设计高质量软件
设计高质量软件
原文地址:https://dzone.com/refcardz/designing-quality-software?chapter=1
提供一套用于构建更好的软件的设计原则,编码原则,测试原则,环境规则以及通用规则清单。
Abstract
可以将软件的技术质量定义为软件系统源自常识和最佳实践中的一组原则和规范的一致性级别(译注:强调原则和规则的通用性)。 这些规则应涵盖软件架构(依赖关系结构),日常编程,测试和编码风格。
技术质量从根本上体现在源代码中。 人们说:“真像只能在源代码中找到”。 因此,达到令人满意的技术质量水平是开发过程中的明确目标和不可或缺的部分,这一点很重要。 为了避免在开发过程中技术质量不断下降,需要定期(至少每天)对其进行度量。 通过这样做,有可能在流程的早期检测并解决不良的违反规则的行为。 越晚检测到违反规则,修复它们的难度和成本就越高。 由于测试只是技术质量管理的几个方面之一,因此仅凭测试就不可能达到可接受的技术质量水平。
本文首先描述了技术质量的最大敌人:即软件架构侵蚀。 应对架构侵蚀的最好方法是保持软件系统的大规模结构处于良好的状态。 因此,本文着重于大规模系统设计,这对应用程序安全性方面也具有重要意义。 前半部分的内容非常技术性, 目的是支持架构师和开发人员解决可能对技术质量和软件架构产生负面影响的典型日常问题。 后半部分包含一组从经验和实际项目中得出的精炼规则。 实施和执行这些规则将帮助你达到较高的技术质量和可维护性,同时优化开发团队的生产力。
本文目标受众是软件架构师,开发人员,质量经理和其他技术利益相关者。 尽管文章的主要部分是与编程语言无关的,但最后的规则集最适合与静态类型的面向对象的语言(例如Java,C#或C ++)一起使用。
Structural Erosion

所有软件项目都始于希望和雄心。架构师和开发人员致力于创建一款易于维护且有趣的优雅,高效的软件。 通常,他们在脑海中具有预先设计的重要想象。 但是,随着代码库的扩大,情况开始发生变化。 该软件越来越难以测试,理解,维护和扩展。 用Robert C. Martin的话来说,“该软件开始像一块烂肉一样腐烂”。
这种现象被称为“架构腐蚀”或“架构债务累积”,并且这种现象几乎发生在每个重要的软件项目中。 通常,由于需求的变化,时间压力或简单的疏忽,腐蚀始于与预先设计的微小偏差。 在项目的早期阶段,这不是问题。 但是在后期阶段,架构债务的增长速度远快于代码库。 作为此过程的结果,将变更作用于系统而不破坏某些东西变得更加困难。 生产力显着下降,变更成本不断增长,直至无法承受。
Robert C. Martin described a couple of well-known symptoms that can help you to figure out whether or not your application is affected by structural erosion:
Robert C. Martin描述了几个众所周知的症状,这些症状可以帮助弄清你的应用程序是否受到架构侵蚀的影响:
- 刚性:系统难以变更,因为每次更改都会导致许多其他更改。
- 脆弱性:变更会导致系统在概念上不相关的地方崩溃。
- 固化:很难将系统分解为可重复使用的组件。
- 粘度:正确地做事比不正确地做事困难。
- 不透明:很难阅读和理解代码。 代码没有很好地表达其意图。
你可能会同意这些症状会以一种或另一种方式影响大多数不重要的软件系统。 而且,系统越老,使用它的人越多,症状变得越严重。 避免它们的唯一方法是,在日常开发过程中制定一项抗衡架构侵蚀的斗争计划。
大规模系统设计
依赖管理
软件系统的大规模设计通过其依赖关系结构得以体现。 只有明确管理整个软件生命周期中的依赖性,才有可能避免架构侵蚀的负面影响。 依赖管理的一个重要方面是避免软件组件之间编译时的循环依赖性:
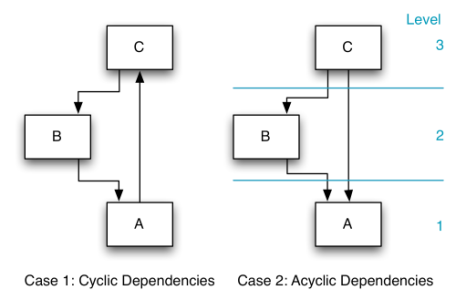
案例1显示了单元A,B和C之间的循环依赖性。因此,无法为这些单元分配等级编号,从而导致以下不良后果:
- 只有了解所有单元才能了解单个单元背后的功能。
- 单个单元的测试包含所有单元的测试。
- 重用仅限于一种选择:重用所有单元。 这种紧密耦合是为什么几乎没有可重用软件组件的原因之一。
- 修复一个单元中的错误会自动涉及三个单元的整个组。
- 难以对计划的变更进行影响分析。
情况2代表形成无环有向依赖图的三个单元。 现在可以分配等级编号。 结果如下:
- 通过具有清晰的顺序(首先是A,然后是B,然后是C),可以清楚地了解这些单位。
- 明显的测试顺序:先测单元A; 再测单元B,最后测试单元C。
- 关于重用,可以单独复用A、A和B或完整的解决方案(ABC)。
- 要解决单元A中的问题,可以单独进行测试,通过测试可以验证错误已得到实际修复。 对于测试单元B,仅需要单元B和A。 随后,可以进行真正的集成测试。
- 影响分析可以轻松完成。
请记住,这是一个非常简单的示例。 许多软件系统都有数百个单元。 拥有的单位越多,能够对依赖关系图进行平衡就变得越重要。 否则,维护它们将成为一场噩梦。
以下是公认的软件架构专家对依赖管理的评价:
“It is the dependency architecture that is degrading, and with it the ability of the software to be maintained.” [ASD]
