Choerodon 的微服务之路(五):微服务的“健康保障”
本文是Choerodon 的微服务系列推文第五篇,上一篇《 Choerodon 的微服务之路(四):深入理解微服务配置中心 》介绍了配置中心在微服务架构中的作用,本篇将介绍微服务监控的重要性和必要性。
▌文章的主要内容包括:
- 为什么要监控
- 开发者需要监控哪些
- 猪齿鱼的解决方案
在前面的几期的文章里,介绍了在 Choerodon 的微服务架构中,系统被拆分成多个有着独立部署能力的业务服务,每个服务可以使用不同的编程语言,不同的存储介质,来保持最低限度的集中式管理。
这样的架构决定了功能模块的部署是分布式的,不同的业务服务单独部署运行的,运行在独立的容器进程中,彼此之间通过网络进行服务调用交互。一次完整的业务流程会经过很多个微服务的处理和传递。
在这种情况下,如何监控服务的错误和异常,如何快速地定位和处理问题,以及如何在复杂的容器拓扑中筛选出用户所需要的指标,是 Choerodon 在监控中面临的首要问题。本文将会分享 Choerodon 在微服务下的监控思考,以及结合社区流行的 Spring Cloud、Kubernetes、Prometheus 等开源技术,打造的 Choerodon 的监控方案。
为什么要监控
在谈到 Choerodon 的监控之前,大家需要清楚为什么需要微服务下的监控。
传统的单体应用中,由于应用部署在具体的服务器上,开发者一般会从不同的层级对应用进行监控。比如猪齿鱼团队常用的方式是将监控分成基础设施、系统、应用、业务和用户端这几层,并对每一层分别进行监控。如下图所示。

而在微服务系统中,开发者对于监控的关心点是一样的,但是视角却发生了改变,从分层 + 机器的视角转化为以服务为中心的视角。在 Choerodon 中,传统的分层已经不太适用。服务是部署在 k8s 的 pod 中,而不是直接部署在服务器上。团队除了对服务器的监控之外,还需要考虑到 k8s 中容器的监控。同样,由于一个业务流程可能是通过一系列的业务服务而实现的,如何追踪业务流的处理也同样至关重要。
所以在微服务中,大家同样离不开监控,有效的监控能够帮开发者快速的定位故障,保护系统健康的运行。
平开发者需要监控哪些
在 Choerodon 中,将系统的使用人员分为应用的管理人员,开发人员,运维人员。而不同的人员在平台中所关心的问题则分别不同。
- 作为应用的管理人员,需要查看到系统中各个节点实例的运行状态以及实例中应用的状态。
- 作为开发人员,需要查看自己开发的服务在运行中的所有信息,也需要跟踪请求流的处理顺序和结果,并快速定位问题。
- 作为运维人员,需要查看系统集群中服务器的 CPU、内存、堆栈等信息。需要查看K8S集群的运行状态,同时也需要查看各个服务的运行日志。
除了这些以外,还需要监控到如下的一些信息:
- 服务的概览信息:服务的名称,相关的配置等基本信息。
- 服务的拓扑关系:服务之间的调用关系。
- 服务的调用链:服务之间的请求调用链。
- 服务的性能指标:服务的CPU,内存等。
- 接口的调用监控:接口的吞吐量,错误率,响应时间等。
- 服务的日志数据:服务运行中产生的日志异常。
简而概之,对于 Choerodon 而言,开发者将监控聚焦在指标监控,调用监控和日志监控。
猪齿鱼的解决方案
在开源社区中,有很多对监控的解决方案,比如指标监控有 Prometheus,链路监控有 zipkin、pinpoint,skywalking,日志则有 elk。
Choerodon 具有多集群多环境管理能力,Choerodon 为需要监控的集群配置监控组件,并与Choerodon 所在集群的监控组件互通以及过滤多余数据,可以最大限度地减少多集群非同一局域网的外网带宽需求。在多集群环境中仍然可以感知所管理应用的运行状态和配置预警信息。
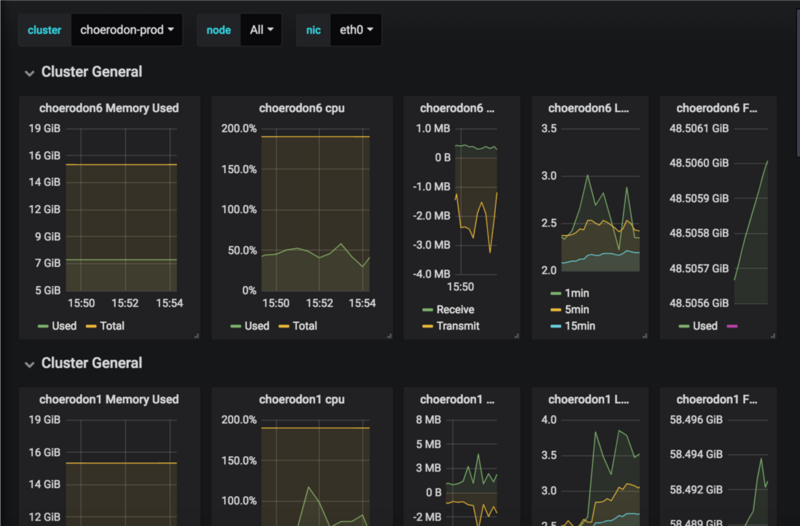
▌指标监控
Spring Boot 的执行器包含一系列的度量指标(Metrics)接口。当你请求 metrics 端点,你可能会看到类似以下的响应:
{
