源码分析Dubbo编码解码实现原理---Dubbo协议编码
本节主要介绍了 Dubbo 协议的编码方式,涉及协议头、协议体具体的编码规则,默认使用 Dubbo 协议,其核心类图如下:
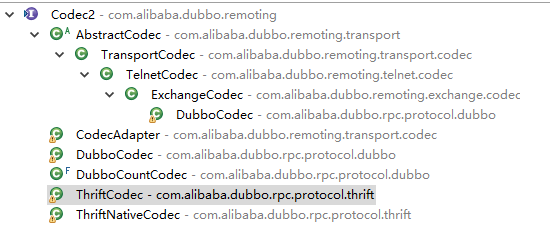
在 Dubbo 整个框架中,codec2 的可选值为 dubbo、thrift,本文将重点分析 Dubbo 协议的编码解码。
本文主要以 Dubbo 协议为例进行展开,其他通信方式,例如 Thrift 就不做过多分析,其实现思路基本是样的,Dubbo 协议的编解码实现类为 DubboCodec。
@SPI
public interface Codec2 {
@Adaptive({Constants.CODEC_KEY})
void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException;
@Adaptive({Constants.CODEC_KEY})
Object decode(Channel channel, ChannelBuffer buffer) throws IOException;
enum DecodeResult {
NEED_MORE_INPUT, SKIP_SOME_INPUT
}
}
复制代码
Codec2主要定义两个接口,一个枚举类型,
- void encode(Channel channel, ChannelBuffer buffer, Object message) 编码,在客户端发送消息时,需要将请求对象按照一定的格式(二进制流)将对象编码成二进制流,以便消息接收端能正确从二进流中按照格式解码出一个完整的请求信息。
- Object decode(Channel channel, ChannelBuffer buffer) : 解码,在消息接受端,按照协议的规范,从二进制流中解码出一个一个的请求信息,以便处理。
- DecodeResult.NEED_MORE_INPUT 在解码过程中如果收到的字节流不是一个完整包时,结束此次读事件处理,等待更多数据到达, SKIP_SOME_INPUT,忽略掉一部分输入数据。
编码解码实现类层次职责说明(从顶到下):
-
Codec2:编码解码根接口。
-
AbstractCodec:编码解码抽象实现类,主要定义与协议无关的帮助类。
- protected static void checkPayload(Channel channel, long size) 检查负载长度是否符合协议规范。
- protected Serialization getSerialization(Channel channel) 根据序列化协议配置,获取对应的序列化实现类。
- protected boolean isClientSide(Channel channel) 判断当前是否是客户端
- protected boolean isServerSide(Channel channel) 判断当前是否是服务端
● TransportCodec 传输编码解码器,Codec2的具体实现类。
● TelnetCodec Dubbo telnet协议实现类。
● ExchangeCodec:交互层编码器,其他具体协议的基础类,可以看出是业务协议的模板类
● DubboCodec:dubbo协议。 既然ExchangeCodec是业务协议,包含Dubbo协议的模板实现类,我们就从ExchangeCodec开始,探究 Dubbo编码解码实现原理。
1、ExchangeCodec核心属性
// header length.
protected static final int HEADER_LENGTH = 16;
// magic header.
protected static final short MAGIC = (short) 0xdabb;
protected static final byte MAGIC_HIGH = Bytes.short2bytes(MAGIC)[0];
protected static final byte MAGIC_LOW = Bytes.short2bytes(MAGIC)[1];
// message flag.
