学习 MyBatis 的一点小总结 —— 底层源码初步分析
目录
- MyBatis 如何获取数据库源?
- MyBatis 如何获取 sql 语句?
- MyBatis 如何执行 sql 语句?
- MyBatis 如何实现不同类型数据之间的转换?
在过去程序员使用 JDBC 连接数据库,总会带来诸多不便。MyBatis 是一款优秀的持久层框架,可以替代 JDBC 帮助我们更好的进行开发。要了解 MyBatis 的实现原理,首先我们要明白 MyBatis 的大致操作步骤。

数据库源告诉我们连接哪个数据库,获得要执行的SQL语句,再进行操作,这点者缺一不可。接下来要看的就是这三点在底层如何实现。
MyBatis 如何获取数据库源?
使用 Mybatis 第一步肯定是要写好配置文件。官方给出的指导文档告诉我们,XML 配置文件中包含了对 MyBatis 系统的核心设置,包括获取数据库连接实例的数据源。
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<!-- 我们要获取的数据库源信息在这里 -->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
</configuration>
想要连接数据库,必然要获得数据源信息。既然上述配置文件有数据库源信息,那我们只要进行解析就好了。
String resource = "org/mybatis/example/mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
由代码可见,我们要的是一个 SqlSessionFactory 实例,SqlSessionFactory 里面就有我们所需的数据库源信息。通过new SqlSessionFactoryBuilder().build(inputStream) 返回SqlSessionFactory 实例,进入 build 方法。