"counter.status.200.root": 20,
"counter.status.200.metrics": 3,
"counter.status.200.star-star": 5,
"counter.status.401.root": 4,
"gauge.response.star-star": 6,
"gauge.response.root": 2,
"gauge.response.metrics": 3,
"classes": 5808,
"classes.loaded": 5808,
"classes.unloaded": 0,
"heap": 3728384,
"heap.committed": 986624,
"heap.init": 262144,
"heap.used": 52765,
"nonheap": 0,
"nonheap.committed": 77568,
"nonheap.init": 2496,
"nonheap.used": 75826,
"mem": 986624,
"mem.free": 933858,
"processors": 8,
"threads": 15,
"threads.daemon": 11,
"threads.peak": 15,
"threads.totalStarted": 42,
"uptime": 494836,
"instance.uptime": 489782,
"datasource.primary.active": 5,
"datasource.primary.usage": 0.25
}
这些系统指标具体含义如下:
- 系统内存总量(mem),单位:KB
- 空闲内存数量(mem.free),单位:KB
- 处理器数量(processors)
- 系统正常运行时间(uptime),单位:毫秒
- 应用上下文(应用实例)正常运行时间(instance.uptime),单位:毫秒
- 系统平均负载(systemload.average)
- 堆信息(heap,heap.committed,heap.init,heap.used),单位:KB
- 线程信息(threads,thread.peak,thead.daemon)
- 类加载信息(classes,classes.loaded,classes.unloaded)
- 垃圾收集信息(gc.xxx.count, gc.xxx.time)
有了这些指标,我们只需要做简单的修改,就可以使这些指标被 Prometheus 所监测到。Prometheus 是一套开源的系统监控报警框架。默认情况下 Prometheus 暴露的metrics endpoint为/prometheus。
在项目的pom.xml文件中添加依赖,该依赖包含了 micrometer 和 prometheus 的依赖,并对监控的指标做了扩充。
<dependency>
<groupId>io.choerodon</groupId>
<artifactId>choerodon-starter-hitoa</artifactId>
<version>${choerodon.starters.version}</version>
</dependency>
Prometheus提供了4中不同的 Metrics 类型: Counter , Gauge , Histogram , Summary 。通过Gauge,Choerodon对程序的线程指标进行了扩充,添加了 NEW , RUNNABLE , BLOCKED , WAITING , TIMED_WAITING , TERMINATED 这几种类型,具体代码如下。
@Override
public void bindTo(MeterRegistry registry) {
Gauge.builder("jvm.thread.NEW.sum", threadStateBean, ThreadStateBean::getThreadStatusNEWCount)
.tags(tags)
