深入拆解Tomcat&Jetty(七)
- 1.安装JDK,配置环境变量
- 2.下载Tomcat并解压
- 3.执行tomcat/bin目录下的start.sh 执行脚本后的流程
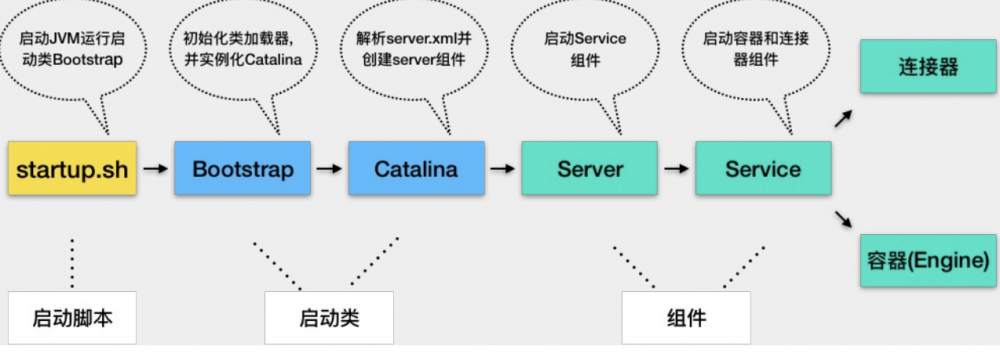
- 1. Tomcat本质上还是一个Java程序,因此startup.sh脚本会启动一个JVM来运行Tomcat的启动类BootStrap
其实Tomcat和我们自己平时写的代码并没有本质上的区别,只是Tomcat的启动时通过脚本.我们常用的SpringBoot或简单的Java类可以通过java命令启动.
- 2.BootStrap主要任务是初始化Tomcat的
类加载器,创建Catalina. - 3.Catalina会解析server.xml,创建响应的组件,并调用Server.start
- 4.Server负责管理Service,调用Service.start
- 5.Service会管理顶层容器Engine,调用Engine.start
经过这几步Tomcat启动就算完成了.
Tomcat比作公司
- Catalina:公司创始人,负责组件团队,创建Server以及它的子组件
- Server:公司的CEO,管理多个事业群,每个事业群是一个Service
- Service:事业群总经理,管理两个职能部门,
对外市场部:连接器,对内的研发部:容器 - Engine:研发部总经理,作为最顶层的容器组件
Catalina
Catalina主要任务就是创建Server,解析 server.xml ,将server.xml定义的各个组件创建出来,然后调用Server的init和start方法
public void start() {
//1.获取Server,如果为空进行创建
if (getServer() == null) {
load();
}
//2.创建失败直接报错退出
if (getServer() == null) {
log.fatal(sm.getString("catalina.noServer"));
return;
}
long t1 = System.nanoTime();
// 3.启动Server
try {
getServer().start();
} catch (LifecycleException e) {
log.fatal(sm.getString("catalina.serverStartFail"), e);
try {
getServer().destroy();
} catch (LifecycleException e1) {
log.debug("destroy() failed for failed Server ", e1);
}
return;
}
long t2 = System.nanoTime();
if(log.isInfoEnabled()) {
log.info(sm.getString("catalina.startup", Long.valueOf((t2 - t1) / 1000000)));
}
// 创建Tomcat关闭的钩子
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since
// shutdown hooks run in parallel and log messages may be lost
// if JULI's hook completes before the CatalinaShutdownHook()
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
false);
}
}
//监听Tomcat停止请求
if (await) {
await();
stop();
}
}
复制代码
Hook :钩子,Tomcat中的关闭钩子是用于在JVM关闭时做一些清理工作,比如将缓存数据刷到磁盘,或者清理临时文件呢. Hook 本质上是一个线程,JVM在停止之前会尝试执行这个线程的run方法.
Catalina的关闭钩子
protected class CatalinaShutdownHook extends Thread {
@Override
public void run() {
try {
if (getServer() != null) {
//其实只是调用了stop方法
Catalina.this.stop();
}
} catch (Throwable ex) {
ExceptionUtils.handleThrowable(ex);
log.error(sm.getString("catalina.shutdownHookFail"), ex);
} finally {
//略...
}
}
}
}
复制代码
Catalina的关闭Hook中,只是调用了内部的 stop 方法,最终也是通过Server的stop和destory方法进行资源释放和清理.
Server
Server组件的实现类是 StandardServer ,继承自 LifeCycleBase ,生命周期被统一管理,它的子组件是Service,因此需要对Service的生命周期进行管理.
- 在启动时调用Service组件的start方法
- 停止是调用Service组件的stop方法
Server添加Service组件
public void addService(Service service) {
service.setServer(this);
synchronized (servicesLock) {
Service results[] = new Service[services.length + 1];
System.arraycopy(services, 0, results, 0, services.length);
results[services.length] = service;
services = results;
if (getState().isAvailable()) {
try {
service.start();
} catch (LifecycleException e) {
// Ignore
}
}
// Report this property change to interested listeners
support.firePropertyChange("service", null, service);
}
}
复制代码
可以看到Server通过一个数组持有所有Service的引用,同时这个数组默认长度是0,只有在每次新增Service组件时候会创建新的数组,长度为原数组长度+1,然后将原数组的数据复制到新数组中,并且使用的是 System.arraycopy() 的Native方法,避免数组的自动1.5倍扩容浪费内存空间.
