了解一下,Android 10中的ART虚拟机(4)
缘起
今天及后续几篇关于ART的知识,我将从读书笔记的角度来系统的学习《Advanced Design and Implementation of Virtual Machines》。这本书是英文编写,全部、认真、深入的读下来非常考验人。我之前也只是读了60%,而且越到后面越没有耐心。想了想,JVM在系统层面上要达到一定水准,可能还是得精读一到两本这样的书籍。记读书笔记是我学习知识和技能的一种比较好的方式,伴随我至少20多年了。暂且给这次的读书笔记取名“关于VM的理论”。
关于VM的笔记(Theory of VMs)

下面开始笔记时间。首先,是VM的种类。
VM的种类
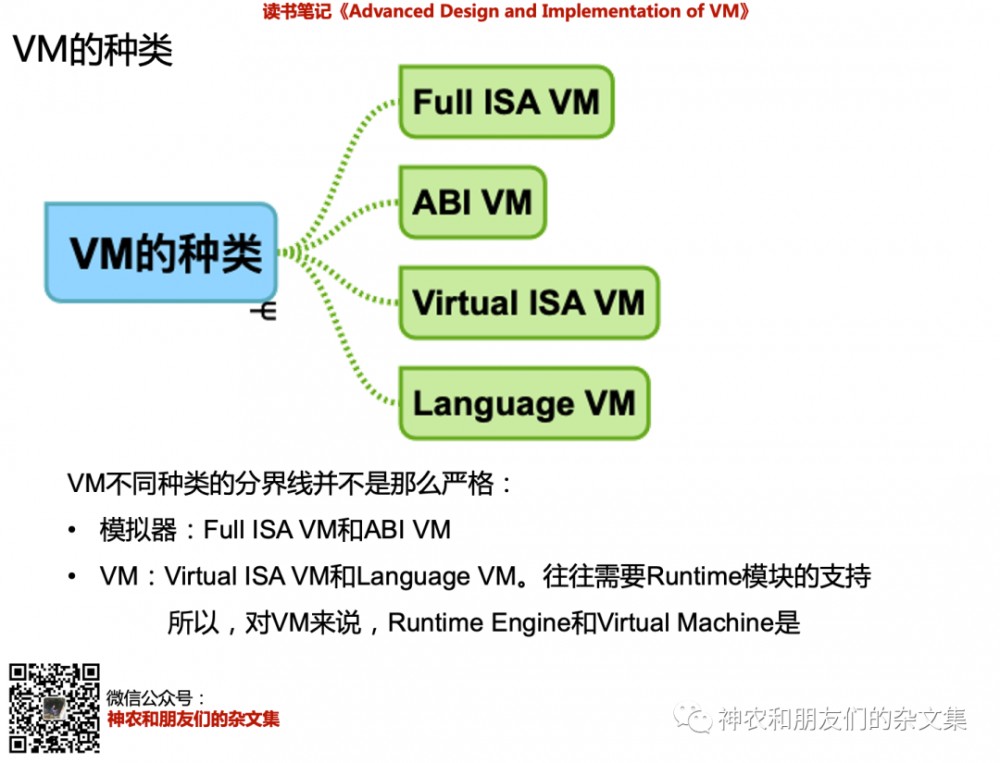
作者将vm划分为4种。先说一句,这4种划分更倾向于是看待VM的角度不一样,而不是什么严格的条条框框。
-
Full ISA VM和ABI VM:这两种类型的VM偏向于模拟器。ISA是Instruction Set Architecture,往往和CPU体系关联。而ABI是Application Binary Interface,也和CPU体系以及OS关联。所以,Full ISA VM和ABI VM偏向于模拟器。例如qemu在x86主机上模拟arm的cpu、以及Windows上用vmware跑黑苹果。
-
Virutal ISA VM和Language VM:这两种偏向于我们在编程语言里提到的VM,例如Java虚拟机,Python虚拟机。值得指出的是,Virual ISA VM是指VM上跑的是虚拟指令集(对应x86、ARM这种硬件指令集)。这句话的“说人话”版本的一个例子就是Java VM运行的是Java bytecode。显然,Java bytecode是Java VM的指令集。而Language VM虽然其中赤裸裸得有Language一词,但它更倾向于是VM直接执行用该语言写得代码,而不是转换成对应字节码来执行的方式(比如Javascript,不过这是我猜测的,书中说得是Tcl、Basic、Ruby这样的)。
以上这种划分,让人细思真的极恐,因为作者把很多很细节的东西都考察到了。本文最后,我们还会看到一个细思极恐的例子。
ABI和ISA简介
作为读书笔记,如果只是简单记录的话,那就太低级趣味了。我这里会顺带补齐一下在读书过程中碰到的其它我以前并不明确掌握的知识。比如,ISA、ABI到底是什么?

