Apache Flink 扫雷系列 - PyFlink如何解决多JAR包依赖问题
《Apache Flink 扫雷系列》简介
本篇是《Apache Flink 扫雷系列》的第一篇,所以简单介绍一下这一系列的特点,本系列所定义的”雷”是指由于目前Apache Flink目前的设计问题导致的用户非便利性问题的临时解决办法。那么为什么明知道有设计问题还不进行设计重构,避免这些”雷”的存在呢?其实社区的发展和我们各个公司内部产品发展一样,都有一些客观因素导致实际存在的问题无法及时得到解决,比如,社区的Release或者内部产品发布的的周期问题,在没有新的Release之前的一些对用户非友好的问题就需要有一些“非正规”的解决方式,或者说是临时解决方案,这种方案的特点就是,能解决问题,但不是通用性解决手段,只能民间流传,不能官方宣扬。所以《Apache Flink 扫雷系列》就是为大家提供能够解决大家现实问题,但是可能不是最佳实践,大家在这系列中可以有更大的反哺社区的机会:)
开篇说”雷”
本篇的”雷”是目前针对Apache Flink 1.10集以前版本中,在利用CLI提交作业时候只能提交一个JAR的功能问题解决,也就是针对命令参数-j,--jarfile
扫雷难度
面对合并多个JAR包,也许Java用户还好(虽然不便利,但应该都会操作),但对于Python用户,在没有涉及过Java开发的情况下,可能要花费一些时间来完成JARs的合并,甚至有可能有种无从下手的感觉。所以本篇主要针对的是不了解Java的Flink Python用户。
案例选取
为了大家能够实际的体验实际效果,我们选取一个具体的案例来说明如果进行多JARs的合并。我们就选取我在2020年3月17日直播中所说的《 PyFlink 场景案例 - PyFlink实现CDN日志实时分析 》来进行说明。
案例回顾
《 PyFlink 场景案例 - PyFlink实现CDN日志实时分析 》核心是针对灌入Kafka的CDN日志数据经过PyFlink进行按地区的下载量,下载速度的统计,最终将统计数据写入到MySql中。同时放入到Kafka的数据格式是CSV('format.type' = 'csv')。所以我们依赖的JARs如下:
- flink-sql-connector-kafka_2.11-1.10.0.jar
- flink-jdbc_2.11-1.10.0.jar
- flink-csv-1.10.0-sql-jar.jar
- mysql-connector-java-8.0.19.jar
我们可以用如下命令下载:
$ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-csv/1.10.0/flink-csv-1.10.0-sql-jar.jar $ curl -O https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.19/mysql-connector-java-8.0.19.jar
我们将如上4个JARs下载到某个目录,我这里下载到本机的temp目录:
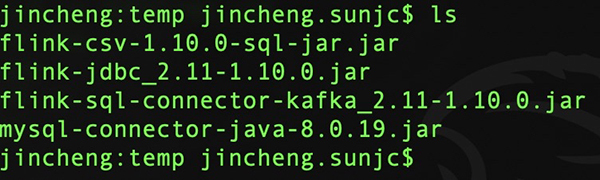
“雷”存在的场景说明
为啥在博客《 PyFlink 场景案例 - PyFlink实现CDN日志实时分析 》并没有提到要合并JARs的问题? 是的,这个“雷”的存在是有一定的条件的:
作业提交的集群环境没有预先安装你所有需要的JARs(大部分情况都是不会安装的)
上面条件是必须成立,才会存在扫雷的问题。那么在博客中我在集群环境预安装了说需要的JARs,也就是博客中提到的下载JARs到集群lib目录
PYFLINK_LIB= python -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__))+'/lib')")
的操作。
合并JARs的注意点
合并JARs的一个很重要的点是涉及到了JAR包的Service Provider机制,详细规范详见。这是让Python人员是很难注意到的合并重点。JAR包的Service Provider机制会允许在JAR包的META-INF/services目录下保存Service Provider的配置文件。简单说就是他为开发者提供了一种扩展机制,在开发阶段只是定义接口,然后在包含实现的JAR包进行实现配置,就可以调用到实际接口的实现类。关于JAR包META-INF目录结构简单说明如下:
- META-INF - 目录中的下列文件和目录获得Java 2平台的认可与解释,用来配置应用程序、扩展程序、类加载器和服务:
- MANIFEST.MF - 清单文件,用来定义与扩展和数据包相关的数据。
- INDEX.LIST - 这个文件由JAR工具的新“-i”选项生成,其中包含在一个应用程序或扩展中定义的数据包的地址信息。它是JarIndex的一部分,被类加载器用来加速类加载过程。
- x.SF - JAR文件的签名文件。x代表基础文件名。
- x.DSA - 这个签名块文件与同名基础签名文件有关。此文件存储对应签名文件的数字签名。
- services - 这个目录存储所有服务提供程序配置文件。
注意:provider配置文件必须是以UTF-8编码。
合并操作
1. 解压JARs
$ mkdir jobjar csv jdbc kafka mysql
其中jobjar存放最终我们打包的JAR内容, csv jdbc kafka mysql存放对应的JAR所解压的内容。具体命令如下:
$ unzip flink-csv-1.10.0-sql-jar.jar -d csv/ $ unzip flink-sql-connector-kafka_2.11-1.10.0.jar -d kafka/ $ unzip flink-jdbc_2.11-1.10.0.jar -d jdbc/ $ unzip mysql-connector-java-8.0.19.jar -d mysql
解压之后我们会在刚才的目录得到如下文件内容:
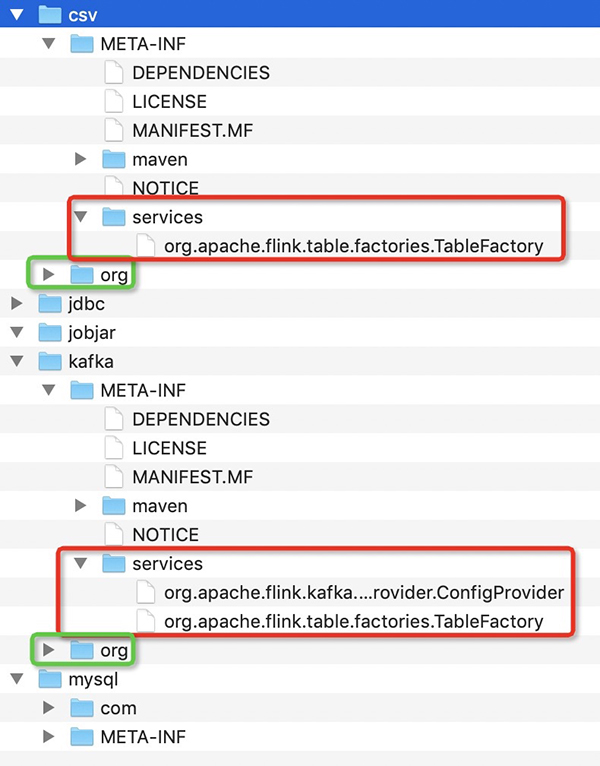
我们核心要处理的是class文件夹和 META-INF/services文件夹,如图csv和kafka的JAR解压之后的内容。其中,Class文件夹可以直接拷贝。但是services要进行同名的合并,比如上用于Flink的Connector的服务发现配置org.apache.flink.table.factories.TableFactory是需要将文件内容进行合并的。
2. 合并JARs
首先我们创建META-INF和META-INF/services目录,目录结构如下:
jincheng:jobjar jincheng.sunjc$ tree -L 2 . └── META-INF └── services 2 directories, 0 files
(1) class文件合并
将csv jdbc kafka mysql的class直接copy到jobjar目录,如下:
$ cp -rf ../csv/org . $ cp -rf ../jdbc/org . $ cp -rf ../kafka/org . $ cp -rf ../mysql/com . $ tree -L 2 . ├── META-INF │ └── services ├── com │ └── mysql └── org └── apache
详细的目录结构如下:
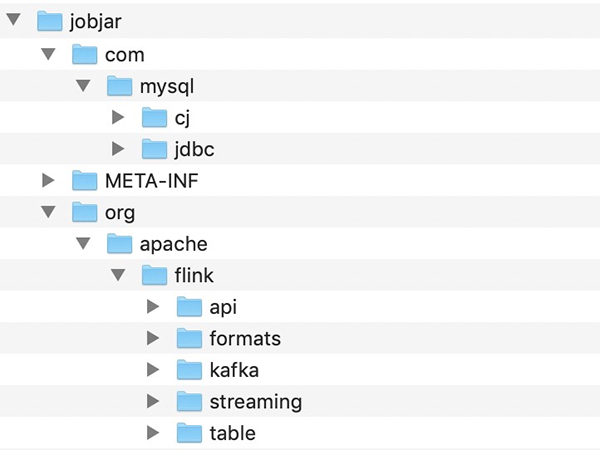
(2) services合并
Service Provider是JAR的一个标准,不仅仅Flink的Connector使用了Service Provider机制,同时Kafka使用了配置的服务发现。所以我们要将所有的services里面的内容按文件名进行合并。以csv和kafka为例:
在CSV里面的META-INF/services里面只有一个和Flink的connector相关的配置,内容如下:
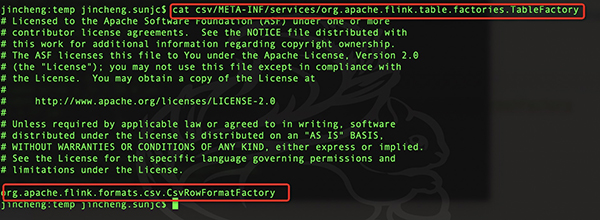
在Kafka里面的META-INF/services里面有Flink的connector相关的配置和Kafka内部使用的配置,内容如下:
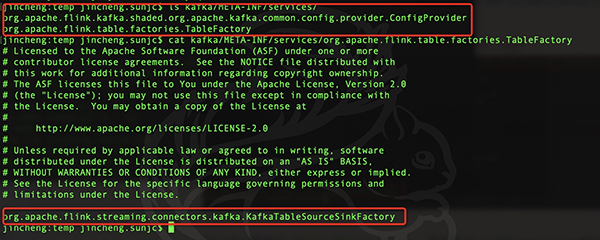
所以我们需要将Kafka相关的直接copy到jobjar/META-INF/services/目录,然后将csv和Kafka关于org.apache.flink.table.factories.TableFactory的配置进行内容合并。合并的内容如下:
# Licensed to the Apache Software Foundation (ASF) under ... ... # limitations under the License. org.apache.flink.formats.csv.CsvRowFormatFactory org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory
我们最终将4个JARs的services配置进行合并之后的最终代码如下:
# Licensed to the Apache Software Foundation (ASF) under ... ... # limitations under the License. org.apache.flink.formats.csv.CsvRowFormatFactory org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory org.apache.flink.api.java.io.jdbc.JDBCTableSourceSinkFactory
大家可以尝试使用的命令如下:
$ cat ../csv/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory $ cat ../kafka/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory $ cat ../kafka/META-INF/services/org.apache.flink.kafka.shaded.org.apache.kafka.common.config.provider.ConfigProvider | grep ^[^#] >> META-INF/services/org.apache.flink.kafka.shaded.org.apache.kafka.common.config.provider.ConfigProvider $ cat ../jdbc/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory
3. 创建JAR
这一步骤没有特别强调的内容,直接用用zip或者jar命令进行打包就好了。
$ jincheng:jobjar jincheng.sunjc$ jar -cf myjob.jar META-INF com org
我最终产生的JAR可以在这里下载,用于对比你自己打包的是否和我的一样:)
OK,到这里我们就完成了多JARs的合并工作。我们可以尝试应用CLI进行提交命令了。
CLI提交作业
- 启动集群(我修改了flink-conf,将端口更改到4000了)
/usr/local/lib/python3.7/site-packages/pyflink/bin/start-cluster.sh local Starting cluster. Starting standalonesession daemon on host jincheng.local. Starting taskexecutor daemon on host jincheng.local.
当没有添加-j选项时候,提交作业如下:
$PYFLINK_LIB/../bin/flink run -m localhost:4000 -py cdn_demo.py
报错如下:

提供正确的-j参数,将我们打包的JAR提交到集群的情况,如下:
$PYFLINK_LIB/../bin/flink run -j ~/temp/jobjar/myjob.jar -m localhost:4000 -py cdn_demo.py

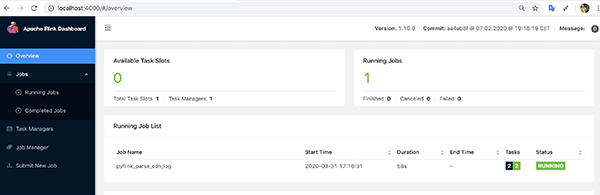
同时Web控制台可以查看提交的作业:
小结
本篇核心介绍了PyFlink的用户如何解决多JARs依赖作业提交问题,也许这不是最Nice的解决方法,但至少是你解决多JARs依赖作业提交的方法之一,祝你 “扫雷” 顺利,也期望如果你有更好的解决办法,留言或者邮件与我分享哦:)!
【本文为51CTO专栏作者“金竹”原创稿件,转载请联系原作者】
戳这里,看该作者更多好文
正文到此结束
- 本文标签: src Service stream apache CDN 安装 时间 lib Job JDBC zip https sql 代码 provider 下载 类加载器 java ip 集群 API 开发 python session 目录 maven cat IDE 博客 id mysql db 产品 数据 解决方法 http IO 端口 grep 开发者 参数 ask executor tab tar UI list 统计 ORM web 配置 CTO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

