Prometheus水平扩展Cortex的架构分析
Cortex由Weaveworks创建,是一个开放源码的时间序列数据库和监视系统,用于应用程序和微服务。基于Prometheus,Cortex增加了水平缩放和几乎无限的数据保留。
Cortex的架构图
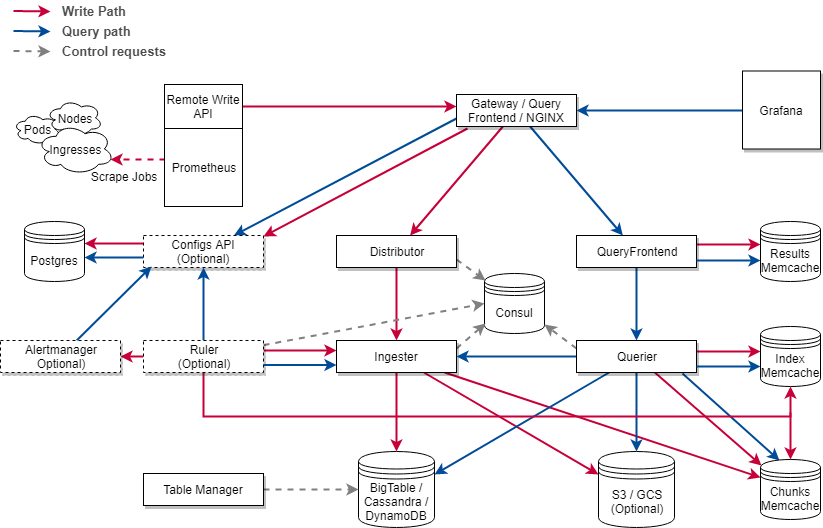
Cortex中的工作的流程如下:
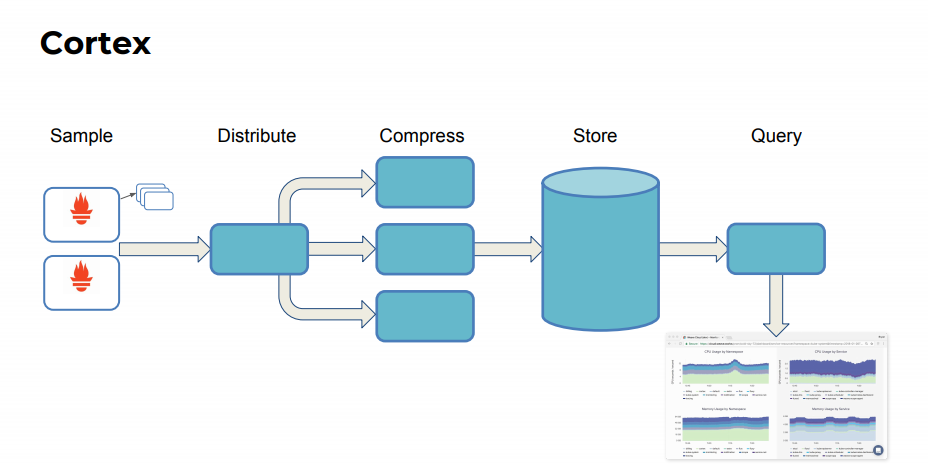
Prometheus 的作用
Prometheus 实例从各个目标中抓取样本,然后将他们推送到 Cortex 集群(直接远程写入 API)。API 本身在 Http 请求主体内发出批处理的 Snappy 压缩 Protocol Buffer (协议缓冲区)消息 PUT.