ABI和ISA大家经常提起,而且肯定都是信誓旦旦都知道的一副模样。我这次并没有从定义上去给ABI、ISA画圈圈。我们换个角度来看,这玩意到底影响了我们哪些地方?所以,上图就是按这个思路给大家整理了下。
VM的意义
注意,从这里开始,书中讨论的VM就是诸如JVM这样类型的虚拟机了 。
貌似我们从来没想过VM存在的意义。之前最多也只是好奇某厂某编译器宣传的过程中,VM的存在似乎有意无意貌似给抹掉了。而就在那个时候,我们也没有想过VM的价值。这其实反应了一个深层次的问题,很可能我们只是二把刀,一上来就想解放全人类....所以,书中关于这一部分的内容,我觉得就是立Flag,非技术外的意义很大。

下 个定论,如果要搞现代高级语言,绝对离不开VM的支持 。另外,作者也对比了实现一个JVM和实现一门语言的难度。就拿Java说事,知名或不知名的JVM历史上有好几个,但谈到支撑这门语言的周边(主要是说JDK),作者知道的也就三个,而且现在还活着的恐怕也只有OpenJDK了。以上,说明我们要搞一门中国人自己设计的编程语言,如果要做到和Java一样流行,也算是任重道远了。
VM的内部结构
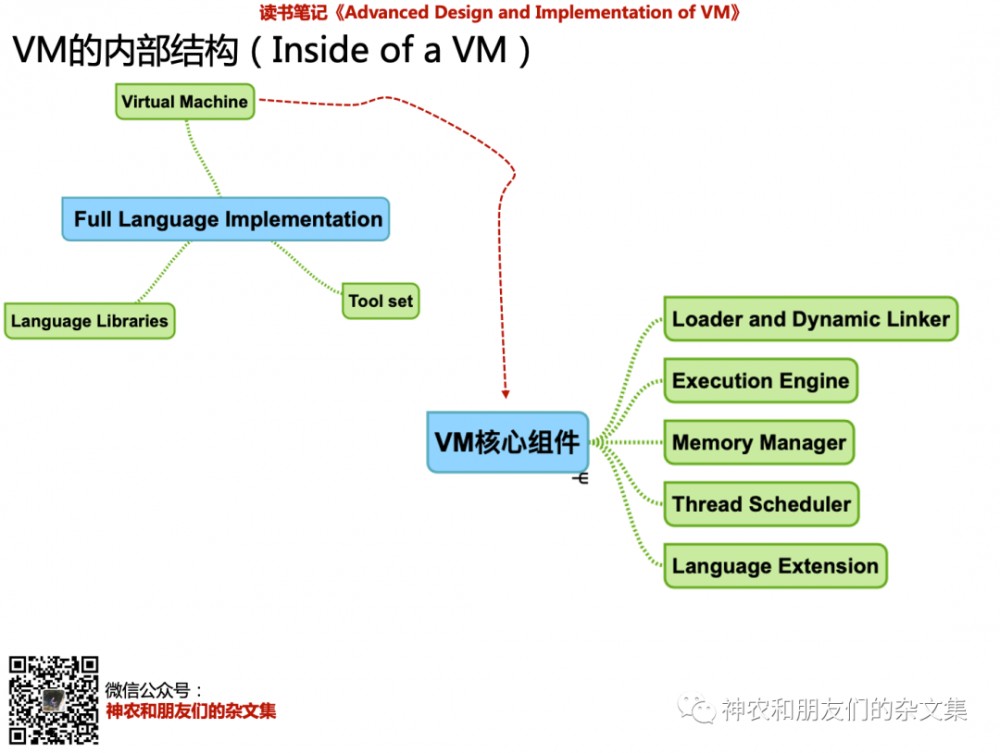
上面图里包含两个知识:
-
左边的蓝色框框:说明 一门语言的实现包括至少三个部分。即 VM 、语言库、工具集(用来调试,性能,打包等)。
-
右下边的蓝色框框:用来说明VM的核心组件。
讲VM的时候,为什么要提到语言呢?这隐含了一种关系,即VM是为语言服务的。基于这个逻辑,右边的VM将包括如下几个功能模块:
-
Loader and Dynamic Linker:用于 把程序加载,解析进来。 Linker 则用于链接到所引用的东西。建立模块A和其他模块的关系。例如,我们Java代码中的 import 第三方库和使用第三方库的 API ,在 VM 中怎么表达呢?这就是 Linker 的作用。
