到问题点。
那么是否还有其它的类似MAT工具,在网上搜索发现了一款商用工具,又免费的试用期。
https://www.yourkit.com/
因此今天准备再用这个商用工具进一步对我们Dump出来的内存文件进行分析和诊断,看下是否能够有一些新的收获和问题发现。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