“The dependencies between packages must not form cycles.” [ASD]
“Guideline: No Cycles between Packages. If a group of packages have cyclic dependencies then they may need to be treated as one larger package in terms of a release unit. This is undesirable because releasing larger packages (or package aggregates) increases the likelihood of affecting something.” [AUP]
“Cyclic physical dependencies among components inhibit understanding, testing and reuse.” [LSD]
耦合性度量
依赖性管理的另一个重要目标是最大程度地减少软件不同部分之间的整体耦合。 较低的耦合意味着更高的灵活性,更好的可测试性,更好的可维护性和更好的可理解性。 此外,较低的耦合度还意味着变更只会影响应用程序的较小部分,从而大大降低了回归错误的可能性。
为了控制耦合,有必要对其进行测量。 [LSD]描述了两个有用的耦合度量: 平均组件依赖关系(Average Component Dependency,ACD) 告诉我们随机选择的组件将依赖于平均值(包括自身)有多少个组件。 标准化累积组件相关性 (Normalized Cumulative Component Dependency,NCCD)正在将依赖图(应用程序)的耦合与平衡二叉树的耦合进行比较。
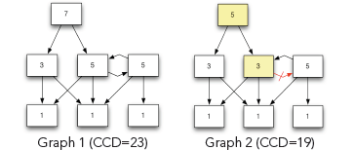
在上面,您看到两个依赖关系图。 组件内部的数字反映了可从给定组件(包括自身)访问的组件数量。 该值称为组件依赖关系(CD)。 如果将图1中的所有数字相加,则总和为23。此值称为“累积组件相关性”(CCD)。 如果将CCD除以图中的组件数,则将得到ACD。 对于图1,该值为3.29(23/7)。
请注意,图1包含循环依赖性。 在图2中,删除红色所示的相关性破坏了循环,从而将CCD减小到19,将ACD减小到2.71(19/7)。 如您所见,打破循环肯定有助于实现我们的第二个目标,即从整体上减少耦合。
NCCD is calculated by dividing the CCD value of a dependency graph through the CCD value of a balanced binary tree with the same number of nodes. Its advantage over ACD is that the metric value does not need to be put in relation to the number of nodes in the graph. An ACD of 50 is high for a system with 100 elements but quite low for a system with 1,000 elements.
通过将依赖图的CCD值除以节点数相同的平衡二叉树的CCD值来计算NCCD。 与ACD相比,它的优势在于,度量值不必与图形中的节点数有关。 对于具有100个元素的系统,ACD为50会很高,但是对于具有1,000个元素的系统,ACD会非常低。
平衡二叉树的CCD:由n个组件组成的完全平衡的二叉依赖树的CCD为(n + 1)* log2(n + 1)-n
检测并打破循环依赖
同意避免循环编译时依赖是一个好主意。 找到并打破它们则是另一个故事。
找到它们的唯一真正的选项是使用依赖性分析工具。 对于Java,有一个简单的免费工具,称为“ JDepend” [JDP]。 如果您的项目不是很大,还可以使用“ SonarJ” [SON]的免费“社区版”,它比JDepend强大得多。 对于更大的项目,您需要购买SonarJ的商业许可证。 如果不使用Java或寻找更复杂的功能(如循环可视化和分解建议),则必须使用商业工具。
找到循环依赖关系后,你必须决定如何打破它。 代码重构可以打破组件之间的任何循环编译时依赖性。 最常用的重构方法是添加接口。 以下示例显示了应用程序的“ UI”组件和“ Model”组件之间的不良循环依赖关系:

The example above shows a cyclic dependency between “UI” and “Model”.Now it is not possible to compile, use, test or understand the “Model” component without also having access to the “UI” component. Note that even though there is a cyclic dependency on the component level, there is no cyclic dependency on the type level.