-
Execution Engine :解释执行、编译后执行,或者混合方式
-
Memory Manager :VM要管理的内存包括两部分, VM 自己的, APP 的。 MM 一般是考虑针对 APP 的。在 VM 情况下, app 一般只管分配, VM 来处理释放。这和那些Native程序(基本是指用C/C++编写的程序)不一样。在那些程序里, app 自己分配和释放内存。
-
Thread Scheduler :对硬件中多核或者操作系统上多线程资源的利用
-
Language Extension :整体来看,VM/语言中使用底层服务 (这里的底层服务,包括来自OS提供的功能,或者用C/C++编写的模块提供的功能) 有两种形式,一种是通过 VM 提供的 Runtime 服务( RuntimeService ),比如 new 一个对象,涉及到来自物理内存分配,但是这是由 VM 去干的。另外 一种是语言层面扩展,比如 JNI。
Native APP和基于VM的APP的比较
接下来,作者比较了Native APP和基于VM的APP。
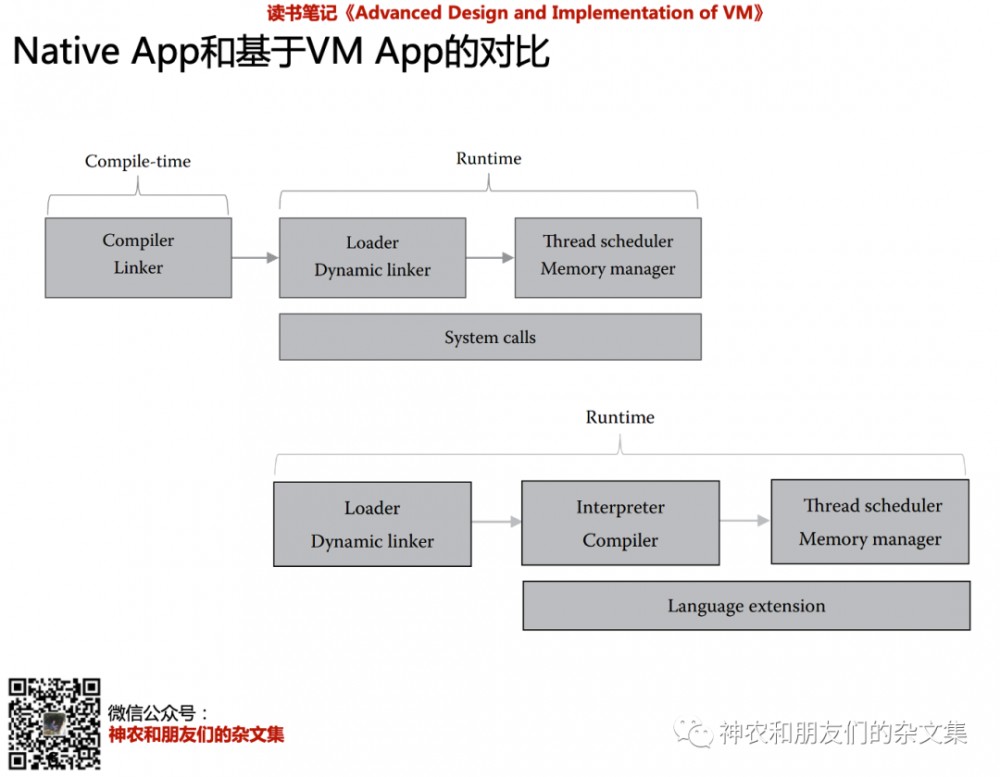
一般来说,
-
Native APP 大致上可分为 Compile-Time 和 Runtime 两个部分。代码中引用其他模块的地方,在 Compiler-Time中由Linker 负责解析引用关系。而运行的时候,需要一个Loader来加载被引用的模块。这个loader还需要把参数准备好,然后最后去调用APP的入口 main 函数。另外,Native APP一般来说会较为直接的和 OS打交道。比如Linux上的系统调用等 。
-
VM Based APP :则把 Loader 、 Linker 等合在一起Runtime(运行的时候)里来处理。
Virtual ISA
接着再来以Virtual ISA VM的角度考察下JVM。

