从使用到原理,探究Java线程池
什么是线程池
当我们需要处理某个任务的时候,可以新创建一个线程,让线程去执行任务。线程池的字面意思就是存放线程的池子,当我们需要处理某个任务的时候,可以从线程池里取出一条线程去执行。
为什么需要线程池
首先我们要知道不用线程池,直接创建线程有什么弊端:
-
第一个是创建与销毁线程的开销,Java中的线程是映射到操作系统线程上的,频繁地创建和销毁线程会极大地损耗系统的性能。
-
线程会占用一定的内存空间,如果我们在同一时间内创建大量的线程执行任务,很有可能出现内存不足的情况。
为了解决这两个问题我们引入线程池的概念,通过复用线程避免重复创建销毁线程带来的开销,同时可以设置最大线程数,避免同时创建大量线程导致内存溢出。
线程池的使用
1.线程池的核心参数
想掌握线程池首先要理解线程池构造函数的参数:
| 参数名 | 类型 | 含义 |
|---|---|---|
| corePoolSize | int | 核心线程数 |
| maxPoolSize | int | 最大线程数 |
| keepAliveTime | long | 保持存活时间 |
| workQueue | BlockingQueue | 任务存储队列 |
| threadFactory | ThreadFactory | 当线程池需要新创建线程的时候,会通过ThreadFactory创建 |
| Handler | RejectedExecutionHandler | 当线程池无法接受你提交的任务时所采取的拒绝策略 |
逐个解释这些参数是很难理解的,这里我结合一张线程池处理的流程图进行讲解:
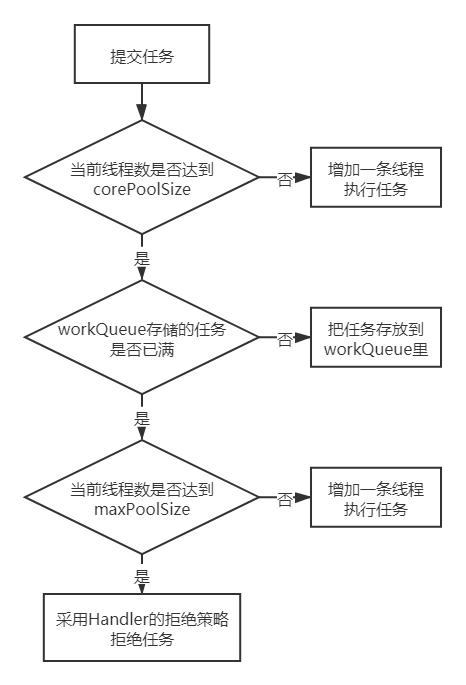
当我们往线程池里提交任务时,如果线程池内的线程数少于corePoolSize,则会直接创建新的线程处理任务;
如果线程池的线程数达到了corePoolSize,并且存储队列没满,则会把任务放到workQueue任务存储队列里;
如果存储队列也满了,但是线程数还没有达到maxPoolSize,这个时候就会继续创建线程执行任务。注意:这个时候线程池内的线程数已经超过了corePoolSize,超过corePoolSize的线程不会一直存活在线程池内,当他们闲下来时并超过keepAliveTime设定的时间后,就会被销毁。
如果线程数已经达到了maxPoolSize,这个时候如果再来任务,线程池就采取Handler所指定的拒绝策略拒绝任务。
2.几种常见的线程池分析
Java为我们提供了几种常用的线程池,通过Executors类可以轻易地获取它们。下面我们通过分析这几种常用线程池的参数,了解这些线程池之间的异同。
- newSingleThreadExecutor
从字面上也好理解,这是一个单线程的线程池,它的构造参数如下(创建的时候不需要传参,这里指的是下一层调用线程池构造函数时的传参):
corePoolSize:1
maximumPoolSize(maxPoolSize):1
keepAliveTime:0L
workQueue:LinkedBlockingQueue
其他参数为默认值
大家按照照着上面的流程图模拟提交任务走一遍,就知道为什么这是一个单线程的线程池了。
当初次任务提交的时候,会创建一个线程执行任务;当提交第二个任务的时候,由于corePoolSize值为1,所以任务会放到任务队列中。由于任务队列选择的是LinkedBlockingQueue,底层结构是链表,理论上可以存放几乎无穷多的任务(默认的大小是Integer.MAX_VALUE),所以永远不会触发任务队列已满的条件,也就永远不会继续增加线程,所以该线程池能保持一个单线程的工作状态。
如果这个唯一的线程因为异常结束了,线程池会创建一个新的线程补上。通过阻塞队列,这个线程池能够保证任务是按顺序执行的。
- newFixedThreadPool
这是一个固定线程数的线程池,它的构造参数如下:
corePoolSize:n
maximumPoolSize(maxPoolSize):n
keepAliveTime:0L
workQueue:LinkedBlockingQueue
其他参数为默认值
如果理解了 SingleThreadExecutor 是如何限制只有一条线程执行任务的话,那这里固定线程数的原理也是一样的,关键是限定 corePoolSize 和 maxPoolSize 的大小一样,并使用几乎无限容量LinkedBlockingQueue
- newCachedThreadPool
可缓存的线程池,我理解的缓存是关于线程的缓存,它的构造参数如下:
corePoolSize:0
maximumPoolSize(maxPoolSize):Integer.MAX_VALUE
keepAliveTime:60L
workQueue:SynchronousQueue
其他参数为默认值
由于corePoolSize为0,所以任务提交到该线程池后会直接到阻塞队列。又由于阻塞队列采用的是SynchronousQueue,这是一种不存储任务的队列,一旦获得任务它就会分发给任务处理线程,所以直接触发流程图中第三个判断框:如果当前线程数小于maxPoolSize就创建线程。由于maxPoolSize设置了一个很大的值,基本上可以无限地创建线程,具体的数量取绝于JVM所能创建的最大线程数。若线程空闲60秒没任务处理便会被线程池回收。