Cortex 要求每个 HTTP 请求都带有 Header 里面有 X-Scope-OrgID 字段,这是Cortex里面的租户ID.请求认证以及授权则是由反向代理 Ngnix 来进行。
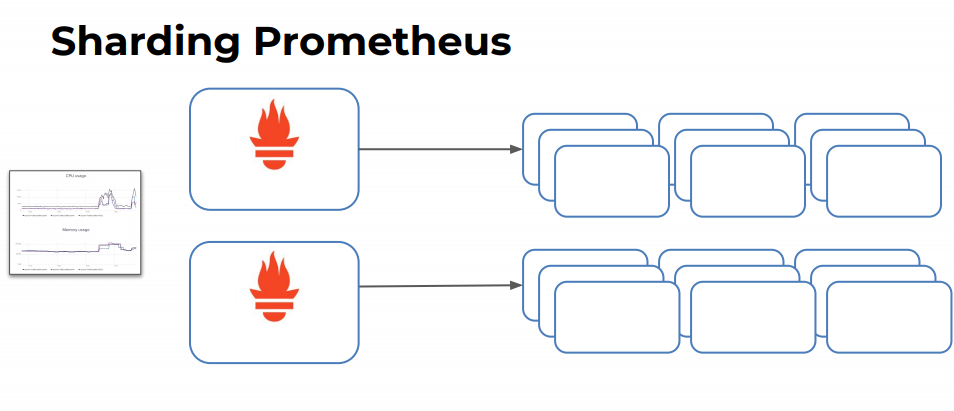
我们可以对 Prometheus 进行缩放或者分片操作:
Scaling Prometheus
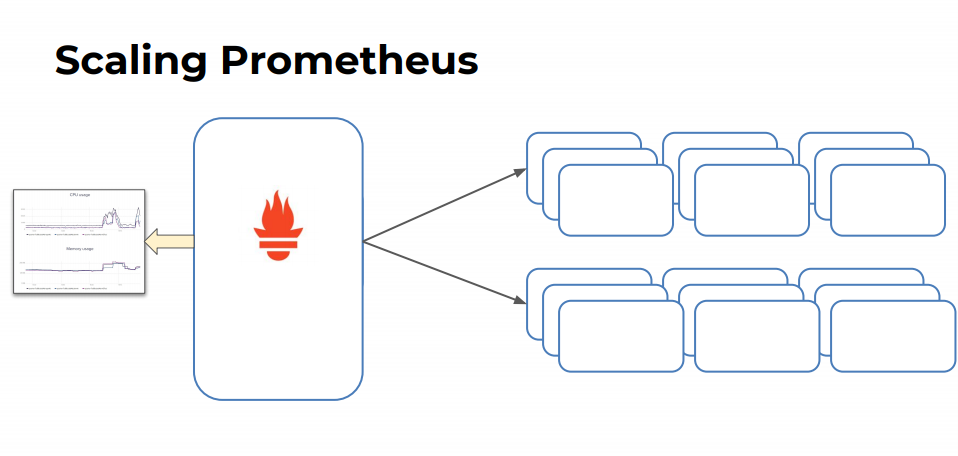
Sharding Prometheus
Storage
Cortex 当前支持两个存储引擎来存储和查询时间序列:
- Chunks(大快存储), 默认的存储引擎,稳定;
- Blocks (块存储),实验性,这个存储的方式类似与 HDFS中的Block存储
Chunks 存储
这种存储形式是将我们的单个的时间序列分别存储到 Chunk 的单独的对象里面去。每块会包含一个给定的时间段内的样本(默认是 12 h), 然后可以按照时间范围和标签对 Chunks 进行索引。
目前我们使用的快存储技术是: Apache Cassandra
在内部,对 Chunks Storge 的访问,依赖于 Chunks Store 的统一的接口,和其他的 Cortex的组件不一样的是,这个独立的接口不是一个单独的服务,而是一个嵌入在需要访问长期存储的服务中的库: ingester , querier , ruler .
目前Cortex 里面对这个 Chunk 和 index 已经版本化,这也就意味着我们可以升级我们的集群去利用新的功能。同时,该策略可更改存储格式,而无需任何停机时间或复杂的过程即可重写存储的数据。
Block 存储
这种存储方式目前还在测试阶段,它是基于 Prometheus TSDB : 将每个租户的时间序列存储到自己的 TSDB中,然后再将这个序列号写到磁盘。 Each Block is composed by few files storing the chunks and the block index.