关于Java bytecode,目前我看到的一本不错的书是右上角的。上篇公众号里也介绍过。
上图右下角,展示了Java和C语言的对比。稍微解释下:
-
图片中的第一行:Java语言转换成JVM Language(也就是Java bytecode),跑在JVM上。
-
图片中的第二行:C语言转换成x86汇编,跑在intel处理器上。
这个对比,其实就是Virtual ISA VM这种类型的VM叫Virtual ISA的直观解释了。
多说一句,要学习JVM的话,必须要 先掌握如下知识

VM中的数据结构(Data Structure in a VM)
在一本书刚开始不久的时候就要介绍VM中的数据结构是有些会吓到人的。但其实这时作者只想讨论下面三个东西:
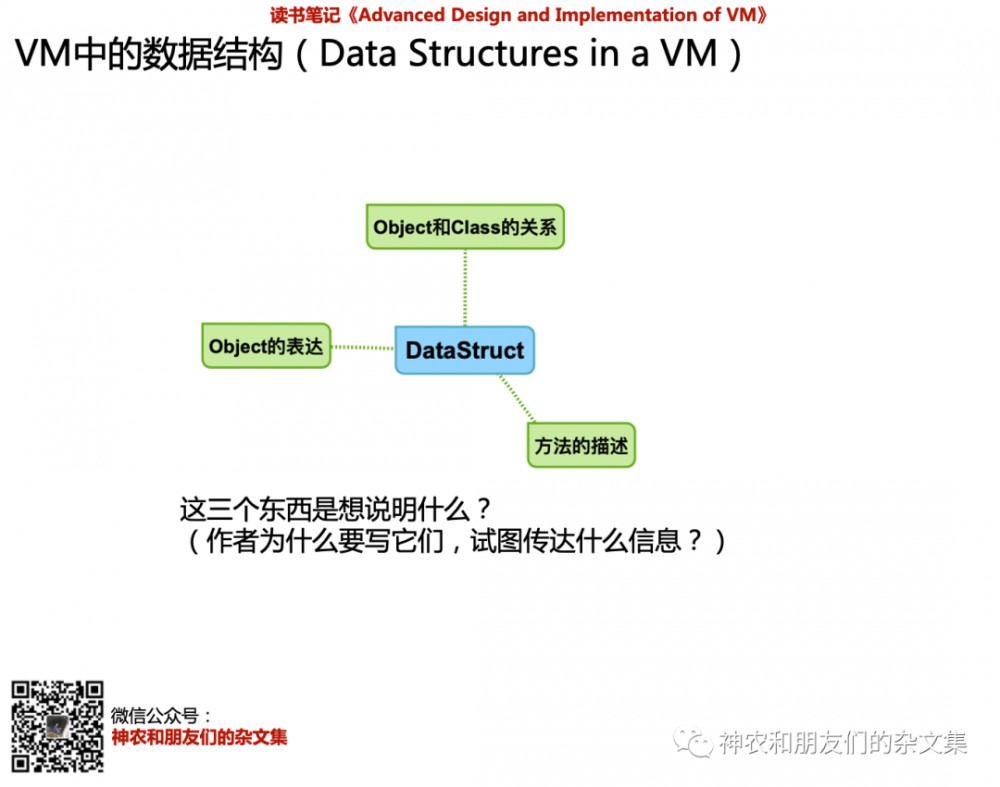
作者在此时想讨论三个东西(以JVM为例):
-
Object和Class的关系
-
Object在JVM中如何表达
-
方法在JVM中如何描述