.description("thread state NEW count")
.register(registry);
Gauge.builder("jvm.thread.RUNNABLE.sum", threadStateBean, ThreadStateBean::getThreadStatusRUNNABLECount)
.tags(tags)
.description("thread state RUNNABLE count")
.register(registry);
Gauge.builder("jvm.thread.BLOCKED.sum", threadStateBean, ThreadStateBean::getThreadStatusBLOCKEDCount)
.tags(tags)
.description("thread state BLOCKED count")
.register(registry);
Gauge.builder("jvm.thread.WAITING.sum", threadStateBean, ThreadStateBean::getThreadStatusWAITINGCount)
.tags(tags)
.description("thread state WAITING count")
.register(registry);
Gauge.builder("jvm.thread.TIMEDWAITING.sum", threadStateBean, ThreadStateBean::getThreadStatusTIMEDWAITINGCount)
.tags(tags)
.description("thread state TIMED_WAITING count")
.register(registry);
Gauge.builder("jvm.thread.TERMINATED.sum", threadStateBean, ThreadStateBean::getThreadStatusTERMINATEDCount)
.tags(tags)
.description("thread state TERMINATED count")
.register(registry);
}
▌调用监控
在微服务架构中,一个请求可能会涉及到多个服务,请求的路径则可能构成一个网状的调用链。而如果其中的某一个节点发生异常,则整个链条都可能受到影响。

针对这种情况,团队需要有一款调用链监控的工具,来支撑系统监控分布式的请求追踪。目前开源社区中有一些工具:Zipkin、Pinpoint、SkyWalking。Choerodon 使用的是 SkyWalking,它是一款国产的 APM 工具,包括了分布式追踪、性能指标分析、应用和服务依赖分析等。
Skywalking 包含 Agent 和 Collecter,具体的部署和原理在这里不在做具体的介绍,Choerodon 的服务在每个服务的 DockerFile 中,添加了对 Skywalking Agent 的支持。具体如下:
FROM registry.cn-hangzhou.aliyuncs.com/choerodon-tools/javabase:0.7.1 COPY app.jar /iam-service.jar ENTRYPOINT exec java -XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap $JAVA_OPTS $SKYWALKING_OPTS -jar /iam-service.jar
部署时通过配置容器的环境变量 SKYWALKING_OPTS 来实现客户端的配置。
▌日志监控
日志是程序在运行中产生的遵循一定格式(通常包含时间戳)的文本数据,通常由Choerodon的服务生成,输出到不同的文件中,一般会有系统日志、应用日志、安全日志等等。这些日志分散地存储在不同的容器、机器中。当开发者在排查故障的时候,日志会帮助他们快速地定位到故障的原因。