Service
Cortex 其实是一个微服务的架构:服务体系有:
Distributor Ingester Querier Query Frontend Ruler Altermanager Config API
Distributor
这是我们处理来自 Prometheus 数据的入口。直译过来就是数据的发起者。 distributor 收到 Prometheus 的数据后,会验证每个样本的正确性并确保其在租户限制内,如果未覆盖特定租户的限制,则返回默认值。然后将有效样品数据分成几批,并并行发送至多个 ingesters 。
Distributor 需要完成的验证包括:
- The metric labels name are formally correct (指标标签名称形式正确)
- The configured max number of labels per metric is respected (遵守每个度量标准配置的最大标签数)
- The configured max length of a label name and value is respected (注意标签名称和值的最大配置长度)
- The timestamp is not older/newer than the configured min/max time range (时间戳不早于/晚于配置的最小/最大时间范围)
Distributor 是 无状态的 , 可以根据需要进行放大缩小。
High Availability Tracker
Distributor 中的 HA 跟踪器 , distributor 将对来自 Prometheus 的冗余的数据样本进行重复数据的删除。相当于是说我们拿到的 Prometheus 服务器的多个 HA 副本,将相同的数据写入 Cortex , 然后在 Distributor 里面做重复数据删除。
HA Tracker基于集群和副本标签消除传入样本的重复数据。群集标签唯一标识给定租户的冗余普罗米修斯服务器群集,而副本标签唯一标识普罗米修斯群集内的副本。如果收到的任何副本不是集群中的当前主副本,则认为传入的样本是重复的(并因此被丢弃)。
HA跟踪器需要一个键值(KV)存储来协调当前选择哪个副本。分销商将只接受当前负责人的样品。默认情况下,不带标签(副本和群集)的样本将被接受,并且永远不会进行重复数据删除。
目前支持的这个 KV 存储有:
- Consul
- Etcd
Hashing
在 Distributor 使用一致的哈希,来决定由哪个指定的 inester 来接收给定的序列。Cortex支持两种哈希策略:
- Hash the metric name and tenant ID。默认的
- Hash the metric name, labels and tenant ID。(
-distributor.shard-by-all-labels=true)
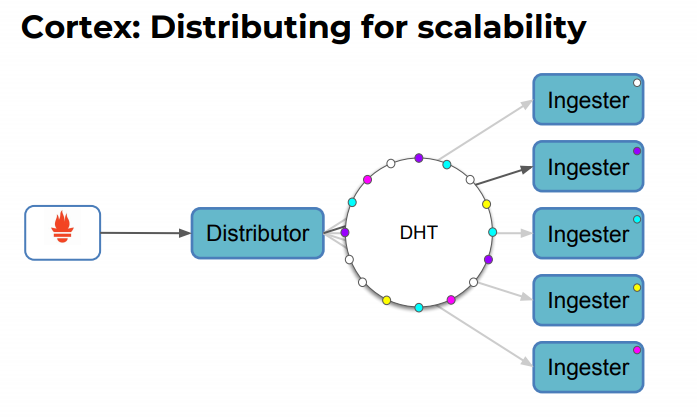
Hash Ring
hash ring 是存储在 kv store 里面的,用于实现序列分片和复制的一致哈希。每一个 Ingester 都会将自身的一个 token 注册到 这个 DHT (Distribute Hash Table)里面,这里也就是我们的 Hash Ring.