我总结了Object和Class的关系,如下图:
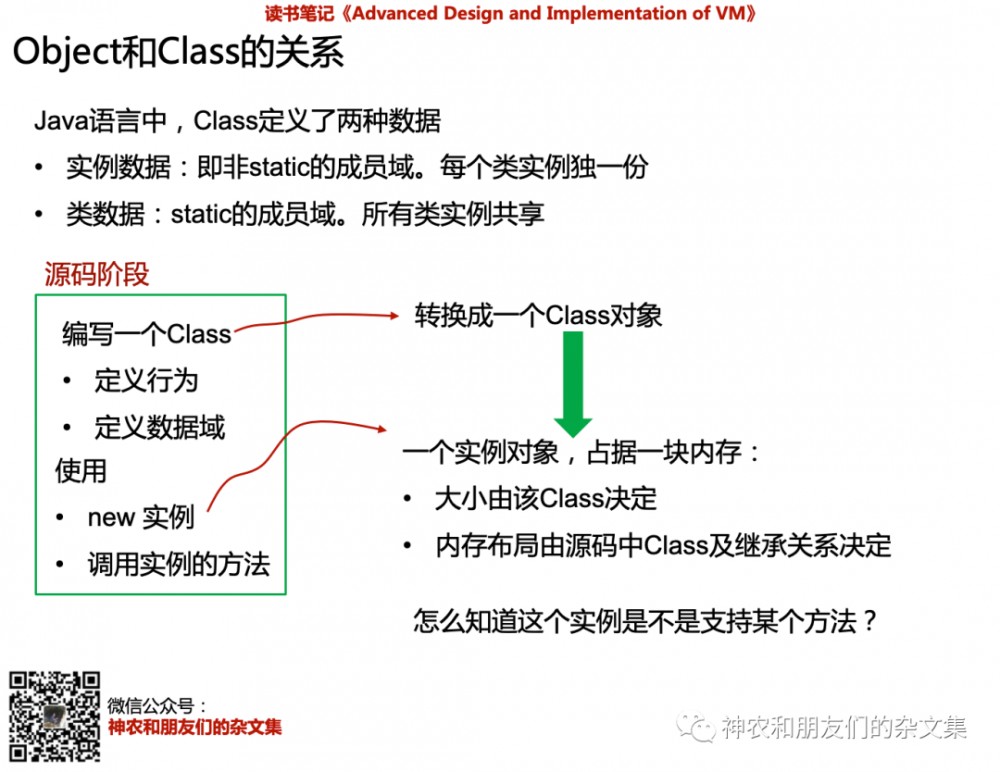
在写Java程序的时候,编写一个Class对开发者的感觉就是写一个”抽象“的东西。一般情况下,你是不会意识到JVM中还有一个对应的Class对象(由于我是C++程序员转过来的,而C++程序里没有Class对象。而且,OOP里好像也没有专门东西,Class更多是从抽象层面来探讨封装行为和属性)。但实际上运行在JVM中,VM需要将这个”抽象“的你写的Class先转换成一个Class对象。既而,这个Class对象摇身一变成为该Class实例的“工厂”。这就是VM中,Class和Object的关系
正如我上文中说的,OOP里并没有说非得有这么一个Class对象。所以,我对这部分知识做了一个小小的拓展,拿JS和Java做了一个对比。
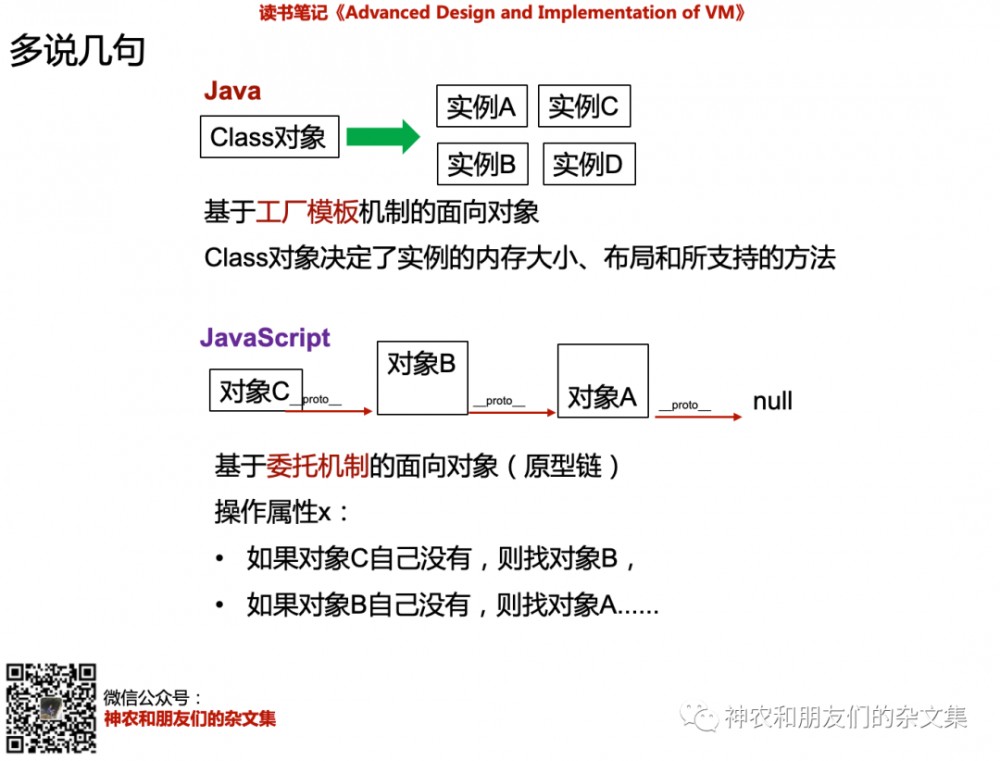