Choerodon 采用了业界通用的日志数据管理解决方案,主要包括 elasticsearch 、 fluent-bit 、 fluentd 和 Kibana 。对于日志的采集分为如下几个步骤。
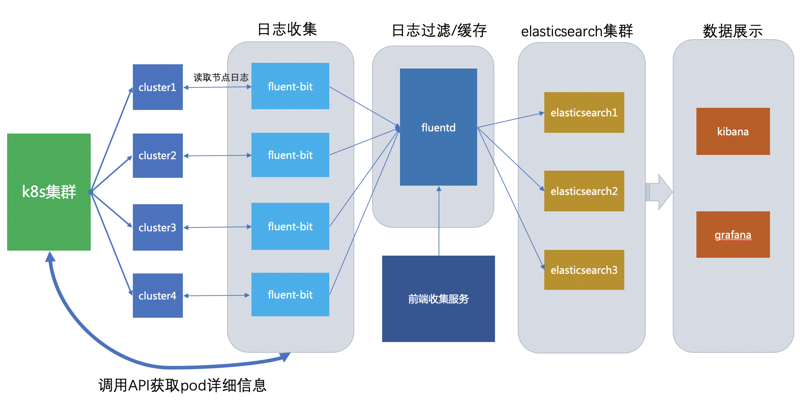
- 日志收集:通过 fluent-bit 读取 k8s 集群中 cluster 的日志,并进行收集。
- 日志过滤:通过 fluentd 将读取到的日志进行过滤,并进行缓存。
- 日志存储:将过滤后的日志存储至 elasticsearch 集群中。
- 日志展示:通过 kibana 查询 elasticsearch 中的日志数据,并用于展示。
通过端对端可视化的日志集中管理,给开发团队带来如下的一些好处:
- 故障查找:通过检索日志信息,定位相应的 bug ,找出解决方案。
- 服务分析:通过对日志信息进行统计、分析,了解服务器的负荷和服务运行状态。
- 数据分析:分析数据,对用户进行行为分析。
写在最后
回顾一下这篇文章,介绍了微服务监控的重要性和必要性,以及 Choerodon 是如何应对指标监控,调用监控和日志监控这三种监控的。微服务架构下的服务规模大,系统相对复杂,也使得众多开发者成为了微服务的受害者。如何做好微服务下的监控,保障系统健康地运行,我们仍有许多需要继续努力的。
更多关于微服务系列的文章,点击蓝字即可阅读 ▼
- Choerodon的微服务之路(一):如何迈出关键的第一步
- Choerodon的微服务之路(二):微服务网关
- Choerodon 的微服务之路(三):服务注册与发现
- Choerodon 的微服务之路(四):深入理解微服务配置中心
总结
回顾一下这篇文章,整体介绍了配置中心在微服务架构中的作用,并提出了Choerodon对于配置管理的一些心得和规范。服务配置是服务运行起来的基础,而配置中心是整个微服务技术体系中的关键基础保障,如何做好服务配置规划,并推动项目的持续交付,则是Choerodon仍需持续考虑的问题。
关于猪齿鱼
Choerodon 猪齿鱼 作为开源多云应用敏捷全链路技术平台,是基于开源技术Kubernetes,Istio,knative,Gitlab,Spring Cloud来实现本地和云端环境的集成,实现企业多云/混合云应用环境的一致性。平台通过提供精益敏捷、持续交付、容器环境、微服务、DevOps等能力来帮助组织团队来完成软件的生命周期管理,从而更快、更频繁地交付更稳定的软件。
更加详细的内容,请参阅 Release Notes 和 官网 。
大家也可以通过以下社区途径了解猪齿鱼的最新动态、产品特性,以及参与社区贡献:
- 官网: http://choerodon.io
- 论坛: http://forum.choerodon.io
- Github: https://github.com/choerodon
欢迎加入Choerodon猪齿鱼社区,共同为企业数字化服务打造一个开放的生态平台。
本篇文章出自 Choerodon猪齿鱼社区 董凡。
正文到此结束
- 本文标签: Dockerfile 微服务 云 mina 进程 IDE 实例 开源 http Spring Boot bug Agent pom 线程 数据 Kubernetes 总结 统计 id pinpoint 服务器 description 开发者 App 开发 src IO Kibana 缓存 root tar UI 时间 软件 build bean ELK JVM zip 配置 需求 组织 dataSource Service 一致性 服务注册 技术平台 java https 安全 代码 敏捷 企业 处理器 Elasticsearch 配置中心 部署 spring git 集群 GitHub XML Uber 文章 zipkin Spring cloud tag rmi ip 产品 管理 Docker 生命 分布式
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