目前 Hash Ring 支持的 KV 存储包括:
- Consul
- Etcd
- Gossip memberlist(测试阶段)
Quorum Consistency
由于我们所有的 Distributors 抖共享同一个 Hash Ring , 因此任何一个请求在发送道 Distributor 前都可以在前面设置一个无状态的负载均衡。
为保持查询结果的一致性,Cortex在读/写的时候使用了 Dyname Style 的 Quorum Consistency .这意味这 在发送一个 sample 到成功响应 Prometheus 请求之前,distributor 需要等待 一半加一个 的 Ingester 的积极响应。
Ingester
ingester 主要是将接收到的序列写入到 一个长期存储的后端 (long-term storage backend) , 并返回内存中的序列用于读取路径上的查询。
接收到的序列不会立即写入到存储里面,而是保存在内存中定期刷新到存储(默认情况下:Chunks 周期是12h , Block 是 2h ),因此 queriers 在执行 读物路径的查询的时候,需要同时从 ingesters 和 long-term storge 上抓取 sample (也就是说,我要查什么东西,要从这两个地方去查)
Inester 包含一个 lifecycler ,管理着一个 ingester 的生命周期,并将 ingester state 存储在 Hash Ring 里面。 Ingester 的状态有下:
- PENDING:
- JOINING:
- ACTIVE: 当它被完全初始化。它可以同时收到它拥有的令牌的写入和读取请求。
- LEAVING:
- UNHEALTHY: 当它未能检测到环的KV存储,在此状态下,分发服务器在为传入系列构建复制集时跳过 inester,并且 inester 不会接收写入或读取请求
PENDING说明
PENDING is an ingester’s state when it just started and is waiting for a hand-over from another ingester that is LEAVING. If no hand-over occurs within the configured timeout period (“auto-join timeout”, configurable via -ingester.join-after option), the ingester will join the ring with a new set of random tokens (ie. during a scale up). When hand-over process starts, state changes to JOINING.
JOINING说明
JOINING is an ingester’s state in two situations. First, ingester will switch to a JOINING state from PENDING state after auto-join timeout. In this case, ingester will generate tokens, store them into the ring, optionally observe the ring for token conflicts and then move to ACTIVE state. Second, ingester will also switch into a JOINING state as a result of another LEAVING ingester initiating a hand-over process with PENDING (which then switches to JOINING state). JOINING ingester then receives series and tokens from LEAVING ingester, and if everything goes well, JOINING ingester switches to ACTIVE state. If hand-over process fails, JOINING ingester will move back to PENDING state and either wait for another hand-over or auto-join timeout.