在Java语言中,在JVM里边来看,实例A/B/C/D必须从对应的Class对象里搞出来。我将其命名为“基于 工厂模板 机制的OOP”。但Object和Class的关系非得使用工厂模板机制吗?显然不是,对JS来说,它是一种“基于 委托机制 的OOP”,也就是绝大部分人又“熟得不能再熟”但其实我认为是没指出本质的“原型链”。不考虑VM实现、运行效率等问题,纯纯的在表达OOP这种关系上,我感觉JS比Java要进步很多。为毛非得一定要弄个Class?另外,ES6中为了方便相对“死脑筋”的Java或其他什么语言程序员理解并用好Js,也在JS里弄了一个Class的语法糖,从某种意义来说是灭自己“长处”。
接着来看Object如何在JVM中表达。
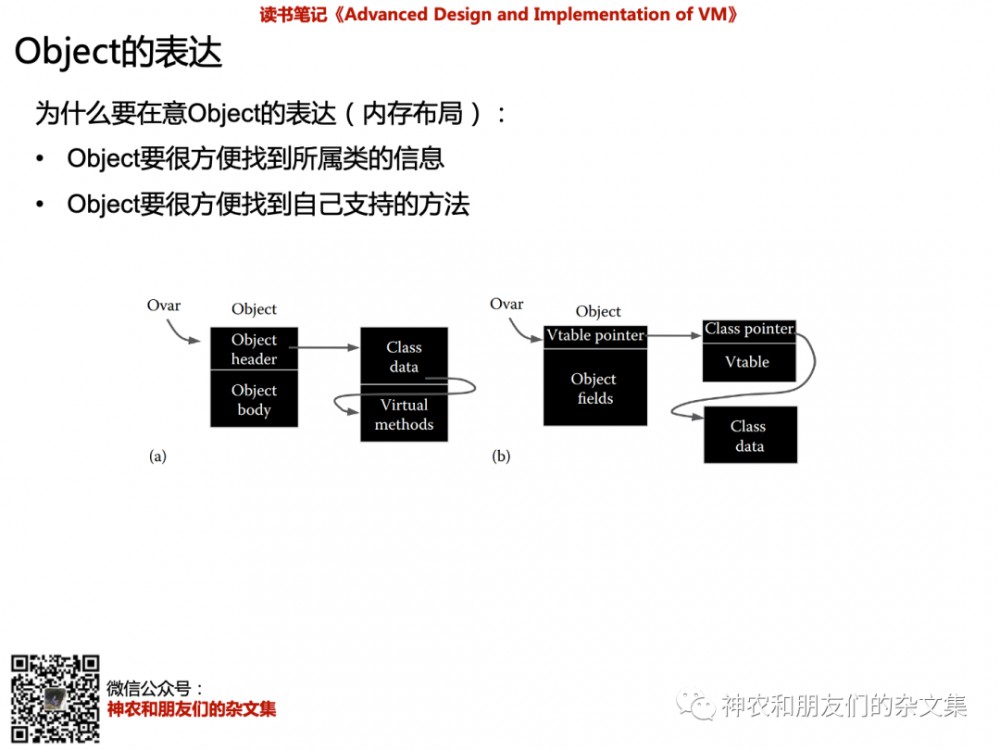
图中开篇明义讲了为什么要在意Object的表达,是因为两个原因。作者列举了两种常用的Object表达方式。目前常用的是第二种,就是带vtable的。这个地方的讲述比较单薄,各位不用深究。不过,我们看下ART中的Object和Class的数据结构。

