Servlet 中文乱码问题解析及详细解决方法
使用 servlet 向客户端浏览器回送中文时,经常出现中文乱码的问题,这里给大家完完全全地搞明白:
一、基本常识
-
中文系统默认是 GBK 编码(GBK是对GB2312的补充,包含它)
-
需要处理编码问题的地方:
- 浏览器发送请求(Request)时,所用的编码格式;
- Web 服务器响应(Response)回送的数据,所用的编码格式;
- 浏览器解析响应回送的数据,所用的编码格式;
- 又分为两种情况:
- 请求发生乱码往往是 servlet 程序获取请求信息时,获取的信息乱码,问题产生在服务端;
- 而客户端浏览器出现,往往是2、3两处的编码格式不一造成的;
-
查看平台默认字符编码方法:java.nio.charset.Charset.defaultCharset();
-
HttpServletResponse 类中的 getOutputStream() 获取的字节节流,用于向浏览器输出二进制数据(图片、视频等任何形式数据);而 getWriter() 获取的是字符输出流,用于输出文本数据,二者不能同时使用;
-
getBytes() 方法通过平台默认字符集进行编码,可传传递参数指定字符集(如 getBytes("UTF-8"))
二、了解编码的过程
以我们要解决的问题角度出发: 编码 是将文字按照一种规范转变成另一种形式的过程;而 解码 ,是编码的逆过程;这中间的依据也就是那个规范,就是字符集(编码表,如 UTF-8、GBK)。
编码时,程序从字符集中寻找字符在此字符集里的一个"编号"(往往是一种更利于计算机使用字符);这些编号组成的数据,无论传递到什么平台,最后接收数据的平台使用,同一字符集进行解码,就能获取到原本的数据,过程:用接收到的编码数据,从字符集中寻找对应表示的字符进行还原,最终数据的完美传递。
三、解决乱码问题
Request 乱码
从浏览器发起的访问方式有三种:
- 在地址栏直接输入URL访问:浏览器默认将请求参数按 UTF-8 进行编码,
- 点击超链接访问:浏览器将参数按照当前页面的显示编码进行编码
- 提交表单访问:同上
网上常用的设置表单的方法: request.setCharacterEncoding("UTF-8") 只对 POST 请求方式有效,所以解决请求乱码要针对两个情况:
GET 方式
get请求乱码解决办法一: 修改服务器端对URI参数的默认编码
get请求乱码办法一:修改服务器端对URI参数的默认编码
在tomcat的server.xml中,设置元素的属性URIEncoding=”UTF-8”即可。(默认没有设置此属性)
扩展:
1.设置元素的属性useBodyEncodingForURI=“true”,意思是请求体和uri使用相同的编码格式。
通过设置这两个属性,既可以解决get方式的乱码,又可以解决post方式的乱码。
2.通过修改server.xml指定服务器对get和post统一按照utf-8解码,要求tomcat管理下的所有web应用都要使用utf-8编码,即所有的jsp、html页面都必须使用utf-8编码。
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"
URIEncoding="UTF-8" useBodyEncodingForURI="true"/>
get请求乱码办法二: 逆向操作
参数从浏览器到服务器,经过客户端编码,服务器端解码,最终成为乱码。那我们将乱码进行相反的编解码,即可得到正常的参数值。此时注意上文提到的编码规律总结,只有源头对了,才能成功解决问题。
String name = request.getParameter("name");//得到乱码的数据
name = new String(name.getBytes("GBK"),"utf-8");
//将得到的数据进行GBK方式解码,然后把得到的字节再通过UTF-8编码,得到正常的name值
get请求乱码方法三: 手动编码解码
在JSP页面中先把中文编码后再提交,服务器获取后再按照同样的方式解码
//场景:从网页下载,文件名为中文
...
String filePath = "D://javacode//javaweb_Servlet2//response//src//main//webapp//哈哈11.xml";
// 通过一些方法,从路径中提取出 文件名:
//通过获取最后一个 / 的脚标 + 1 确定文件名的第一个字符索引,而后从此索引开始截取字符串,就是文件名
String fileName = filePath.substring(filePath.lastIndexOf("//") + 1);
//URLEncoder.encode() 方法设置以指定字符集对文件名进行编码
resp.setHeader("Content-Disposition","attachment;filename=" + URLEncoder.encode(fileName,"utf-8"));
...