LEAVING说明
LEAVING is an ingester’s state when it is shutting down. It cannot receive write requests anymore, while it could still receive read requests for series it has in memory. While in this state, the ingester may look for a PENDING ingester to start a hand-over process with, used to transfer the state from LEAVING ingester to the PENDING one, during a rolling update (PENDING ingester moves to JOINING state during hand-over process). If there is no new ingester to accept hand-over, ingester in LEAVING state will flush data to storage instead.
Ingesters 是半状态
Ingesters 故障或者数据丢失
如果说 ingester 崩溃了,所有的 还在内存中的等待刷新到 long-term storage 的数据都会丢失。有两个方式去解决:
复制
这个主要是从一个 ingester 复制到 另一个 ingester . 如果出现单个的 ingester 挂了,数据是不会丢失的,但要是多次的 ingester 的瘫痪,则 数据可能会丢失。
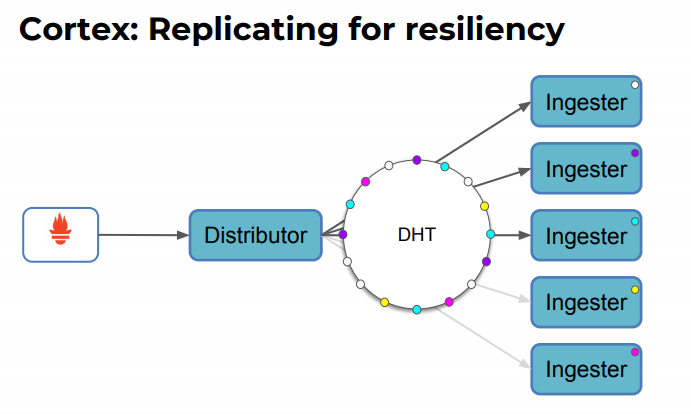
预写日志(WAL)
这就是将我们的数据临时先进行持久化,直到数据被刷新到 long-term storage 。
如果 ingester 失败了, 后续的进程将重新读取 WAL 并恢复到 内存
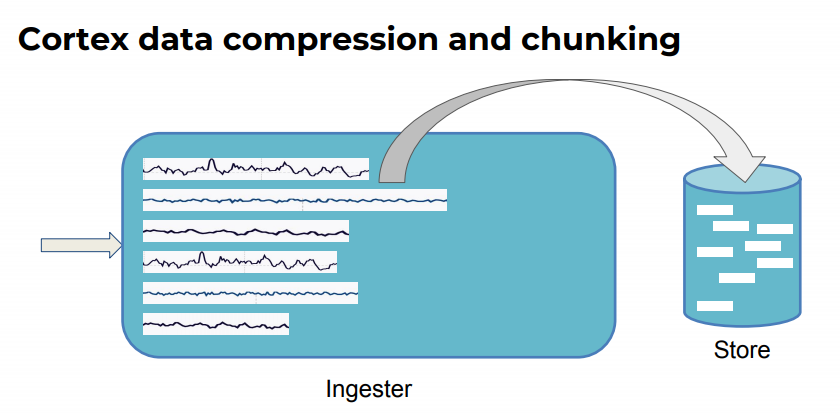
Ingesters write de-amplification
Ingester 收到的 sample 写入内存,以便用于 perform write de-amplification , 如果立即写入到 long-term storge ,系统的存储压力会比较大,而且很难扩展。
Querier
查询器是支持使用 PromQL 进行查询的,也就是说可以直接和 Grafana 进行对接。
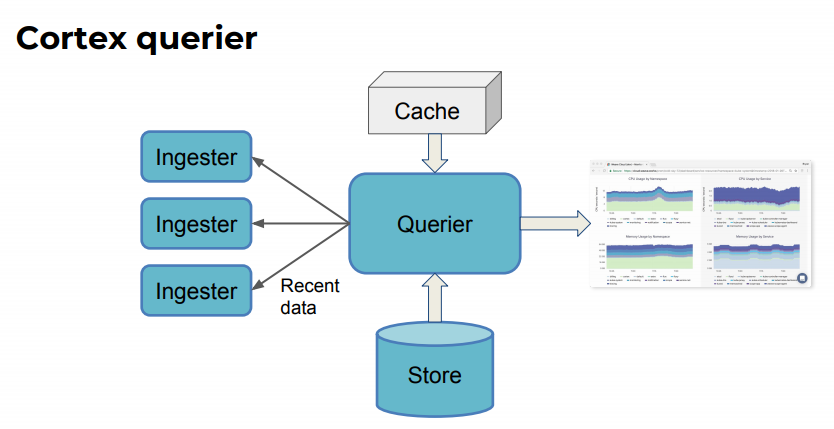
查询器是无状态的。可根据需要去进行向上或者向下的扩展。
Querier fronted
这里主要是针对 API 的查询方式
Caching
查询前端会对上一次的查询结果做一次缓存,下一次如果重现重复的查询操作,直接从缓存拿数据,否则到下一级去处理。
Rule
这是 执行 PromQL 查询记录 的 rules(规则) 和 alerts(警报)
Rule 会将每个租户的 rules / alters 存储在一个数据库 PostgreSQL .
正文到此结束
- 本文标签: 源码 tar 配置 DOM http id 反向代理 测试 sql Cassandra src MQ 缓存 协议 负载均衡 HDFS App dist IO 存储引擎 服务器 https 集群 时间 ORM 索引 apache ip cat API 缩小 Service consul update db 压力 管理 list Architect token tab 进程 数据 value 生命 sharding rand 认证 数据库 UI 实例 删除 一致性 微服务
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