上面的示例显示了“ UI”和“模型”之间的循环依赖关系。现在,如果无法访问“ UI”组件,则无法编译、使用、测试或理解“模型”组件。 请注意,即使在组件级别上具有循环依赖性,在类型级别上也没有循环依赖性。
将接口“ IAlarmHander”添加到“模型”组件即可解决该问题,如下图所示:
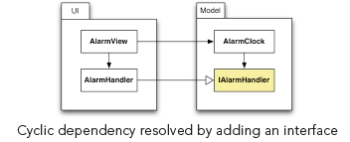
现在,“ AlarmHandler”类仅实现了“ Model”组件中定义的接口。 通过用“实现”依赖项替换“使用”依赖项,可以反转依赖的方向。 这就是为什么该技术也被称为“依赖倒置原则”的原因,最早由Robert C. Martin [ASD]描述。 现在,可以隔离地编译、测试和理解“模型”组件。 而且,仅通过实现“ IAlarmHandler”接口就可以重用组件。 请注意,即使该方法在大多数情况下都能很好地工作,过度使用接口和回调也会带来不良的副作用,例如增加复杂性。 因此,下一个示例显示了另一种打破循环的方法。 在[LSD]中,您将找到几种其他的编程技术来打破循环依赖。
在C ++中,可以通过编写仅包含纯虚函数的类来模仿接口。
有时,您可以通过重新改编类的功能来中断周期。 下图显示了一种典型情况:
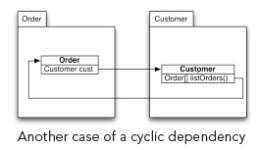
“订单”类引用“客户”类。 “客户”类还在便捷方法“ listOr ders()”的返回值上引用“订单”类。 由于这两个类位于不同的程序包中,因此会产生不希望的程序包循环依赖性。
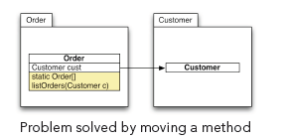
通过将便捷方法移至“ Order”类(将其转换为静态方法)来解决该问题。 在这种情况下,对循环中涉及的组件进行调级很有帮助。 在该示例中,很自然地假设订单是比客户更高级别的对象。 订单需要了解客户,但是客户不需要知道订单。 建立级别后,只需要将所有依赖项从低级对象削减到高级别对象。 在示例中,这就是从“客户”到“订单”的依赖关系。
重要的是要提到我们在这里不考虑运行时(动态)依赖性。 出于大规模系统设计的目的,仅编译时(静态)依赖项是相关的。
像Spring框架[SPG]这样的控制反转(IOC)框架的使用将使得避免循环依赖性和减少耦合变得容易得多。
逻辑架构
主动管理依赖关系需要定义软件系统的逻辑架构。 逻辑架构将诸如类,接口或包(C#和C ++中的目录或名字空间)之类的物理(编程语言)级元素分组为诸如层,子系统或垂直切片之类的高层架构制品。
逻辑架构定义了这些工件,物理元素(类型,包等)到这些制品的映射以及架构制品之间允许和禁止的依赖关系。
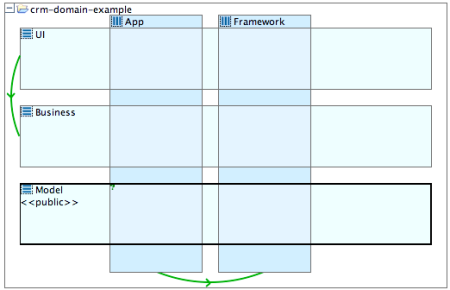
具有层和切片的逻辑架构示例
以下是架构制品的列表,可以使用它们来描述应用程序的逻辑架构:
| 架构制品 | 描述 |
|---|---|
| 垂直切片 | 尽管许多应用使用水平分层,但是大多数软件架构师都忽略了垂直切片的清晰定义。 功能方面应确定应用的垂直组织。 典型的切片名称为“客户”、“合同”、“框架”等。 |
| 子系统 | 子系统是最小的架构制品。 它把实现特定的主要技术功能的所有类型组合在一起。 典型的子系统名称为“ Logging”、“ Authentication”等。子系统可以嵌套在层和切片中。 |
| 自然子系统 | 图层和切片之间的交点称为自然子系统。 |
| 子项目 | 有时项目可以分为几个相互关联的子项目。 子项目对于组织最高抽象级别的大型项目很有用。 建议在一个项目中存有多个子项目。 |
如果需要,可以嵌套图层和切片。 但是,为简单起见,建议不要使用多于一层的嵌套。
代码到架构制品的映射
为了简化代码导航和将物理实体(类型,类,包)映射到架构制品的过程,强烈建议对包(C ++或C#中的名字空间或目录)使用严格的命名约定。 一种行之有效的最佳实践是在包名称中嵌入架构制品的名称。
例如,可以使用以下命名约定:
com.company.project.[subproject].slice.layer.[subsystem]…
方括号中的部分是可选的。 对于不属于任何层或切片的子系统,可以使用:
com.company.project.[subproject].subsystem…
当然,如果使用层或切片的嵌套,则需要调整此命名约定。
应用安全方面
大多数人不考虑应用程序安全性与应用程序的架构(依赖结构)之间的联系。 但是经验表明,潜在的安全漏洞在遭受架构侵蚀的应用程序中更为常见。 这样做的原因很明显:如果依赖关系结构被破坏并且充满循环,则很难在应用程序内部跟踪受污染数据(来自外部的不受信任数据)的流向。 因此,在由应用程序处理这些数据之前,验证这些数据是否已正确验证也变得更加困难。
On the other hand, if your application has a well-defined logical architecture that is reflected by the code, you can combine architectural and security aspects by designating architectural elements as safe or unsafe. “Safe” means that no tainted data are allowed within this particular artifact. “Unsafe” means that data flowing through the artifact is potentially tainted. To make an element safe, you need to ensure two things:
另一方面,如果你的应用具有代码所反映的定义良好的逻辑架构,则可以结合架构和安全方面通过将体系结构元素指定为安全或不安全。 “安全”是指在此特定制品中不允许污染数据。 “不安全”表示流过制品的数据可能受到污染。 为了使元素安全,您需要确保两件事:
- safe元素不应调用任何返回可能被污染的数据(IO,数据库访问,HTTP会话访问等)的API。 如果出于任何原因,必须验证这些API返回的所有数据,则必须这样做。 *所有入口点都必须通过数据验证来保护。
与必须假设整个代码库可能不安全相比,这(使用依赖项管理工具)进行检查和执行要容易得多。依赖项管理工具通过验证所有传入的依赖项仅使用正式入口点,在确保元素安全方面起着重要作用。绕过这些入口点的传入依赖项将被标记为违规。
当然,实际的数据处理只能在“安全”的架构元素中完成。通常,您会将Web层视为“不安全”,而包含业务逻辑的层应全部为“安全”层。
由于许多应用都遭受或多或少的严重架构侵蚀,因此很难使其免受潜在的安全威胁。在这种情况下,你可以尝试使用依赖性管理工具来减少架构侵蚀并创建“安全”处理内核,也可以依靠专门用于查找潜在漏洞的昂贵的商业软件安全性分析工具。虽然第一种方法在短期内会花费您更多的时间和精力,但实际上可以通过提高代码的可维护性和安全性来获得良好的回报。第二种方法更像是一个短期补丁,无法解决根本原因,这是代码库的架构侵蚀。
常识规则
达到较高技术质量的最佳方法是将一小组规则与基于自动化工具的规则检查和执行方法相结合(有关建议,请参见规则T2。通常,至少应在检查过程中自动检查规则)如果可能的话,规则检查器也应该成为开发人员环境的一部分,以便开发人员甚至可以在将更改提交到VCS [SON]之前检测到违反规则的情况。
因此,建议的规则集是出于意图的简约,可以在需要时进行自定义。经验表明,尽量减少规则数量总是一个好主意,因为这样可以更轻松地在开发过程中检查和执行规则。添加的规则越多,每条附加规则将带来的附加利益越少。这里介绍的规则集基于常识和经验,已经被许多软件开发团队成功实施。
不幸的是,本文没有足够的空间来更详细地解释规则。有关更多信息,请参考最后的参考部分。有些规则似乎是任意的。在这种情况下,可以假定它们源自常识和最佳实践。当然,也可以自由调整阈值和规则以更好地匹配你的特定环境。