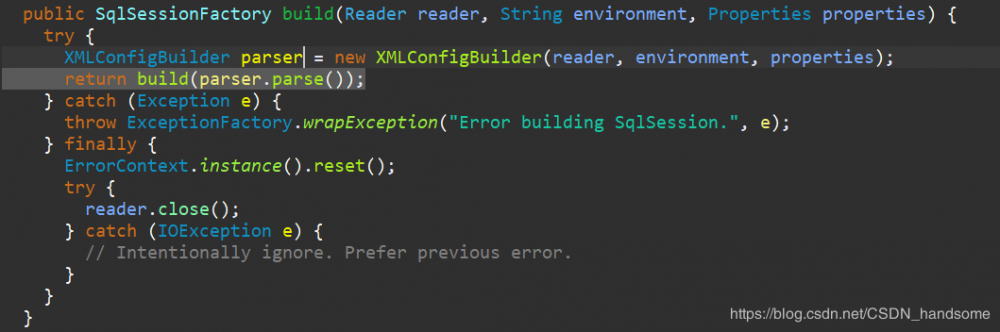
build 方法返回值就是是 SqlSessionFactory,注意到有 return build(parser.parse()),关注点在 parser.parse(),进入 parse 方法。
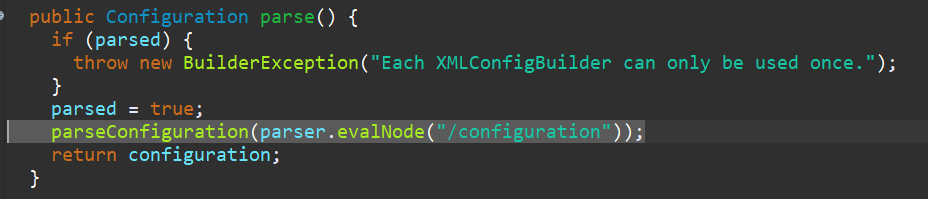
parse 方法返回 Configuration 。parsed 是一个布尔类型成员变量,默认值是 false,作判断的目的是为了防止多线程情况下该方法被二次调用。 这个方法返回一个 Configuration 类型的实例,Configuration 是 BaseBuilder 类的一个成员变量,Configuration 其实保存了配置文件所有的信息,只是现在还是一张白纸,需要再操作一番 。进入 parseConfiguration 方法。
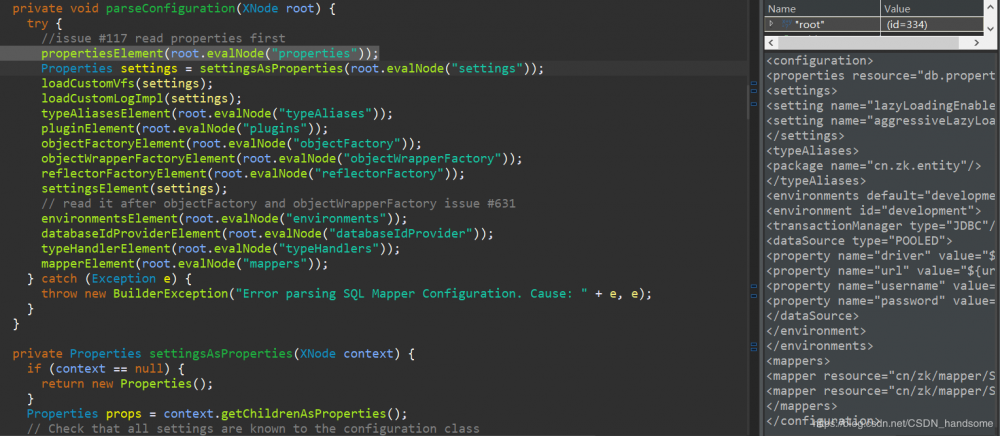
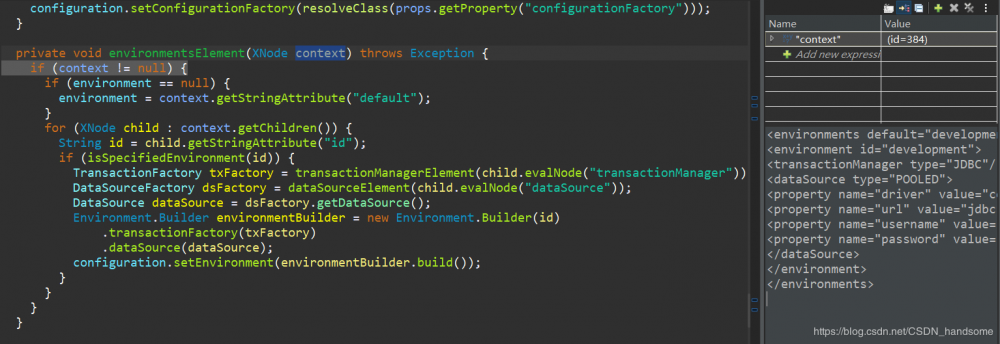
上一张图的 parse.evalNode 方法将配置文件中 configuration 标签下的内容进行解析,封装到一个对象,这个对象作为参数传入 parseConfiguration 方法中。在 parseConfiguration 方法我们见到了很多熟悉的字样,诸如 properties、typeAliases 之类的配置信息,但我们的目的是要拿到数据库源信息,因此我们把目标放在包裹了数据库源信息的 environments 标签上,进入 environmentsElement 方法。
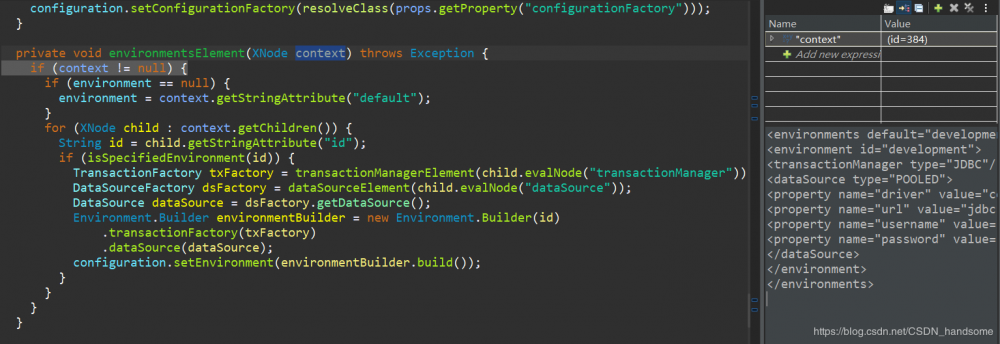