protected static final byte FLAG_REQUEST = (byte) 0x80;
protected static final byte FLAG_TWOWAY = (byte) 0x40;
protected static final byte FLAG_EVENT = (byte) 0x20;
protected static final int SERIALIZATION_MASK = 0x1f;
复制代码
属性解读如下:
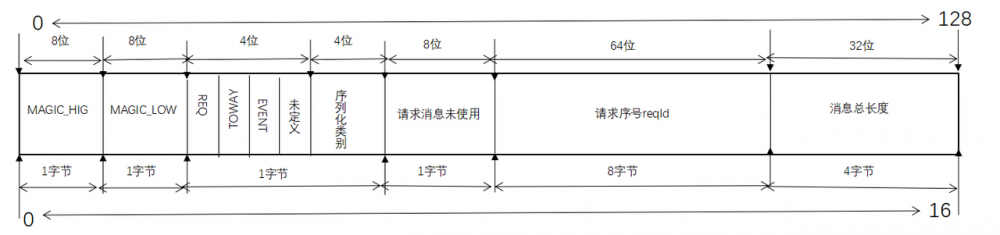
- HEADER_LENGTH :协议头部长度,共16个字节。
- MAGIC :魔数,固定为0xdabb,2个字节。
- MAGIC_HIGH :魔数的高8位。
- MAGIC_LOW :魔数的低8位。
- FLAG_REQUEST :消息请求类型为消息请求。
- FLAG_TWOWAY :消息请求类型为心跳。
- FLAG_EVENT :消息请求类型为事件。
- SERIALIZATION_MASK :serialization掩码。
2、ExchangeCodec编码实现原理
ExchangeCodec#encode
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException { // @1
if (msg instanceof Request) { // @2
encodeRequest(channel, buffer, (Request) msg);
} else if (msg instanceof Response) { // @3
encodeResponse(channel, buffer, (Response) msg);
} else {
super.encode(channel, buffer, msg); // @4
}
}
复制代码
代码@1:参数说明:
- Channel channel:Dubbo网络通道的抽象,底层实现有NettyChannel、MinaChannel;
- ChannelBuffer buffer:buffer抽象类,屏蔽netty,mina等底层实现差别;
- Object msg:请求对象、响应对象或其他消息对象。
代码@2:如果msg是Request,则按照请求对象协议编码。
代码@3:如果是响应对象,则按照响应协议编码。
代码@4:如果是业务类对象(请求、响应),则使用父类默认的编码方式。
2.1 ExchangeCodec#encodeRequest
ExchangeCodec#encodeRequest
Serialization serialization = getSerialization(channel); // @1
// header.
byte[] header = new byte[HEADER_LENGTH]; // @2
// set magic number.
Bytes.short2bytes(MAGIC, header); // @3
// set request and serialization flag.
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId()); // @4
if (req.isTwoWay()) header[2] |= FLAG_TWOWAY;
if (req.isEvent()) header[2] |= FLAG_EVENT;
// set request id.
Bytes.long2bytes(req.getId(), header, 4); // @5
复制代码
Step1:初始化协议头,同时填充部分字段。header[0]、header[1]、header[2]、header[4-11],注意,header[3]未填充。 代码@1:获取通道的序列化实现类。
代码@2:构建请求头部,header数组,长度为16个字节。
代码@3:首先填充头部的前两个字节,协议的魔数。header[0] = 魔数的高8个字节,header[1] = 魔数的低8个字节。
代码@4:头部的第3个字节存储的是消息请求标识与序列化器类别,那这8位是如何存储的呢?
首先看一下消息请求标志的定义:
protected static final byte FLAG_REQUEST = (byte) 0x80; // 其二进制为 1000 0000 protected static final byte FLAG_TWOWAY = (byte) 0x40; // 其二进制为 0100 0000 protected static final byte FLAG_EVENT = (byte) 0x20; // 其二进制为 0010 0000 protected static final int SERIALIZATION_MASK = 0x1f; // 复制代码
其序列化的掩码,为什么是这样的呢?
serialization.getContentTypeId() 返回的类型如下: CompactedJavaSerialization : 4 二进制为0000 0010 FastJsonSerialization : 6 二进制为0000 0110 FstSerialization : 9 二进制为0000 1001 Hessian2Serialization : 2 二进制为0000 0010 JavaSerialization : 3 二进制为0000 0011 KryoSerialization : 8 二进制为0000 1000 NativeJavaSerialization : 7 二进制为0000 0111 复制代码
结合代码 header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId()) 可以得出一个结论, header [2] 为 8 字节标志位,前 4 位,表示消息请求类型,依次为:请求、twoway、event,保留位;后4位:序列化的类型,也就是说 dubbo 协议只支持 16 中序列化协议。
代码@5:head[4]- head[11] 共 8 个字节为请求ID。Dubbo 传输使用大端字节序列,也就说在接受端首先读到的字节是高位字节。
public static void long2bytes(long v, byte[] b, int off) {
b[off + 7] = (byte) v;
b[off + 6] = (byte) (v >>> 8);
b[off + 5] = (byte) (v >>> 16);
b[off + 4] = (byte) (v >>> 24);
b[off + 3] = (byte) (v >>> 32);
b[off + 2] = (byte) (v >>> 40);
b[off + 1] = (byte) (v >>> 48);
b[off + 0] = (byte) (v >>> 56);
}
ExchangeCodec#encodeRequest
//encode request data.
