Java|使用WebMagic进行电话爬取
欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列文章。
1 什么是 WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于 WebMagic ,可以快速开发出一个高效、易维护的爬虫, 原生开发方式核心很简单,功能性给简单性让步 。可以通过 maven 导入相关依赖,如下:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
也可以直接下载相关的jar并导入使用,具体步骤原理这里就不一一赘述了。
2 框架简单解读
在前一篇文章里,教学了直接普通的去拿到想要的东西,这里开始就使用webmagic框架,其可以简化爬虫的开发流程,让开发者专注于逻辑功能的开发。
首先介绍一下其相应的四个组件及其功能,分别是:Pageprocessor(负责解析页面), Scheduler (负责管理待出去的 URL ), Pipeline (负责抽取结果处理,做持久化到数据库操作), Downloader (负责从网上下载页面)。下面是用一个图的直观介绍:
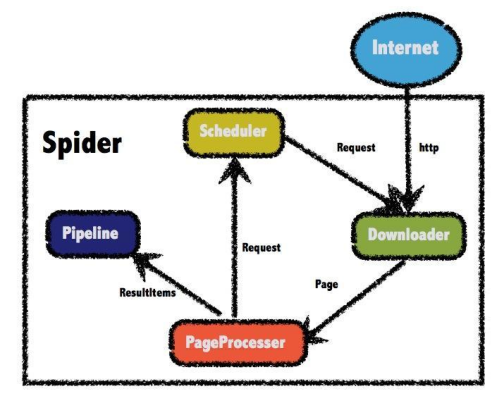
图1 组件介绍
3 代码步骤
接下来就开始代码的书写,而且在最后还有完整的代码及注释供大家参考,在这里需要的暂时只有 PageProcessor 组件,所以直接让类去实现:
implements PageProcessor
首先书写爬取的相关配置:
private Site site =
Site.me().setCharset("utf-8").setTimeOut(10000).setRetrySleepTime(3).setSleepTime(1000);
@Override
public Site getSite() { return site; }
然后创建一个线程作为入口:
public static void main(String[] args) {
Spider.create(new GetPhoneNumber())
.thread(1)
.addUrl("http://www.taohaoma.com/mobile/number?p=1&order=")
.run();
}
接着就是重点的爬取逻辑:
@Override
public void process(Page page) {
Selectable url = page.getUrl();
if (url.regex("http://www.taohaoma.com/mobile/number//?p=//d&order=").match()){
Html html = page.getHtml();
List<String> list = html.xpath("[@id='f12']/table/tbody/tr/td[1]/a/text()").all();
downPhoneNumber(list);
}
}
最后就是需要写一个保存到本地的方法,如下:
public void downPhoneNumber(List<String> list){
File file = new File("H:/ 桌面 /tel2.txt");
PrintWriter pw = null;
try {
FileOutputStream fos = new FileOutputStream(file);
pw = new PrintWriter(fos,true);
for (String string : list){
pw.println(string);
}
System.out.println(" 写入完毕 !");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
pw.close();
}
}
完成了这些操作,就可以爬取到需要的资源了。
4 完整代码及详细注释
完整代码及详细注释如下:
package com.yellow.java_pachong.tel2;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintWriter;
import java.util.List;
public class GetPhoneNumber implements PageProcessor {
//抓取网站的相关配置
private Site site = Site.me()
.setCharset("utf-8")//设置字符集
.setTimeOut(10000)//设置超时时间
.setRetrySleepTime(3)//设置重试次数
.setSleepTime(1000);//设置休眠时间
@Override
public Site getSite() { return site; }
//爬取逻辑
@Override
public void process(Page page) {
//通过 Downloader 下载下来的页面的 URL
Selectable url = page.getUrl();
// System.out.println(url);
//通过正则表达是去匹配是否是我们想要抓取的网页 URL ,像问号这种需要使用 / 去转义
if (url.regex("http://www.taohaoma.com/mobile/number//?p=//d&order=").match()){
//开始抓取信息
// System.out.println("匹配成功 ");// 检查是否匹配
//获取页面信息
Html html = page.getHtml();
// System.out.println(html);//检查是否拿到网页
//通过 Xpath 去解析 html , Xpath 是 w3c xslt 标准的主要元素 还是一门在 xml 文档中查找信息的语言,先定位到最近的一个 div 的 idf12 作为根部,再根据我们需要的号码一层一层下去 , 并用集合装
List<String> list = html.xpath("[@id='f12']/table/tbody/tr/td[1]/a/text()").all();
//将文件存到本地
downPhoneNumber(list);
// for (String string : list) {
// System.out.println(string);
// }//控制台遍历打印
}
}
//将爬取到的内容保存到本地
public void downPhoneNumber(List<String> list){
//创建存储位置
File file = new File("H:/桌面 /tel2.txt");
//定义流,为了可以在 finally 处,无论是否成功,都可以关流释放资源。
PrintWriter pw = null;
try {
//输出流
FileOutputStream fos = new FileOutputStream(file);
//字符流
pw = new PrintWriter(fos,true);
//向本地输出
for (String string : list){
pw.println(string);
}
System.out.println("写入完毕 !");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
//关流
pw.close();
}
}
//程序入口
public static void main(String[] args) {
//创建线程 ,addUrl 爬哪个网址, run 启动
Spider.create(new GetPhoneNumber())
.thread(1)
.addUrl("http://www.taohaoma.com/mobile/number?p=1&order=")
.run();
}
}
5 注意提醒
在书写代码时需要注意到的几个容易犯错的地方:
在书写正则表达式及一些语句时,需要考虑是否需要转义。
在写Xpath时 [@id='f12'] 里面, = 号两边不能有空格。
Xpath可以直接在网页上进行 copy ,如下图:
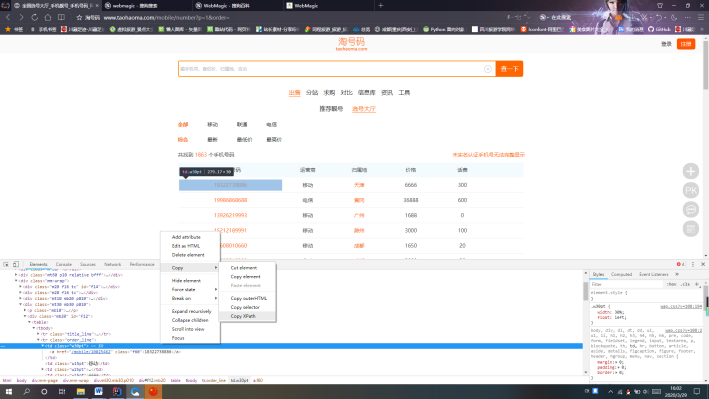
图2 copy Xpath
END
主 编 | 王文星
责 编 | 黄晓锋
where2go 团队
微信号:算法与编程之美

长按识别二维码关注我们!
温馨提示: 点击页面右下角 “写留言”发表评论,期待您的参与!期待您的转发!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