作为参数的 context 对象与之前一样,封装了 environments 标签中的内容,我们还需要进一步解析 dataSource 标签,关注 DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource")) 这段代码,进入dataSourceElement 方法。

到这里 context 对象只有 dataSource 里的内容了。发现 type 的值为 POOLED(默认值),props 保存最终的数据库配置信息。DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance() 这一段代码,进入 resolveClass 方法,最终再跳转 resolveAlias 方法中。
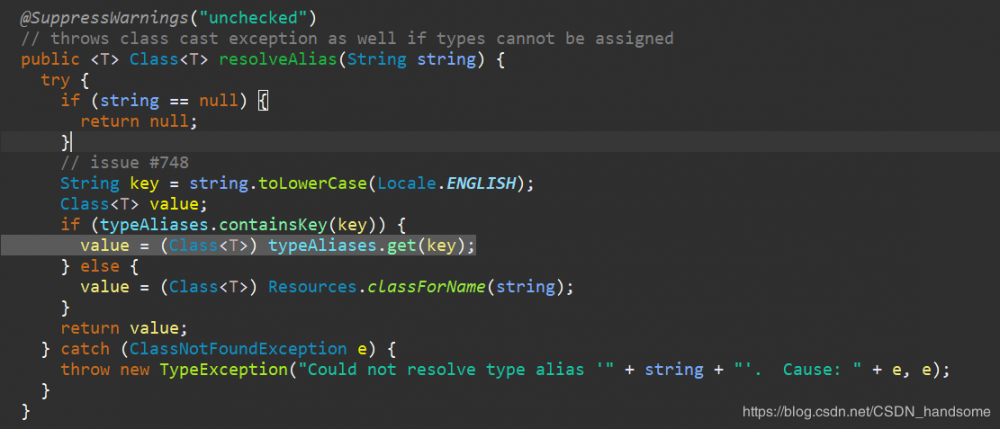
注意 value = (Class


) typeAliases.get(key),typeAliases 实际上是一个 HashMap,将 POOLED 作为 key 得到了保存的对应的 Class 类型。回到 dataSourceElement 方法。
得到返回的 Class 返回值,利用反射 newInstance 创建对应的 DataSourceFactory 对象,set 方法保存 props ,回到 environmentsElement 方法。
继续执行后面的方法,最终数据库源信息封装到一个 Environment 类型的实例,这个实例又通过 set 方法保存到了 configuration 。configuration 已经处理就绪,被 parse 方法返回。回到之前的 build 方法,将 configuration 作为参数传入至另一个重载的 build 方法。
