HashMap源码分析(I)
HashMap作为我们经常使用的集合,我们除了熟练的使用它,更应该掌握其具体的实现原理(JDK1.8)。关于HashMap是个啥,我这里就不讲述了。
总览
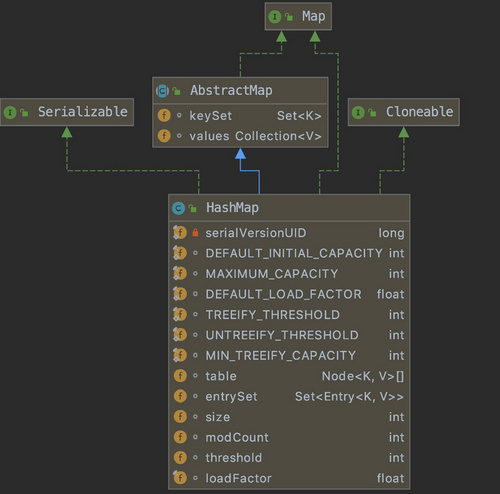
从上图中我们可以看出HashMap的父类以及一些属性。下面我抽取其中几个关键的属性进行说明:
transient Node<K,V>[]
存储K-V数据的结构体,可以看出这是一个数组( bucket ),关于HasMap,我们会根据Key值计算一个索引即该K-V存储在数组位置中,当随着数据增多,会有不同的key会被存储在bucket相同的位置,在HasMap中解决冲突主要有两种方式:
- 链表
- 红黑树
该字段被标记为transient,表明不可被序列化,关于hashmap的序列化和反序列化我们后面会讲到,这里不过多提及。
链表
看一下HashMap中链表的数据结构。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
从上述的定义,基于链表的实现主要有以下几个字段:
- hash:bucket位置,也就是key的hash值
- key:Key
- value:Value值
- next:链表中的下一个,如果该K-V为链表中的最后一个,那么该值为null
红黑树
看一下HashMap中红黑树的数据结构,关于树的相关内容,我会单独开一篇文章写,这里就不过多讲述了。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
从上述的定义,基于红黑树的实现主要有以下几个字段:
- parent:父节点
- left:左节点
- right:右节点
- prev:上一个节点
- read:是否是红黑树的标记
Set<Map.Entry<K,V>> entrySet
缓存了所有的K-V节点
size
k-v的数量
threshold
当k-v的数量达到threshold,默认值是DEFAULT_INITIAL_CAPACITY(16),当经历过一次扩容以后,该值的计算规则是capacity * load factor(当前容量*负载因子)
loadFactor
负载因子,默认值是0.75,该默认值平衡性能和存储空间,在实际使用中不建议修改。增大该值,会降低空间开销但是会增大查询成本(受影响的操作主要有get和put方法)。
DEFAULT_INITIAL_CAPACITY
HashMap默认的初始化容量,默认值16,初始化的容量可以在HashMap被初始化时进行指定,但是必须是2的幂。
MAXIMUM_CAPACITY
默认的最大容量(2的30次方),HashMap的最大容量也可以在初始化时进行指定,但指定的值必须在2的幂并且小于等于2的30次方
DEFAULT_LOAD_FACTOR
默认的负载因子0.75
TREEIFY_THRESHOLD
由于JDK1.8HashMap引入了红黑树,当同一个bucket中的链表长度过长时数据结构会被替换成红黑树,这个长度的阀值就是由TREEIFY_THRESHOLD控制的,默认值为8
UNTREEIFY_THRESHOLD
当HashMap的key被移除时,会动态计算同一个bucket中的数量,当数量低于某个值时,那么数据结构会由红黑树再转化会列表。
MIN_TREEIFY_CAPACITY
上面两个属性用来控制同一个bucket中节点数量过多时会进行树状化,这个属性是用来控制当bucket的容量超过该值时强制进行树状化。
构造方法
public HashMap() {}
public HashMap(int initialCapacity) {}
public HashMap(int initialCapacity, float loadFactor) {}
public HashMap(Map<? extends K, ? extends V> m) {}
HashMap的构造方法主要有上面三种,我们主要看第三种:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
首先会check参数的正确性(初始化容量、负载因子),check完参数以后会设置负载因子,以及下一次扩容时HashMap中k-v的数量。下面看一下tableSizeFor方法
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
解释一下上面一些特殊运算符的含义
- |=:|=相当于 a= a | b
- |:位运算,按位或,只有左右都为0才位0,否则为1
- >>>:无符号右移,左边补0,右移N位,相当于除以2的N次方
在计算扩容的size时是HashMap在JDK1.8的一次性能优化,上述代码虽然很复杂,但最终功能是获得hash桶(bucket)的数量,假设指定的cap不是2的幂,那该方法获得的是比cap大的最小的2的幂。
首先分析一下 >>> 的作用并且为什么只右移到16位,首先我们返回的值是int,位数为32位。下面假设我们的n为01XX..XXX
- n |= n >>> 1:首先右移一位以后001X..XXX,然后再或之后赋值给n,那么n的情况就是011X..XXX,那么n现在前面肯定有2个1
- n |= n >>> 2:首先右移两位以后0000..XXX,然后再或之后赋值给n,那么n的情况就是01111..XXX,那么n的前面肯定有4个1
下面依次类推,右移4位以后,n前面有8个1,右移8位以后,n前面有16个1,当右移16位以后,n前面就有32个1,因此对于32位的整形数字数字来说,右移16位就够了,
最后再将结果+1,就变成2的幂了。
那么为什么先要将cap进行-1呢?原因是防止cap本身就是2的幂,如果cap本身就是2的幂不减1得到的数量将会有问题。
下节预告
后面我们会讲述HashMap的关键方法,比如get、put以及扩容等。欢迎关注公众号

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