其实,Class的信息才是最重要的。因为Class是实例的工厂嘛。
最后,我们看下方法在JVM中的描述,根据作者所说,方法的描述中要包含下图右边的三种信息。

以上是作者给的通用数据结构,我们可以看看ART是怎么设计的。

对比下来,所包含的信息和通用描述差不太多。ART中,方法由ArtMethod描述,因为ART虚拟机跑得是dex字节码,所以它有一些和dex有关的东西。
Execution Engine的设计
现在,我们把目光投向JVM中最重要的模块——执行引擎(EE)。先讨论EE的执行机制。

有两种执行机制,一个是编译执行,一个是解释执行。今天这篇文章先讲解释执行机制。JVM解释执行机制都有一个通用的代码框架,如上图右边中的循环所示。这个循环有个专业名称叫“dispatching loop”。
虽然上图内容很简单,但其背后有好多“深刻的知识”。我们先来正视一个问题: 为什么解释执行慢???

主要有两个原因:
-
“同样含义”的操作,高级别指令(比如java bytecode)比低级别指令涉及到的动作要多。这个我觉得大家都好理解,但文字不太好描述清楚。
-
第二个原因非常重要:因为解释执行的那个dispatching loop那坨代码无法充分利用CPU的分支预测。这里给了一个例子。一个简单的循环遍历一个数组,如果数组的元素大于128,则相加,否则继续循环。就这么一个玩意,如果数组事先排好序,则运行速度比未排序的快好几倍。对于这个事情的解释,可以看链接 https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array#11227902 。想了解分支预测的,可以看 https://www.zhihu.com/question/23973128 。
分支预测,简单来说就是CPU现在的设计是流水线,分了十几级流水线。要保证这十几级流水线都满负荷工作的话,最佳方式是把各级流水线的材料都准备好。如果材料准备错了(也就是分支预测失败),则这些流水线要清空,重新再读取指令,非常非常耽误时间。 目前,CPU的分支预测已经做到准确率高达96%以上。上面stackoverflow里有一个很形象的例子,我这里简单再加工描述下:
一个蒸汽火车,启动和停止都耗时。现在,你站在一个站台上,要做这么一个事情。火车从东边来的话,你得把开关调到A,火车从西边来的话,你得把开关调到B。好,你现在听到火车声了,但是没有办法知道它从哪个方向来。这样的话,你只能先让火车停下,确认它来的方向后,再选择开关调到A或者是B。显然,这样很耽误事。而如果你能知道火车(通过猜测或者经验得到)在这个时候一定是从东边来的话,就可以提前把开关调到A就行,火车也就不用停下来了。如果你的这个推测有96%的准确性,那就极好了。
现在,我们回答另外一个问题,为什么解释执行的那坨代码没有办法利用CPU的分支预测?这个问题不能直接回答,但可以看看dispatching loop的几种实现方式:

解释执行中分发实现方式之一——switch方式。ART里也有switch方式。switch方式可以用C语言实现,可移植很好,但速度相对慢。分支预测几乎不可行,因为几乎所有指令的处理都需要switch到对应的case,没法预测(大概解释下,预测是指CPU估计下一条指令是什么,提前准备好下一条指令相关的信息/数据,显然,大家能感觉到这玩意在dispatching loop里不太好预测)。
第二种分发实现方式是Direct Call Threading。

这种模式基本含义是每个指令的处理逻辑封装成一个函数,vPC(virutal pc)运行到哪,直接执行对于的函数即可。这里就没有swich那样的跳转了,所以速度相对比switch快(这部分内容涉及到一个indirect jump的知识,参考上图右下的解释)。
dispatching loop最后一种常见实现模式是Direct Threading,如下图所示:

以上三种实现方式来自 http://www.cs.toronto.edu/~matz/dissertation/matzDissertation-latex2html/node6.html。 Direct Threading和Direct Call Threading的叫法中都有个Threading,我还没深究其含义。我个人觉得知道Direct/Direct Call差不多就行了。Direct Call是直接调用指令码对应的函数。而Direct则是直接goto到处理逻辑处,不涉及函数调用。显然,Direct比Direct Call又强那么一些。ART 10中,Direct Threading模式是汇编实现的。见上图右侧。
最后,今天本文的最后,我们看看针对dispatching loop,有什么优化的地方吗?书中提到两种方式:

两种方式:
-
一个是super instruction,即将一些指令合并成一个超级指令。但局限性很大,因为bytecode指令最多只有255个。另外,我对比了下dex中的quick指令。按super instructiond的定义,这些quick指令并不是多个指令的合集,所以不算super instruction。
-
还有一个是selective inline。思路是把指令的处理逻辑编译成机器码,在这个基础上呢,还可以将多个指令的机器码合并。执行的时候,直接跳到这些指令的机器码去执行。所以叫selective inline。
现在,我们揭秘下这本书我发现的第二处细思极恐的地方。结合上面说的,初看起来selective inline和jit看起来一毛一样啊。那为什么叫inline不是Jit呢?我是翻了很久才知道,就是上图中右下框中的原文。其中有一个红色箭头指向的“ a bytecode"。jit不是以单个bytecode为单位的,所以,这里叫selective inline,而不是jit,虽然二者前N眼看起来非常类似(我之前一直纳闷啥叫selective inline呢,inline是个什么鬼)。
后续的安排
我想重点树立起和JVM密切有关的知识体系。有了ART源码打底子,我相信这条路走得通。对JVM的掌握是非常有必要的,我感觉国家层面在底层基础核心技术上会加大投入,JVM是一个非常合适的突破口。
最后的最后
-
我期望的结果不是朋友们从我的书、文章、博客后学会了什么知识,干成了什么,而应该是说, 神农,我可是踩在你的肩膀上的喔 。
-
关于学习方面的问题,我已经讨论完了。 后面这个公众号将对一些基础的技术,新技术做一些学习和分享。也欢迎你的投稿 。不过,正如我在公众号“联系方式”里说的那样——郑渊洁在童话大王《智齿》里有一句话令我印象深刻,大意是“我有权保持沉默,但你说的每一句话都可能成为我灵感的源泉”。 所以,影响不是单向的,很可能我从你那学到的东西更多 。

神农和朋友们的杂文集
长按识别二维码关注我们
正文到此结束
- 本文标签: java struct 开发者 代码 Select src 文章 id linux ip UI NFV 遍历 苹果 朋友们 物理内存 VMware cat SDN 解析 总结 python MQ node 线程 多线程 Android 开发 Architect IO windows API HTML 操作系统 ACE 图片 字节码 tab 突破 管理 程序员 参数 博客 Service JVM 源码 js 数据 App 二维码 http 处理器 回答 编译 https 调试 时间 实例 主机 JavaScript 本质
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