SqlSessionFactory 本身是一个接口,DefaultSqlSessionFactory 则是实现了 SqlSessionFactory 的实现类,保存好 configuration 之后返回,就得到了我们开头需要的 SqlSessionFactory 实例。
MyBatis 如何获取 sql 语句?
与获取数据库源类似,只要解析 Mapper 配置文件中的对应标签,就可以获得对应的 sql 语句。之前我们讲过,SqlSessionFactory 中的 configuration 属性保存数据库源信息,事实上这个 configuration 属性将整个配置文件的信息都给封装成一个类来保存了。解析的前半部分与之前一样,分歧点在之前提到的 parseConfiguration 方法,其中在 environmentsElement 方法下面还有一个 mapperElement 方法。
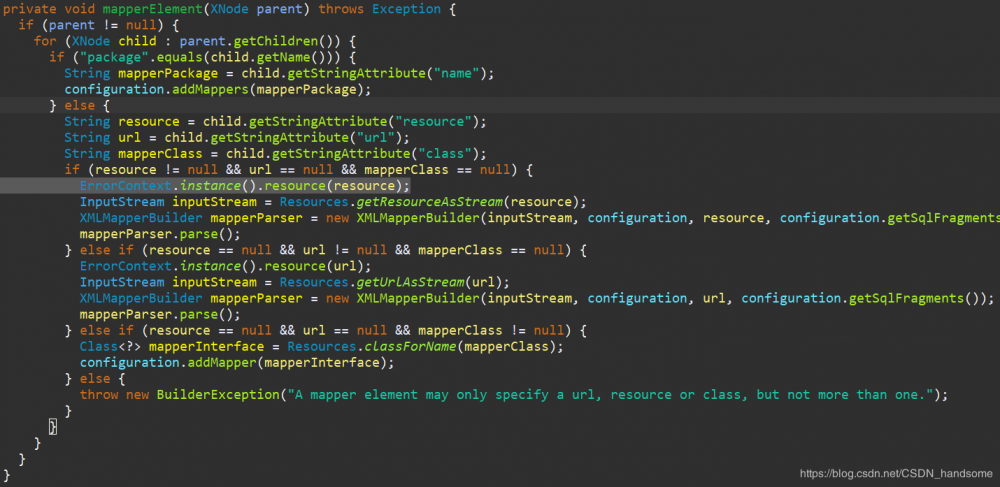
配置文件中 mappers 标签加载mapper文件的方式共有四种:resource、url、class、package。代码中的 if-else 语句块分别判断四种不同的加载方式,可见 package 的优先级最高。parent 是配置文件中 mappers 标签中的信息,通过外层的循环一个一个读取多个 Mapper 文件。这里使用的方式是 resource ,所以会执行光标所在行的代码块,进入 mapperParser.parse() 方法。
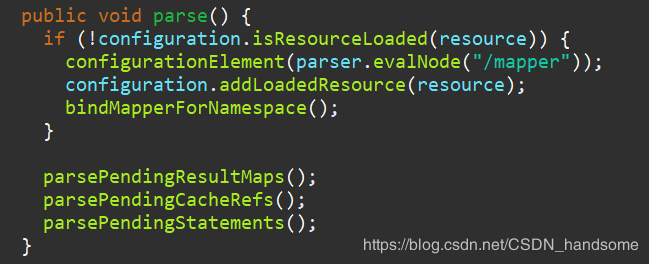
我们要的是 mapper 标签的内容,因此我们关注 configurationElement(parser.evalNode("/mapper")) 这一句,进入 configurationElement 方法。
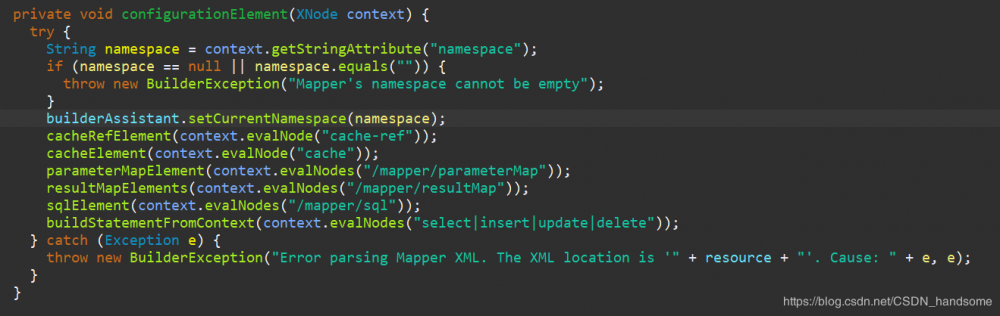