POST 方式
post方式提交的参数存在于请求体中,浏览器将参数按照当前页面的显示编码进行编码页面的编码方式一般情况下已经被设置成了UTF-8,只需要修改服务端解码方式(与浏览器页面编码方式一致) ```java
request.setCharacterEncoding(“UTF-8”);
Response 乱码
实际遇到更多的乱码情况是浏览器接收响应数据的乱码,我们需要了解发生乱码的流程:
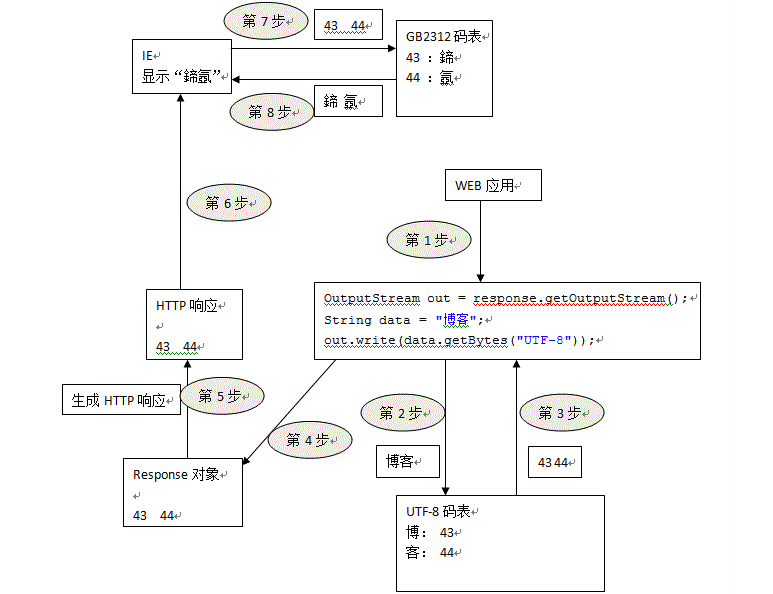
首先 getBytes() 以 UTF-8 字符集对字符串进行编码,并写入响应对象,响应数据回送至浏览器,浏览器默认使用平台默认编码(中文系统)进行解码,用 GB 码表解码 UTF-8 的编码的数据,结果就是出现乱码。
所以我们要做的使: 响应所回送数据所用字符集 和 浏览器用来解析回送数据所用字符集相同
设置浏览器的解码格式:
response.setHeader("content-type","text/html;charset=UTF-8");
//或
response.setContentType("text/html;charset=utf-8");
大白话说就是用 content-type 响应头,告诉浏览器我回送过来的数据时 text/html 类型,要用 UTF-8 字符集解码;
设置好浏览器用于解析响应回送数据的字符集后,现在要设置响应回送的数据字符集,分为两种情况,也就是最开始提到的,处理字节和字符流数据是有差异的:
- 使用 response.getWriter() 流写出的的数据乱码解决方式:
//设置将发送到客户端的响应 的字符编码,只能用于设置 getWritet()的字符编码
response.setCharactEncoding("UTF-8");
//同时设置浏览器的解码方式
response.setHeader("content-type","text/html;charset=UTF-8");
需要在调用 getWriter() 方法前 和 响应提交前使用
- 使用 response.getOutputStream() 流写出的数据乱码解决方式:
//服务端对字符进行编码的时候,指定编码方式
response.getOutputStream().write("汉字".getBytes("UTF-8"));
//同时设置浏览器的解码方式
response.setHeader("content-type","text/html;charset=UTF-8");
字符响应流只用用来输出字符,而字节响应流可以用来输出任何东西
四、扩展:
- 查看当前响应头所设置的字符编码(没有获取到字符集类型说明是默认的):response.getContentType()
- 可使用 response.writer().print() 传递 HTML 标签代码间接设置网页的编码格式,如:
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//直接向网页输出 HTML 标签代码
response.getWriter().println("<meta http-equiv='Content-Type' content='text/html; charset=utf-8'>");
}
- 为了避免可能的失误,直接将设置编码相关代码放在最前面(无论是后端还是前端)
参考: response与request中文乱码问题及解决方式 Servlet 中文乱码问题及解决方案剖析
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