除了管理Service组件外,Server还有一个重要功能,就是启动一个Socket监听停止端口, 就是平常使用shutdown.sh脚本就能停止的原因 .
其实在Catalina启动的最后,有一个 await 方法,这个方法就是调用了Server#await,在Server#await方法中会创建一个Socket对关闭进行监听,在一个死循环中监听来自8005端口的数据(关闭端口模式就是8005),收到 SHUTDOWN 指令后就会退出循环,进入stop的流程.
Service
Service的具体实现是 StandardService .StandardService继承LifeCycleBase,并且会持有Server,Connector,Engine,Mapper等组件.
public class StandardService extends LifecycleBase implements Service {
//Server实例
private Server server = null;
//连接器数组
protected Connector connectors[] = new Connector[0];
private final Object connectorsLock = new Object();
//对应的Engine容器
private Engine engine = null;
//映射器及其监听器
protected final Mapper mapper = new Mapper();
protected final MapperListener mapperListener = new MapperListener(this);
复制代码
其中MapperListener的作用是支持动态部署,监听容器变化将信息更新到Mapper中.
在Service的启动方法中,维护了子组件的生命周期,在各种组件启动的时候,组件有个字的启动顺序
protected void startInternal() throws LifecycleException {
if(log.isInfoEnabled())
log.info(sm.getString("standardService.start.name", this.name));
//1.触发启动监听
setState(LifecycleState.STARTING);
//2.启动Engine,由Engine启动其子容器
if (engine != null) {
synchronized (engine) {
engine.start();
}
}
//略...
//启动Mapper监听
mapperListener.start();
//最后启动连接器
synchronized (connectorsLock) {
for (Connector connector: connectors) {
// If it has already failed, don't try and start it
if (connector.getState() != LifecycleState.FAILED) {
connector.start();
}
}
}
}
复制代码
由组件启动顺序可以看出,Service先启动了Engine,然后是Mapper监听器,最后才启动连接器.
因为只有对内的组件都启动好了,才能启动对外服务的组件,这样才能保证连接后不会因为内部组件未初始化完成导致的问题.所以停止的顺序就会和启动时刚好相反
Engine
Engine具体实现类是 StandardEngine 本质是一个顶层容器,所以会继承自 ContainerBase ,实现Engine接口.
但是由于Engine是顶层的容器,所以很多功能都抽象到 ContainerBase 中实现. 通过HashMap持有所有子容器Host的引用.
protected final HashMap<String, Container> children = new HashMap<>(); 复制代码
当Engine在启动的时候,会通过专门的线程池启动子容器
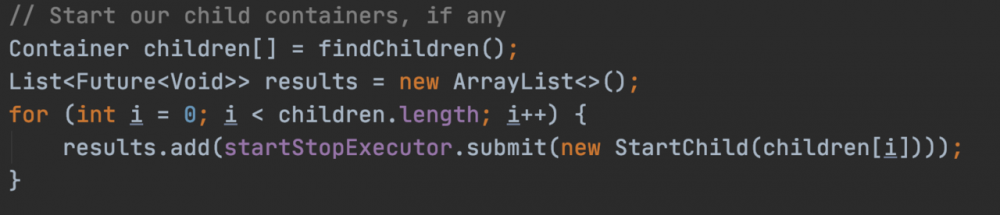
Engine容器最重要的功能其实就是将请求转发给Host进行处理,具体是通过pipline-Valve实现的.
在Engine的构造函数中,就已经将Pipline-Valve的第一个基础阀设置好了
/**
* Create a new StandardEngine component with the default basic Valve.
*/
public StandardEngine() {
super();
//设置第一个基础阀
pipeline.setBasic(new StandardEngineValve());
//..略
}
复制代码
StandardEngineValve
在创建Engine时,就会默认创建一个 StandardEngineValve ,用于连接Host的Pipline,并且在 Mapper 组件中已经对请求进行了路 由处理,通过URL定位了相应的容器,然后把容器对象保存在 Request 对象中,所以StandardEngineValve就能开始整个调用链路.
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// Select the Host to be used for this Request
Host host = request.getHost();
if (host == null) {
// HTTP 0.9 or HTTP 1.0 request without a host when no default host
// is defined. This is handled by the CoyoteAdapter.
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(host.getPipeline().isAsyncSupported());
}
// Ask this Host to process this request
host.getPipeline().getFirst().invoke(request, response);
}
复制代码
正文到此结束
- 本文标签: 管理 本质 实例 http tomcat 配置 mapper CEO 类加载器 REST java 线程池 tar Bootstrap bug Select ask servlet 安装 Service 空间 synchronized list spring Listeners IDE springboot 解析 src jetty map Property 创始人 JVM value 目录 下载 https 数据 id App 部署 Java类 端口 cat message 代码 HashMap XML 生命 ip UI IO CTO 缓存 final ssl 线程 监听器
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