context 就是我们解析整个 Mapper 文件 mapper 标签中的内容,既然现在得到了内容,那只需再找到对应的标签就能获得sql语句了。注意 buildStatementFromContext(context.evalNodes("select|insert|update|delete")),我们看到了熟悉的 select、insert、update、delete,这些标签里就有我们写 sql 语句。进入 buildStatementFromContext 方法。
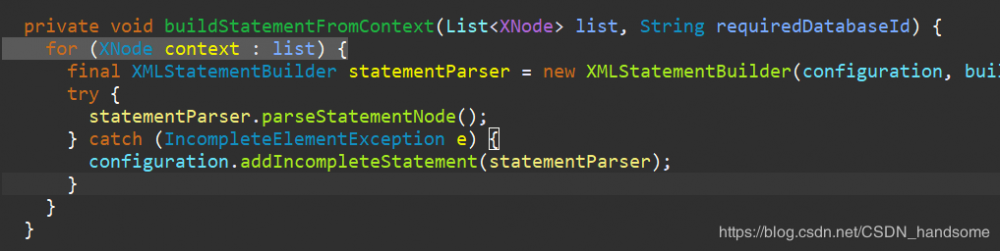
list 保存了我们在 Mapper 文件中写的所有含有 sql 语句的标签元素,用一个循环遍历 list 的每一个元素,分别将每一个元素的信息保存到 statementParser 中。进入 parseStatementNode 方法。
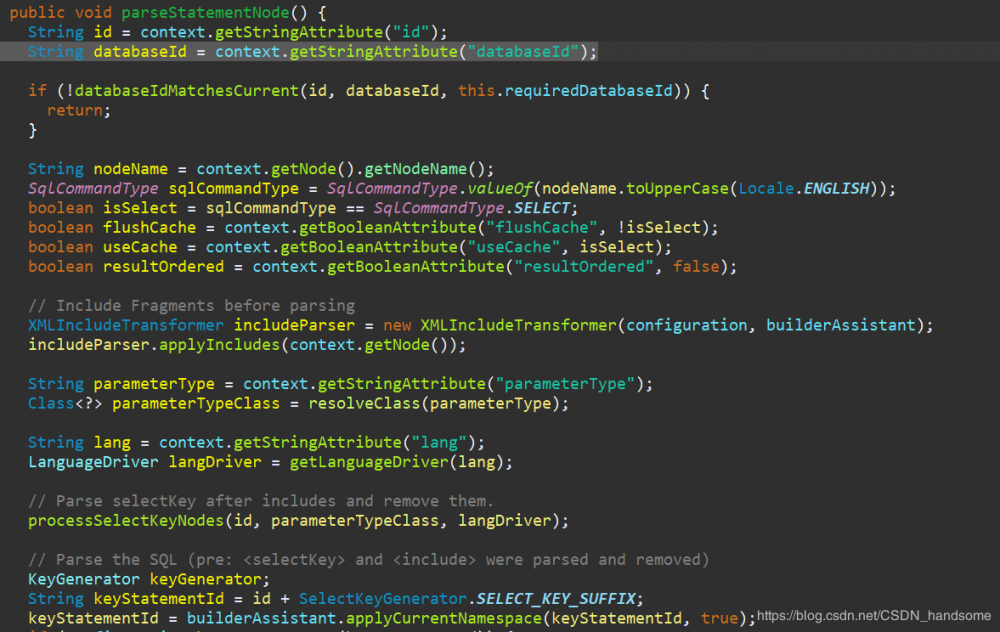

这个方法代码内容很多,仅摘出节选,里面定义了很多局部变量,这些变量用来保存sql语句标签(例如 )的参数信息(例如缓存 useCache)。再把所有参数传到 addMappedStatement 中。进入 addMappedStatement 方法。
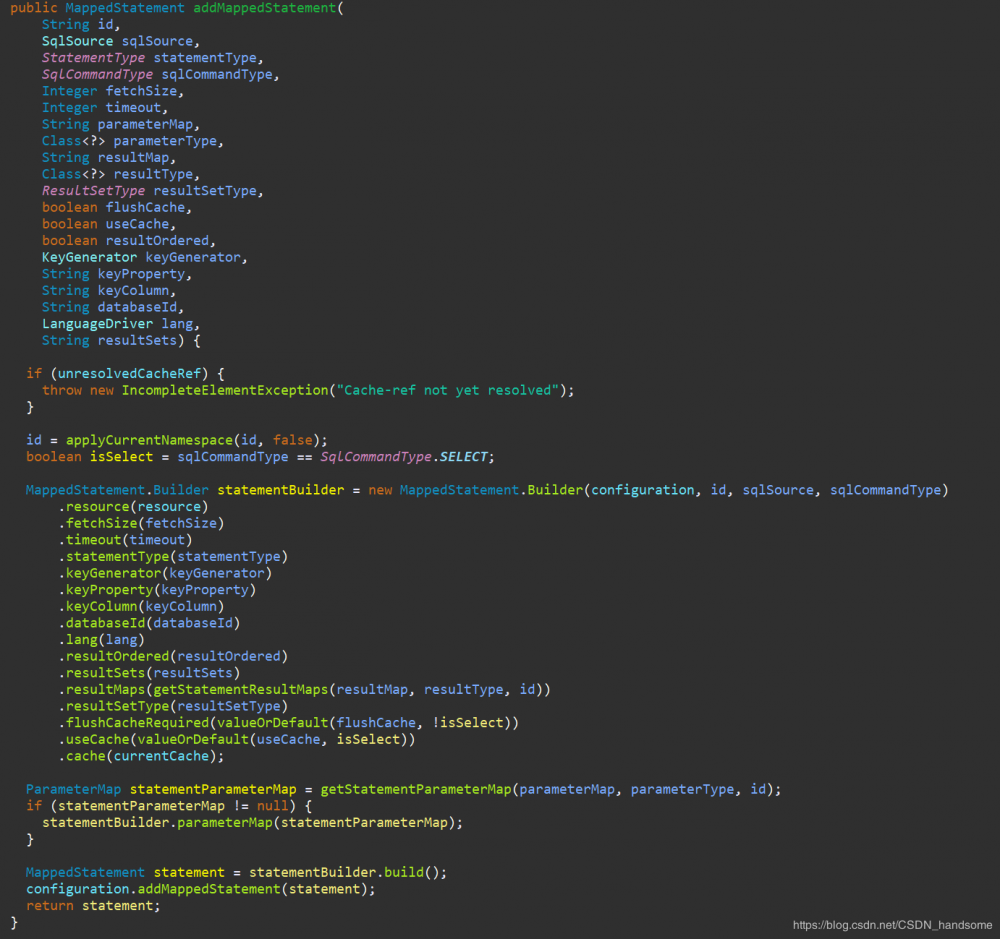
MappedStatement statement = statementBuilder.build(),使用 build 方法得到 MappedStatement 实例,这个类封装了每一个含有sql语句标签中所有的信息,再是 configuration.addMappedStatement(statement),保存到 configuration 中。
MyBatis 如何执行 sql 语句?