int savedWriteIndex = buffer.writerIndex();
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer); // @1
ObjectOutput out = serialization.serialize(channel.getUrl(), bos); // @2
if (req.isEvent()) { // @3
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
int len = bos.writtenBytes(); //@4
checkPayload(channel, len);
Bytes.int2bytes(len, header, 12); //@5
复制代码
Step2:编码请求体(body),协议的设计,一般是基于 请求头部+请求体构成。
代码@1:对 buffer 做一个简单封装,返回 ChannelBufferOutputStream 实例。
代码@2:根据序列化器,将通道的 URL 进行序列化,变存入 buffer 中。
代码@3:根据请求类型,事件或请求对 Request.getData() 请求体进行编码,encodeEventData、encodeRequestData 不同的编码器会重写该方法,下文详细看一下 DubboCode 的实现。
代码@4:最后得到bos的总长度,该长度等于 ( header + body )的总长度,也就是一个完整请求包的长度。
代码@5:将包总长度写入到 header 的 header[12-15] 中。从 ExchangeCodec#encodeRequest 这个方法可以得知,Dubbo 的整体传输协议由下图所示:
2.3 Dubbo协议体编码
2.3.1 Dubbo协议请求体(body)编码规则
在 ExchangeCodec#encodeRequest 中,将会调用 encodeRequestData 对 body 进行编码。
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data) throws IOException {
RpcInvocation inv = (RpcInvocation) data;
out.writeUTF(inv.getAttachment(Constants.DUBBO_VERSION_KEY, DUBBO_VERSION));
out.writeUTF(inv.getAttachment(Constants.PATH_KEY));
out.writeUTF(inv.getAttachment(Constants.VERSION_KEY));
out.writeUTF(inv.getMethodName());
out.writeUTF(ReflectUtils.getDesc(inv.getParameterTypes()));
Object[] args = inv.getArguments();
if (args != null)
for (int i = 0; i < args.length; i++) {
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
out.writeObject(inv.getAttachments());
}
复制代码
该方法,依次将 dubbo、服务 path(interface name)、版本号、方法名、方法参数类型描述,参数值、附加属性(例如参数回调等,该部分会在服务调用相关章节重点分析)。上述内容,根据不同的序列化实现,其组织方式不同,当然,其基本组织方式(标记位、长度 、 具体内容),将在下节中重点分析序列化的实现。
2.3.2 Dubbo响应数据包编码规则
protected void encodeResponseData(Channel channel, ObjectOutput out, Object data) throws IOException {
Result result = (Result) data;
Throwable th = result.getException();
if (th == null) {
Object ret = result.getValue();
if (ret == null) {
out.writeByte(RESPONSE_NULL_VALUE);
} else {
out.writeByte(RESPONSE_VALUE);
out.writeObject(ret);
}
} else {
out.writeByte(RESPONSE_WITH_EXCEPTION);
out.writeObject(th);
}
}
复制代码
1字节(请求结果),取值:RESPONSE_NULL_VALUE:表示空结果;RESPONSE_WITH_EXCEPTION:表示异常,RESPONSE_VALUE:正常响应。N字节的请求响应,使用readObject读取即可。
3、ExchangeCodec 解码实现原理
ExchangeCodec#decode
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
int readable = buffer.readableBytes();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)]; // @1
buffer.readBytes(header); // @2
return decode(channel, buffer, readable, header); // @3
}
复制代码
代码@1:创建一个byte数组,其长度为 头部长度和可读字节数取最小值。
代码@2:读取指定字节到header中。
代码@3:调用decode方法尝试解码。
ExchangeCodec#decode
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) 复制代码
Step1:解释一下方法的参数:
- Channel channel :网络通道
- ChannelBuffer buffer : 通道读缓存区
- int readable :可读字节数。
- byte[] header :已读字节数,(尝试读取一个完整头部)
ExchangeCodec#decode
// check magic number.
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
复制代码
Step2:检查魔数,判断是否是 dubbo 协议,如果不是 dubbo 协议,则调用父类的解码方法,例如 telnet 协议。如果至少读取到一个字节,如果第一个字节与魔数的高位字节不相等或至少读取了两个字节,并且第二个字节与魔数的地位字节不相等,则认为不是 dubbo 协议,则调用父类的解码方法,如果是其他协议的化,将剩余的可读字节从通道中读出,提交其父类解码。
ExchangeCodec#decode
// check length.
