细数Java项目中用过的配置文件(YAML篇)
YAML,在项目中用过没?它与 properties 文件啥区别?
目前 SpringBoot、SpringCloud、Docker 等各大项目、各大组件 ,在使用过程中 几乎 都能看到 YAML 文件的身影。
2017 年的时候,我才真正把 YAML 文件用到负责的项目中,当时用 YAML 文件主要是为 Sharding-JDBC 配置数据源以及分库分表的规则。

从实际项目中把 sharding-jdbc.yaml 文件抽出来,为了更清晰,进行了大量简化,接下来就 一同感受一下 YAML 的魅力 。

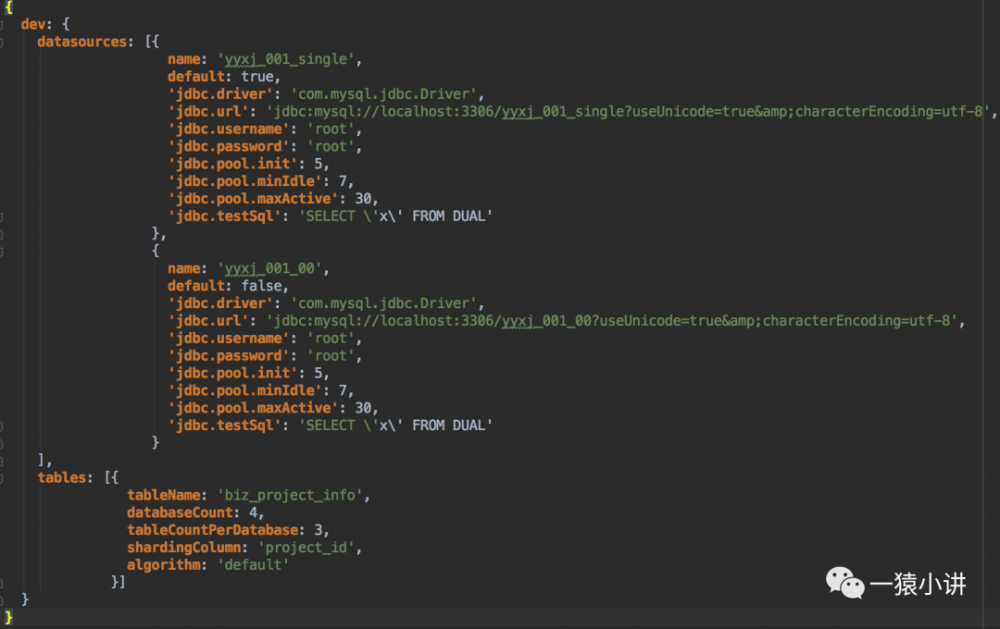
上图配置的内容虽然还没解释,仔细去看配置,大体都能看明白。其实,这就是 YAML 比 properties 配置文件的优势所在,层次感分明, 配置有序, 而且比较简洁。
纵然配置已经很清晰,还是要稍微带着看一看配置内容。
dev 是一个对象,对应于 Java 中的 Map,包含 datasources 和 tables 两个属性。 其本身含义是开发环境配置,当然实际项目中也会有测试、准生产、生产的对应的配置。
datasources 属性是一个数组,对应于 Java 中的 List,数组元素由 name、default 等 10 个属性构成。 其本身含义是数据源配置,因为涉及到分库,所以会有好多库要连接,图中只列举两个数据库;
tables 属性也是一个数组,对应于 Java 中的 List,数组元素由 tableName、databaseCount 等 5 个属性构成。 其本身含义是要拆分表的规则配置,图中只列举一个项目基本信息表。
按照常规思路,写好配置文件,接下来就要校验一下,再稍微格式化一下。
在这儿校验Yaml文件:http://www.bejson.com/validators/yaml/
如上图所示,YAML 文件校验转换之后,就真的太清晰啦!
不过,YAML 是很简单,但是 有些细节,在开发中还是要注意 ,否则入坑就难跳出( 一旦入坑,真的不好跳出来,别问为什么?一个空格难倒英雄汉,真心体会过 )。
Tips:
1. 使用冒号加缩进的方式代表层级关系,使用短横杠代表数组元素;
2. 注意缩进不允许使用「tab」 键 ,只能使用 空格 键( 曾经 掉这个坑啦,记忆之深刻 );
3. 缩进 空格 个数多少并不重要,只要相同层级的元素左对齐即可;
4. 如果冒号后跟着 value,一定要注意冒号后跟上 空格 呦!
5. YAML 大小写很敏感。
有关 YAML 的更多规范,可以参考如下 pdf,本次不过多展开去讲。
https://yaml.org/spec/1.2/spec.pdf
YAML 配置有了,该怎么去解析呢?
在不同的编程语言中,都有很多三方工具可以解析 YAML 文件,而在 Java 项目可以用 SnakeYaml 进行解析,接下来就写写代码体验一下 yaml 文件的解析。
首先引入依赖包(想用人家,就别想撇清关系!)
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.18</version>
</dependency>
码点代码(从原项目中直接拿来,为了清晰,索性只留解析 YAML 文件部分的代码,呈现给你)
import org.apache.commons.collections4.MapUtils;
import org.yaml.snakeyaml.Yaml;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* @author 一猿小讲
*/
public class ShardingJdbcDataSource {
private static LinkedHashMap<String, Object> profile;
@SuppressWarnings("unchecked")
public static ArrayList<LinkedHashMap<String, Object>> parse(String profileId, String key) throws IOException {
//如果profile为空的情况才进行加载配置文件,减少读取文件的次数
if (MapUtils.isEmpty(profile)) {
Yaml yaml = new Yaml();
File file = new File(ShardingJdbcDataSource.class.getResource("/").getPath() + "sharding-jdbc.yaml");
try (FileReader fileReader = new FileReader(file);) {
Map<String, Object> result = yaml.loadAs(fileReader, Map.class);
profile = (LinkedHashMap<String, Object>) result.get(profileId);
}
}
return (ArrayList<LinkedHashMap<String, Object>>) profile.get(key);
}
public static void main(String[] args) throws IOException {
// 开发环境
String profileId = "dev";
// 数据源集合
ArrayList<LinkedHashMap<String, Object>> datasources = parse(profileId, "datasources");
for (LinkedHashMap<String, Object> datasource : datasources) {
System.out.println(String.format("数据库名称:%s",datasource.get("name")));
System.out.println(String.format("数据库URL:%s",datasource.get("jdbc.url")));
}
System.out.println("=============华丽的分割线==============");
// 表集合
ArrayList<LinkedHashMap<String, Object>> tables = parse(profileId, "tables");
for (LinkedHashMap<String, Object> table : tables) {
System.out.println(String.format("表名称:%s",table.get("tableName")));
System.out.println(String.format("数据库拆分 %d 个",table.get("databaseCount")));
System.out.println(String.format("每个数据库表的数目:%s",table.get("tableCountPerDatabase")));
}
}
}
去掉 main 函数,发现解析代码没几行,跑起来看一看,效果还可以。