既然有了 SqlSessionFactory,我们可以从中获得 SqlSession 的实例。开启 session 的语句是 SqlSession session = sessionFactory.openSession(),进入 openSession 方法。
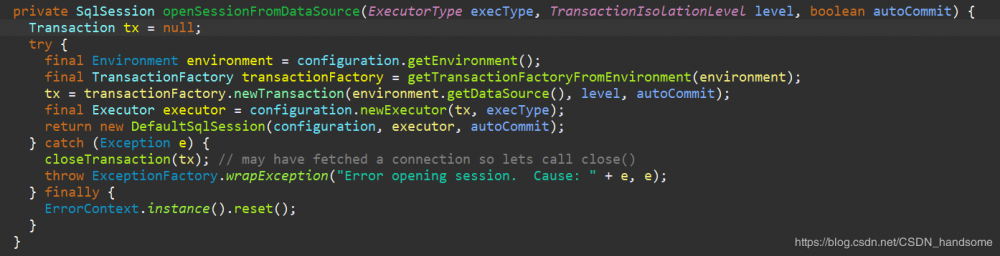
最终会执行 openSessionFromDataSource 方法。在之前 environment 已经有了数据库源信息,调用 configuration.newExecutor 方法。
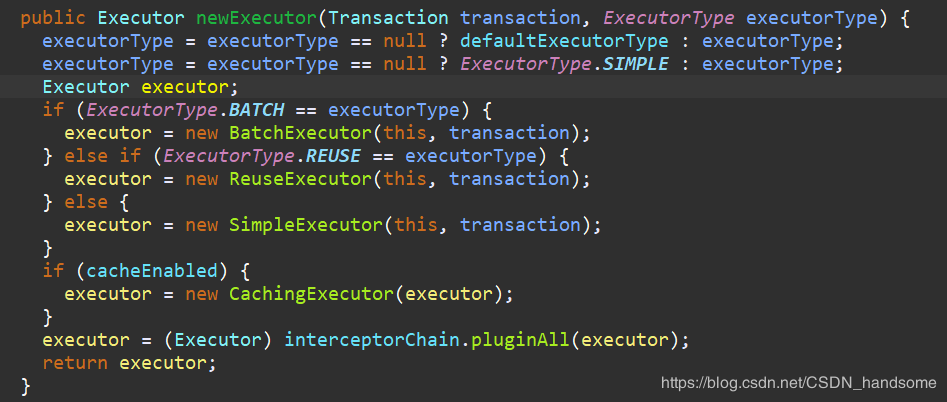
Executor 叫做执行器,Mybatis 一共有三种执行器,用一个枚举类 ExecutorType 保存,分别是 SIMPLE,REUSE,BATCH,默认就是 SIMPLE。if-else 语句判断对应的类型,创建不同的执行器。在代码末端处有个 if 判断语句,如果 cacheEnabled 为 true,则会创建缓存执行器,默认是为 true,即默认开启一级缓存。
回到 openSessionFromDataSource 方法,最终返回一个 DefaultSqlSession 实例。得到 session 我们就可以执行 sql 语句了。SqlSession 提供了在数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句,以 selectOne 方法为例,进入该方法后发现,最终会调用到 selectList 方法。
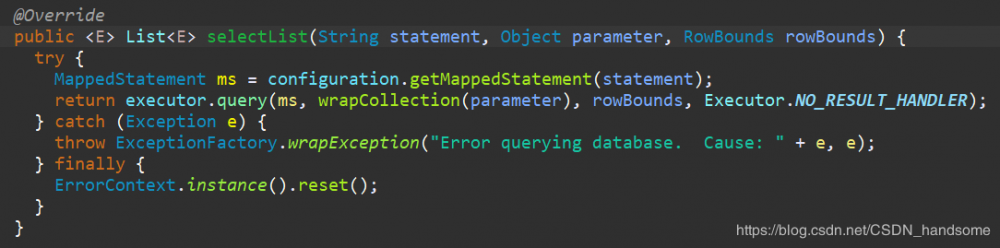
configuration.getMappedStatement(statement) 得到了我们之前保存的 MappedStatement 对象,再调用 executor.query 方法,调用 query 方法之前会执行 wrapCollection 方法,保存 sql 语句中用户传入的参数。进入 query 方法。

boundSql 里面就有我们要执行的 sql 语句,CacheKey 是用来开启缓存的。执行父类 BaseExecutor 中的 createCacheKey 方法,通过 id,offsetid,limited,sql 组成一个唯一的 key,调用下一个 query 方法。