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
复制代码
Step3:如果是 dubbo 协议,判断可读字节的长度是否大于协议头部的长度,如果可读字节小于头部字节,则跳过本次读事件处理,待读缓存区中更多的数据到达。
ExchangeCodec#decode
// get data length.
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
复制代码
Step4:如果读取到一个完整的协议头,然后读取消息体长度,如果当前可读自己小于消息体 + header 的长度,返回 NEED_MORE_INPUT, 表示放弃本次解码,待更多数据到达缓冲区时再解码。
ExchangeCodec#decode
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len); // @1
try {
return decodeBody(channel, is, header); // @2
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is); // @3
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
复制代码
代码@1:创建一个ChannelBufferInputStream,并限制最多只读取len长度的字节。
代码@2:调用decodeBody方法解码协议体。
代码@3:如果本次并未读取len个字节,则跳过这些字节,保证下一个包从正确的位置开始处理。
这个其实就是典型的网络编程(自定义协议)的解码实现。由于本文只关注 Dubbo 协议的解码,故 decodeBody 方法的实现,请看 DubboCodec#decodeBody。
3.1 DubboCodec#decodeBody 详解
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK); Serialization s = CodecSupport.getSerialization(channel.getUrl(), proto); // get request id. long id = Bytes.bytes2long(header, 4); 复制代码
Step1:根据协议头获取标记为(header[2])(根据协议可知,包含请求类型、序列化器)。
DubboCodec#decodeBody
if ((flag & FLAG_REQUEST) == 0) { // @1
// decode response.
Response res = new Response(id); // @2
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(Response.HEARTBEAT_EVENT); // @3
}
// get status.
byte status = header[3]; // @4
res.setStatus(status);
if (status == Response.OK) {
try {
Object data;
if (res.isHeartbeat()) {
data = decodeHeartbeatData(channel, deserialize(s, channel.getUrl(), is));
} else if (res.isEvent()) { // @5
data = decodeEventData(channel, deserialize(s, channel.getUrl(), is));
} else {
DecodeableRpcResult result;
if (channel.getUrl().getParameter(
Constants.DECODE_IN_IO_THREAD_KEY,
Constants.DEFAULT_DECODE_IN_IO_THREAD)) { // @6
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
result = new DecodeableRpcResult(channel, res, // @7
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode response failed: " + t.getMessage(), t);
}
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
} else {
res.setErrorMessage(deserialize(s, channel.getUrl(), is).readUTF());
}
return res;
}
复制代码
Step2:解码响应消息请求体。 代码@1:根据 flag 标记相应标记为,如果与 FLAG_REQUEST 进行逻辑与操作,为 0 说明不是请求类型,那对应的就是响应数据包。
代码@2:根据请求ID,构建响应结果。
代码@3:如果是事件类型。
代码@4:获取响应状态码。
代码@5:如果是心跳事件,则直接调用 readObject 完成解码即可。
代码@6:获取 decode.in.io 的配置值,默认为 true,表示在 IO 线程中解码消息体,如果 decode.in.io 设置为 false,则会在 DecodeHanler 中执行(受 Dispatch 事件派发模型影响)。
代码@7:不在 IO 线程池中完成解码操作,实现方式也就是不在 io 线程中调用 DecodeableRpcInvocation#decode 方法。
上述介绍了协议解码的经典实现流程,下文就不详细去探究具体针对 dubbo 协议进行解码,因为只要从一个完整的二进制流(ByteBuffer)按格式进行字节的读取,主要就是针对 ByteBuffer API 的应用。
最后,亲爱的读者朋友们,以上就是本文的全部内容了,Dubbo协议以及网络编程关于自定义协议的技巧是否Get到了,欢迎留言讨论。原创不易,莫要白票,请你为本文点赞个吧,这将是我写作更多优质文章的最强动力。
如果觉得文章对你有点帮助,请扫描如下二维码,第一时间阅读最新推文,回复【源码】,将获得成体系剖析JAVA系主流中间件的源码分析专栏。

正文到此结束
- 本文标签: 朋友们 服务端 https 数据 CTO final ACE IO ip UI CEO 参数 http ORM heartbeat 配置 时间 二维码 ECS constant 类图 mina cat 代码 组织 ask Transport stream db 线程 Netty value src message 缓存 源码 tar API key 线程池 模型 协议 NSA json client 文章 id java js IDE 实例 dubbo
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