文中的解析 YAML 文件的代码,改个类名,就可以直接变成工具类,如果有需要,自行简单封装一下就 ok 啦。
其中 SnakeYam l 类库还有很多 API 可以使用,不一一带着写代码啦,感兴趣的自行参考 SnakeYam l 官方文档,去照猫画虎敲敲吧。
https://bitbucket.org/asomov/snakeyaml/wiki/Documentation
另外,细心的你在平时研发时,有没有发现,有的项目 YAML 文件的后缀是 .yml ,有的项目却是 .y a ml ,到底哪个是正确的呢?很久很久之前我也纠结过,感兴趣可以去 stackoverflow 溜达一番。
https://stackoverflow.com/questions/21059124/is-it-yaml-or-yml
好了,有关 YAML 文件在实际项目中的使用,本次就谈到这里,它山之石可以攻玉,希望能对你有所帮助。

推荐阅读:
细数Java项目中用过的配置文件(ini 篇)
细数Java项目中用过的配置文件(properties 篇)
正文到此结束
- 本文标签: IO HashMap spring js 代码 key ORM springcloud https API Collections http sharding ip 数据 Docker src springboot db UI json dataSource validator tab 配置 Document id 测试 map parse 开发 希望 JDBC apache 数据库 解析 list Collection ArrayList java HTML value
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