Cache cache = ms.getCache() 是二级缓存,二级缓存为空,直接调用 query 方法。
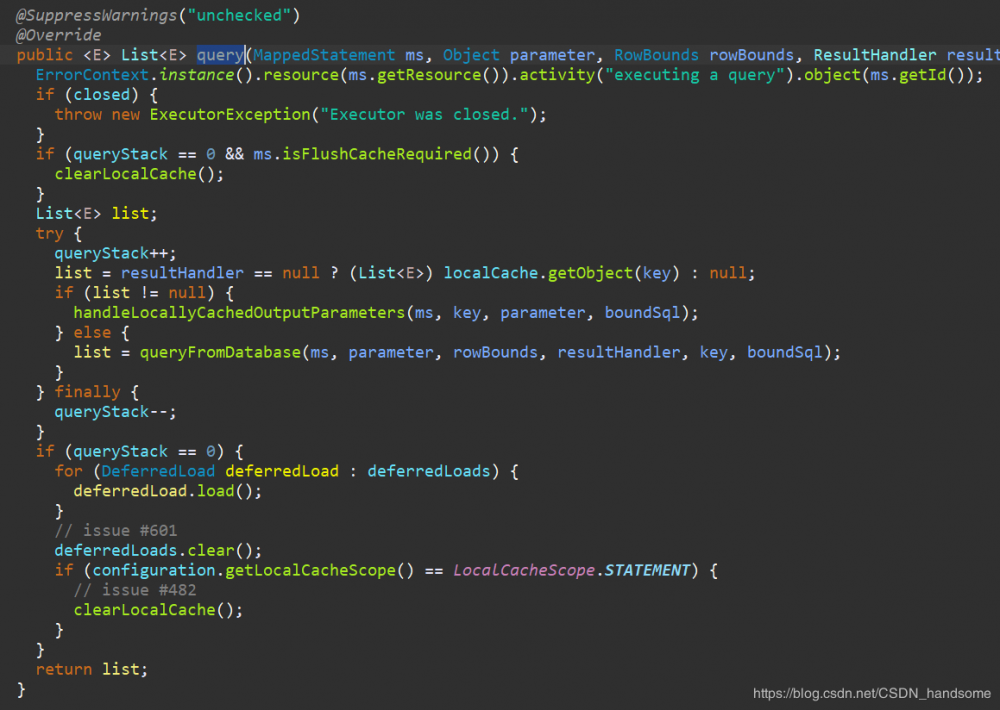
list = resultHandler == null ? (List
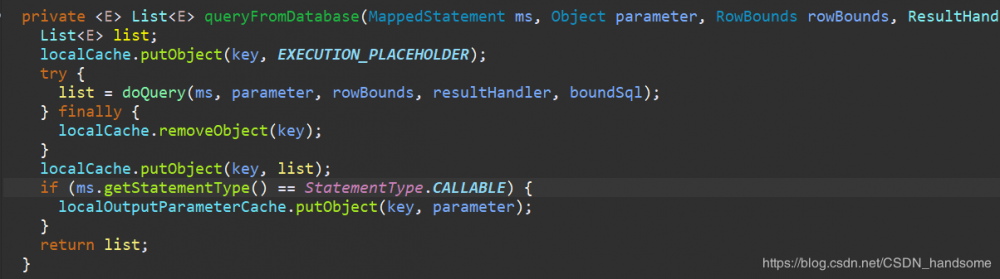


) localCache.getObject(key) : null 传入 key 值在本地查询,如果有返回证明 key 已经缓存到本地,直接从本地缓存获取结果。否则 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql),去数据库查询。
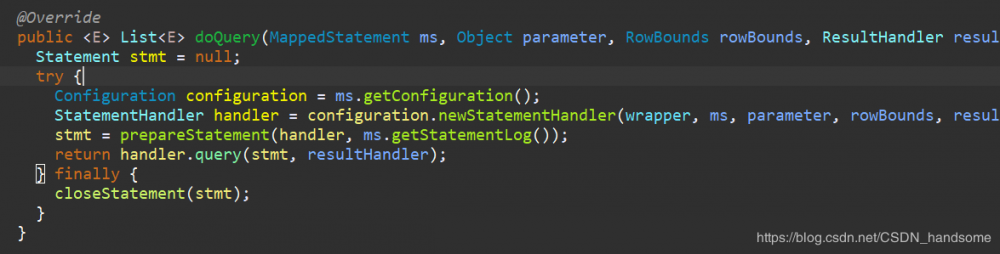
localCache.putObject(key, EXECUTION_PLACEHOLDER) 首先将 key 缓存至本地,下一次查询就能找到这个 key 了。进入 doQuery 方法。
stmt = prepareStatement(handler, ms.getStatementLog()),得到一个 Statement。进入 prepareStatement 方法。
我们看到了一个熟悉的 Connection 对象,这个就是原生 JDBC 的实例对象。回到 doQuery 方法,进入 handler.query(stmt, resultHandler) 方法。
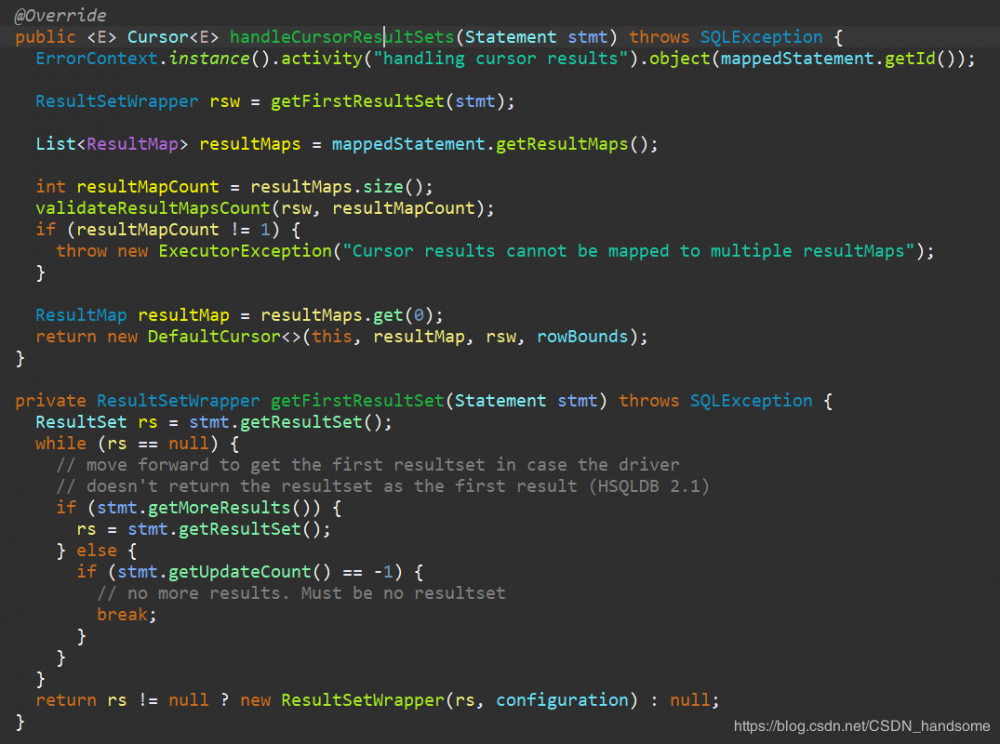
statement 强转型为 PreparedStatement 类型,这下我们又得到了 PreparedStatement 的类型实例了,调用 execute 方法,这个方法也是属于原生 JDBC。执行完成后 return resultSetHandler.handleCursorResultSets(ps),进入 handleCursorResultSets 方法。
ResultSetWrapper rsw = getFirstResultSet(stmt),看到 getFirstResultSet 方法中的 ResultSet rs = stmt.getResultSet(),在这里我们得到了 ResultSet 实例对象,最终 return rs != null ? new ResultSetWrapper(rs, configuration) : null,返回最终结果集。
