Java常见面试题,持续更新...
List集合类
ArrayList和LinkedList的区别
从底层数据结构以及访问、添加、删除的效率分别说明
注意: ArrayList当数组大小不满足时需要增加存储能力,就要 将已经有数组的数据复制到新的存储空间
Vector
Vector也是通过数组实现的,但它支持线程同步,避免同时写引起的不一致性,实现同步需要很高的开销,因此它的访问比ArrayList慢
Set 集合类
Set排序子类、HashSet、hashCode()、equals的关系
- HashSet:依靠HashCode和equals方法判断重复,首先判断哈希值,如果哈希值相同再判断equals;相同哈希值但equals不同的,放在一个bucket里,;它是无序的
- TreeSet:二叉树原理;有序的,需要实现Comparable接口;
- LinkedHashSet:继承了HashSet,方法接口与HashSet相同;底层使用LinkedHashMap 来保存所有元素;属于有序, 增加顺序为保存顺序
Map类
HashMap的底层实现原理
jdk1.7中的HashMap

HashMap是一个 数组 ,数组的每一个元素是一个 Entry的链表
每一个Entry对象包括了 Key , value , hash值 和指向下一个元素的 next
HashMap包括两个构造参数:
1. capacity :当前数组的容量,可扩容,扩容后的大小为当前数组大小的两倍
2. loadFactor :负载因子,默认0.75
HashMap(int initialCapacity, float loadFactor)
threshold :扩容的阈值,等于 capacity * loadFactor
JDK1.8中,HashMap采用 位桶+链表+红黑树 实现,当 链表长度超过阈值(8)时,将链表转换为红黑树 ,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
(1). HashMap 允许有一个null的key,允许多个value为null
ConcurrentHashMap
- ConcurrentHashMap支持并发操作,线程安全
- 由一个个Segment组成,是 一个Segment数组 ,Segment通过 继承ReentrantLock进行加锁 ,每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全.
- 一个Segment相当于一个HashMap
构造参数:
concurrencyLevel :并行数,也即segment的个数,默认16,初始化后不可更改或扩容;一个segment同时只允许一个线程操作, 16个segment允许16个线程在各种不同的segment上并发写;
HashMap和HashTable的区别
HashTable是上古版本的遗留类,现在很少使用,
- 继承自 Dictionary类
- 线程安全 ,但并发性不如ConcurrentHashMap,因为后者引入了分段锁
- HashTable 不允许key为null
- HashMap把Hashtable的 contains方法 去掉了,改成containsValue和containsKey,
- 初始容量和扩容:HashTable在不指定容量的情况下的默认容量为11,而HashMap为16, Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂 。 Hashtable扩容时,将容量变为 原来的2倍加1 ,而HashMap扩容时,将容量 变为原来的2倍 。
TreeMap(可排序)
- 实现SortedMap 接口,能够把它保存的记录 根据键排序
- key 必须实现Comparable 接口或者在构造TreeMap 传入自定义的Comparator
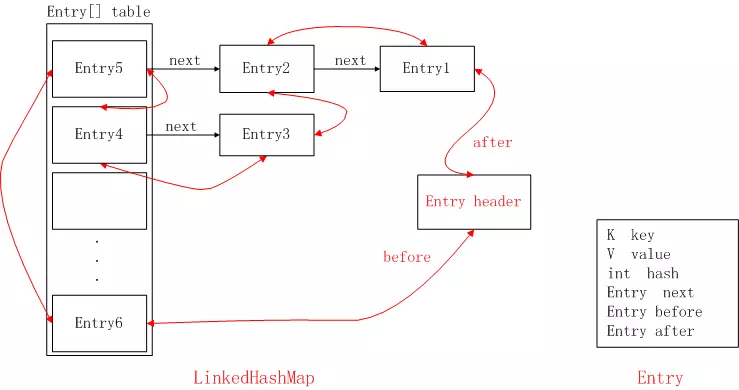
LinkHashMap(记录插入顺序)
它继承HashMap、底层使用哈希表与双向链表来保存所有元素
Entry元素比HashMap多了:
Entry<K, V> before
Entry<K, V> after
before、After是用于维护Entry插入的先后顺序的。
大概的图:
正文到此结束
热门推荐









相关文章





Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