规则分为三个优先级类别:
| 级别 | 建议 |
|---|---|
| 主要规则 | 必须始终遵循 |
| 次要规则 | 强烈建议您遵循此规则。 如果不可能或不希望这样做,则必须记录原因 |
| 指导方针 | 建议遵循此规则 |
Design Rules
这些规则涵盖了系统的大规模架构方面。
Major Rules
- D1: 为应用定义无循环逻辑架构,只有拥有定义良好且循环极小的应用程序,才有机会首先避免架构侵蚀。
- D2: 根据逻辑架构为类型和包定义严格而明确的命名约定。命名约定还定义了代码与逻辑架构之间的映射,这将大大简化代码的导航和理解。 在C++或C#中,应使用名称空间或目录替换包。
- D3: 代码必须遵守逻辑架构。该规则理想情况下由工具执行。 基本上,该工具必须确保应用中的所有依赖项都符合D1中定义的逻辑架构。
- D4: 包依赖关系不能形成循环,循环依赖关系的不良影响已在前面进行了详细讨论。
- D5: 编译单元的NCCD不得大于7。此规则与我们保持较小耦合的目标相对应。 如果该值超过阈值,则应仅允许层和子系统具有接口作为入口点来隔离它们。 打破循环依赖也可以大大缩小该指标。
Minor Rules
- D6: 创建逻辑架构时,请牢记安全性方面。从一开始就为应用安全性进行规划。 指定“安全”和“不安全”(可能会污染数据)的架构元素。 确保安全元素和不安全元素之间的边界尽可能窄,以便轻松验证所有传入数据均已正确验证。
- D7: 在逻辑架构级别将技术方面与领域方面分开,将这两个方面分开是维护健康软件的最有希望的方法。 技术方面可能会在不久的将来发生变化。 业务抽象及其相关逻辑更可能是稳定的。 Spring框架实现了一种很好的方法来将业务方面与技术方面分开[SPG]。
- D8: 使用一致的异常处理应该以一致的方式进行异常处理,方法是对基本问题(例如“什么是异常?”,“有关错误的哪些信息应写入何处?”的答案)进行回答。 低级别的异常在非技术层中不可见。 相反,应根据其级别在语义上进行转置。 这也可以防止紧密耦合到实现细节。
Guidelines
- D9: 编译单元之间的依赖不能形成循环依赖。 [LSD]中提供了一般性讨论。
- D10: 使用设计模式和架构风格。设计模式和架构风格重复使用经过验证和测试的概念。 设计模式还为常见的设计情况建立了标准化的语言。 因此,强烈建议在可能且有用的地方使用设计模式[DES]。
- D11: 不要重新发明轮子,请尽可能使用现有的设计和实现。 有时乍看之下并不明显,新的实现可能会产生多少错误。 每行未编写的代码都是系统质量的标准,并使维护更加容易。
编程规范
Major Rules
- P2: 将类和实例变量声明为私有的。所有可修改或非原始的类和实例变量都应定义为私有。 这增强了接口和实现之间的分隔[LSD]。
Minor Rules
- P3: 永远不要捕获“ Throwable”或“ Error”(Java)来捕获“ Throwable”和“ Error”类型的异常(包括子类)违反了J2SE设计的基本思想。 仅针对Exception类型的异常处理。
- P4: 避免空的捕获块。空的捕获块会抑制有用的错误处理。 如果捕获到指定的异常并不重要,那么至少需要注释和可能是可配置的日志输出。 系统应保持合法状态。
- P5: 限制对类型和方法的访问。将所有类型和方法声明为public很容易,但可能不是你想要的。 如果应该从外部看到类型和方法,则仅使它们可见[LSD]。
- P6: 限制可扩展性 - 将final用于类型和方法(Java,C#)。final关键字指出该类不适用于子类。 对于方法,很明显,它们不应被覆盖。 默认情况下,一切都应该是最终的。 除非你明确希望允许通过子类覆盖行为,否则将所有事情都确定下来。
- P7: 提供有关类型的基本文档。着重描述类型的职责。 如果可以轻松,准确地表述职责,则这是足够抽象的明确指标。 另请参阅“单一责任原则”[ASD].