MyBatis 如何实现不同类型数据之间的转换?
进入上一张图中 ResultSetWrapper 中可以看到,其中包含三个成员变量 columnNames、classNames、jdbcTypes,三者都是 ArrayList 集合。看一下构造方法。
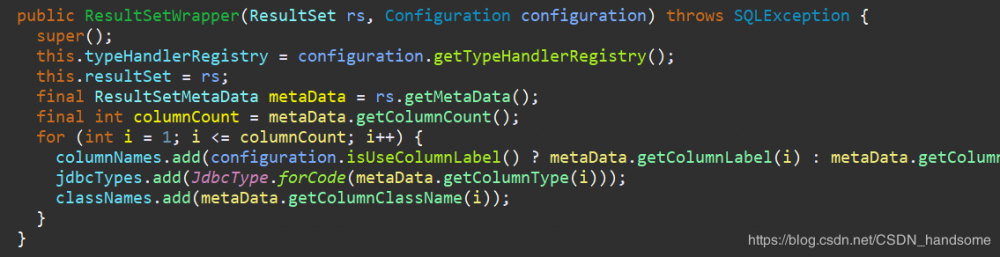
final ResultSetMetaData metaData = rs.getMetaData(),metaData 就是数据库相关的数据,getColumnCount 统计有多少个字段,循环加入到 columnNames、jdbcTypes、classNames。columnNames 保存的就是实体类中的属性名,jdbcTypes 保存的是字段在数据库中的数据类型,classNames 保存的是字段在 Java 中的数据类型,比如 Java 的 String 与数据库 VARCHAR,MyBatis 充当一个中介完成转换,真正实现 ORM 的核心思想。
正文到此结束
- 本文标签: 代码 Select 参数 src SqlSessionFactoryBuilder IO JDBC update 线程 多线程 parse mybatis build ORM 一级缓存 构造方法 java 数据库 NSA 遍历 REST example Action 二级缓存 ArrayList 目录 数据 解析 list Connection Property executor session https UI HTML value dataSource ACE cache HashMap stream db 配置 程序员 key 总结 Word sqlsession id 缓存 node map App XML final http mapper MQ ResultSet tab CTO 实例 开发 统计 SqlSessionFactory Collection Statement 源码 sql
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