该线程池在处理大量异步短链接任务的时候有较好的性能,在空闲的时候池内是没有线程的,节省了系统的资源。
- newScheduledThreadPool
corePoolSize:自定义
maximumPoolSize(maxPoolSize):Integer.MAX_VALUE
keepAliveTime:0
workQueue:DelayedWorkQueue
其他参数为默认值
由于maxPoolSize设置为Integer.MAX_VALUE,该线程池可以无限创建线程,由于阻塞队列选择了DelayedWorkQueue,所以可以周期性地执行任务。
- newWorkStealingPool
这个是JDK1.8新加入的线程池,底层使用的是ForkJoinPool。如果使用默认参数创建的话,该线程池能够创建足够多的线程以达到和系统相匹配的并行处理能力。每个线程都有自己的工作队列,如果当前线程工作完了,它会到别的工作队列中“窃取”任务执行,充分地利用了CPU的多核能力。
阿里巴巴关于创建线程池的约规
下面这段话搬运自阿里巴巴Java开发手册,相信大家看完上面的参数解释以及各种线程池的异同后,就不难理解这段约规了:
(六)并发处理
4. 【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,避免资源耗尽的风险。
说明:Executors返回线程池的弊端如下:
1) FixedThreadPool和SingleThreadPool:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2) CacheThreadPool和ScheduledThreadPool:
允许创建的线程数量为Integer.MAX_VALUE,可能会创建大量的线程,导致OOM。
3. 线程池的数量设置为多少比较合适?
这个问题是没有固定答案的,我们可以先通过业界权威给出的公式计算线程池的数量,然后通过压测进一步确认具体的数量。
业界给出的指导公式是:
-
若任务是CPU密集型任务(比如说加密,计算哈希等),线程数可以设置为CPU核心数的1-2倍左右。
-
若任务是耗时IO型任务(比如说读写数据库,文件,网络等),线程数的公式为:线程数 = CPU核心数 * (1 + 平均等待时间 / 平均处理时间)
这两种不同设计都遵循着尽力压榨CPU性能的原则。
4. 线程池的五种状态
线程池的五种状态都写在了ThreadPoolExecutor类中了,它们分别是:
- RUNNING:接受新任务,并处理新任务
- SHUTDOWN:不接受新任务,但是会处理队列中的任务
- STOP:不接受新任务,不处理队列中的任务,中断正在处理的任务
- TIDYING:所有任务已经结束,workerCount为零,这时线程会转到TIDYING状态,并将运行terminated()钩子方法
- TERMINATED:terminated()运行完成
5. 线程池运行的原理
我们先回顾一下如何新创建一个线程处理任务,看懂了再看线程池的原理就简单了:
//首先把我们要放在线程里运行的代码在Runnable接口实现类的run方法中封装好
class MyTask implements Runnable {
@Override
public void run() {
System.out.println("处理任务 + 1");
}
}
//然后创建一个线程,把该Runnable接口实现类作为构造参数传给线程
public class Basic {
public static void main(String[] args) {
Thread thread = new Thread(new MyTask());
thread.start();
}
}
//最后调用线程的start方法运行,实际上调用的是Runnable的run方法
在上面的代码中,实现了Runnable接口的实例传入到线程类中,成为了线程对象的一个成员变量,线程运行的时候会调用该实例的run方法。
可以看到如果新创建一个线程来执行任务,任务会和线程耦合在一起。而线程池的关键原理在于它添加了一个阻塞队列,把任务和线程解耦了
在线程池中,有一个worker的概念,这个概念解释起来有点困难,你可以直接理解为worker就是一个线程工人,它手上拿着任务,当调用线程池的runWorker()方法时,线程就会处理一个任务,详细见下面代码
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {//会到阻塞队列中获取任务
w.lock();
//...
try {
//执行任务
} finally {
//...
w.unlock();
}
}
//...
} finally {
//...
}
}
从代码中可以看到线程池的关键代码就是一个while循环,在while循环中会不断地向阻塞队列中获取任务,获取到了任务就执行。
参考:
- 慕课网《玩转Java并发工具,精通JUC,成为并发多面手》课程
- https://www.oschina.net/question/565065_86540
- https://www.cnblogs.com/dolphin0520/p/3932921.html
- https://www.cnblogs.com/ok-wolf/p/7761755.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