- P8: 包中的类型数不能超过50。分组类型以及相关的职责有助于保持清晰的物理结构。 包是具有整体责任感的物理设计的内聚单元。 过载的包很有可能在物理设计中引起过多的循环。
- P9: 单文件代码行(编译单元)不得超过700行。大型编译单元难以维护。 此外,它们经常违反清晰抽象的思想,并导致耦合大大增加。
- P10: 方法参数的数量不得超过7。方法参数的数量可能表示程序设计。 可能的参数组合的纯数量可能导致复杂的方法实现。
- P11: 循环复杂度不得超过20。循环复杂度(CCN)通过方法指定可能的控制路径。 如果方法的CCN较低,则更易于理解和测试。 正式定义请参见[CCN]。
- P12: 使用断言使用“ assert”(C#的Debug.Assert)来确保采用“按契约设计”风格[TOS]的前提条件,后置条件和不变式。 验证从未使用断言来验证来自用户或外部系统的数据非常重要。
测试和环境规范
Major Rules
- T1: 使用版本控制系统。 如果无法跟踪更改和同步更改,就不可能编写可靠的软件。
- T2: 设置持续构建服务器并衡量规则的遵从性,应该可以完全独立于IDE来构建系统。 对于Java,建议使用Maven,Ivy或ANT。 将尽可能多的规则检查器集成到构建脚本中,以便可以自动检查此处提到的规则。 架构检查比其他检查具有更高的优先级,因为一旦架构性问题遍及你的应用,它们将很难修复。 理想情况下,严重违反规则应导致构建失败。
- T3: 与代码一起编写单元测试。此外请确保所有单元测试至少在夜间构建期间执行,最好在每次构建时都执行。 这样,当更改导致回归错误时,你将获得早期反馈。 在执行测试时,测试工具通常还会衡量测试覆盖率。 确保测试覆盖了应用程序的所有复杂部分。
-
T4: 根据逻辑架构定义测试。测试设计应考虑整体逻辑架构。 为所有“数据传输对象”创建单元测试,而不是提供业务逻辑的测试类是没有用的。 一个项目应该在最低层次测试上建立明确的规则,而不是盲目地创建测试。推荐的规则是: *为所有与业务相关的对象提供单元测试。独立地测试业务逻辑。 *对已发布的接口进行单元测试。 总体目标是拥有良好的直接和间接测试覆盖率。
Minor Rules
- T5: 使用问题跟踪器和Wiki等协作工具。使用问题跟踪器来跟踪问题和计划的更改。 在Wiki中记录应用程序的所有主要设计概念和抽象。
结论
如果你正在开始一个新项目,或在一个现有项目上进行工作,或想要改善组织中的开发过程,则本文是一个很好的起点。 如果你实施并执行上述大多数规则,则可以期望在开发人员生产力,系统可维护性和技术质量方面有显着改善。 尽管这会在一开始就花费很多精力,但总体节省额要比最初的努力大得多。 因此,对于每个专业软件开发组织来说,采用设计和质量规则不仅是“必备”,而且是强制性的。
References
- [ASD] Agile Software Development, Robert C. Martin, Prentice Hall 2003
- [AUP] Applying UML And Patterns, Craig Larman, Prentice Hall 2002
- [LSD] Large-Scale C++ Software Design, John Lakos, Addison-Wesley 1996
- [DES] Design Patterns, Erich Gamma, Richard Helm, Ralph Johnson, John
- Vlissides, Addison-Wesley 1994
- [TOS] Testing Object-Oriented Systems, Beizer, Addison-Wesley 2000
- [JDP] http://www.clarkware.com/software/JDepend.html
- [SON] http://www.hello2morrow.com/products/sonarj
- [SPG] http://www.springsource.org
- [CCN] http://en.wikipedia.org/wiki/Cyclomatic_complexity
- [HUD] http://hudson-ci.org
- [SNR] http://www.sonarsource.org
正文到此结束
- 本文标签: https 开发 数据 生命 希望 java 时间 单元测试 maven 组织 cat 回报 Logging 管理 bug 定制 App git 缩小 UI 删除 IO spring 需求 静态方法 自动化 list 压力 同步 NSA 免费 一致性 编译 空间 struct dependencies 配置 http ORM 目录 代码 架构师 node value 数据库 漏洞 文章 模型 服务器 设计模式 tag ip 参数 安全 src ioc GitHub 回答 tab 实例 final IDE Architect id web 注释 覆盖率 质量 软件 保安 example Security API 数据库访问 测试 HTML
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

