【每日鲜蘑】脱离业务场景的压测都是耍流氓
很多项目中,压力测试都是耍流氓……
为什么要压测
这个问题有很多答案,而每个人内心的答案可能都是不同的。比如,老板要我耍流氓……
-
项目经理说要压测一下;
-
客户要求提供压测报告;
-
我就是想知道自己写的程序是多么牛掰;
-
闲着无聊,压测下看看效果;
-
始终不肯相信自己的写得代码性能这么低,我要自己压测下看看;
-
……
哪些需要压测
做外包项目的大概会懂,压测的目的只是为了一份漂亮的“压测报告(交付物)”。但是,很多场景其实需要进行压力测试的。
新技术的调研
一个新的技术引入之前,需要做好评估,压测只是其中一个阶段。
新版本的性能
如果很勤快,比如某些中间件的版本升级,都需要进行简单的压测,这样可以排除外部依赖的性能瓶颈。
参数的变更
参数的调整很可能带来一些意想不到的问题,比如 JVM 调整了垃圾回收策略、TCP 改为了 UDP 等等,都需要进行回归压测。 通常,不会有问题;意外,总发生在不经意间。
压力测试指标
基础的关注点
QPS
每秒查询率,QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。 单位是 request/s
。
一般压测工具都会有这个指标,简单明了, 每秒处理的请求数量
。
6796 requests in 10.05s, 783.13KB read
Requests/sec: 676.21
Transfer/sec: 77.92KB
复制代码
比如,当前每秒处理 676.21
个请求。
RT
响应时间,这个指标比较多,比如,最小响应时间、平均响应时间、最大响应时间等等,详细指标还有 P50
、 P95
、 P99
等等
Latency Distribution
50% 23.03ms
75% 24.01ms
90% 25.38ms
99% 32.33ms
复制代码
比如, 50%
的请求在 23.03ms
内返回响应。
VU
虚拟用户,系统模拟并发的用户。主要目的是最大程度的模拟用户操作,从而得到较为准确的压测数据,这个参数一般由压测人员制定,梯度递增。
阶段1: 50虚拟用户,压测1小时;
阶段2: 100虚拟用户,压测1小时;
阶段3: 150虚拟用户,压测1小时;
阶段4: 200虚拟用户,压测1小时;
阶段5: 250虚拟用户,压测1小时;
复制代码
一般在为达到最佳负载的情况下, QPS
会随着 VU
的数量等比递增。 比如, 50VU
下的 QPS
是 1000
,那么 100VU
下的 QPS
会接近 2000
。
操作系统负载、外部系统等
压测期间,还需要关注下服务器的负载、网络 IO 情况,如果是 Java 工程,观察 JVM 也是很有必要的。如果涉及到外围系统,比如 Mysql、Redis 等,那么也要纳入观察范围。
学会观察
运行良好的特征
-
测试期间响应时间呈平稳趋势;
-
请求速率遵循与虚拟用户相同的斜坡(如果 VU 增加,则请求速率也会增加);
达到最大吞吐量的特征
-
随着虚拟用户数量的增加,活动的正在进行中的请求数量继续增加,而 QPS(完成的请求)却趋于平稳(甚至下降)。此时,系统过载,从而导致更长的响应时间。
-
HTTP 失败率增加
性能问题/瓶颈的特征
-
测试期间响应时间显著增加;
-
响应时间显著增加,然后迅速触底并保持平稳(HTTP 被降级了);
-
QPS 不会随着 VU 的增加而增加,并且响应时间开始增加,疑似达到最大吞吐量;
发生故障的特征
-
高 HTTP 错误率
-
低 QPS 下的系统高负载
图例
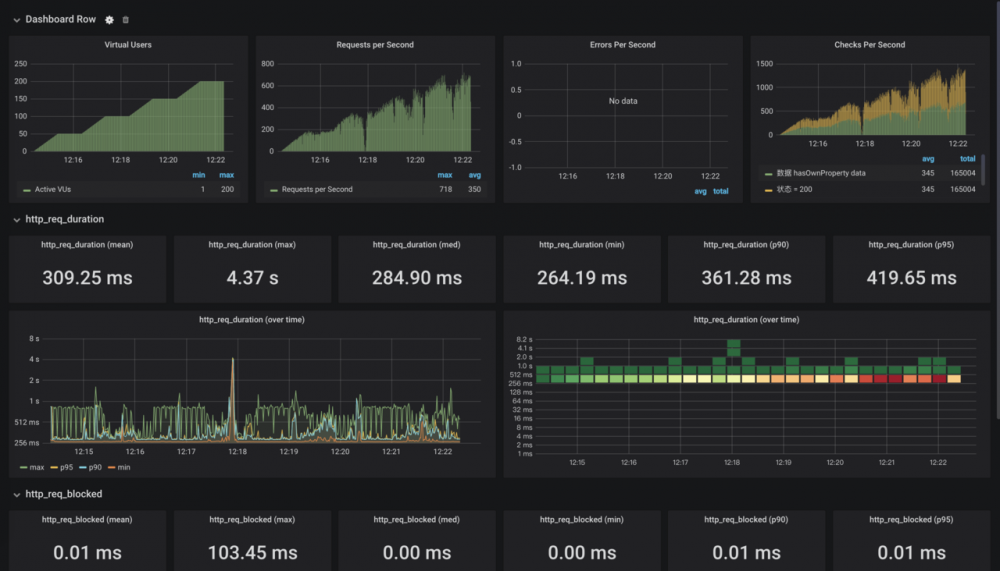
一般,可视化的图表更有利于分析。
请求速率遵循与虚拟用户相同的斜坡
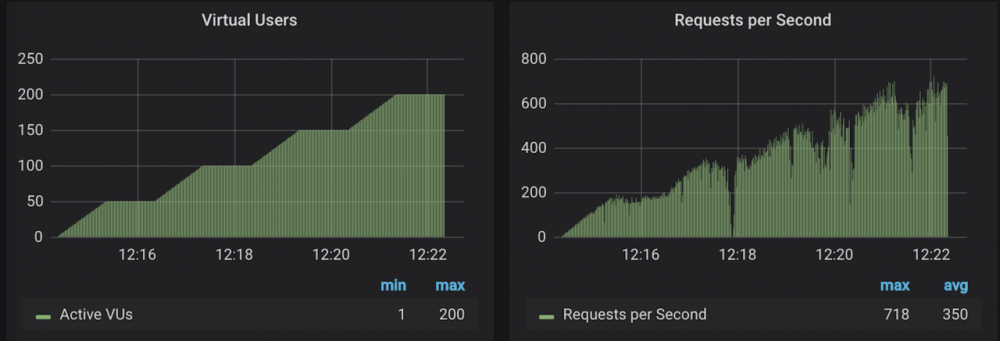
通过这个图,可以看出,在负压不大的情况下,这两个图表是有相同的 斜坡
的。 而 QPS
在 12:18
时突降,观察 JVM 可以知道,是出现了 FGC
。
测试期间响应时间呈平稳趋势

因为是外网压测,我们允许一定区间的网络波动,如上图的作图,观察 P90
、 P95
两条曲线,大致在我们预测的范围之内。右图的网格也显示出,大部分请求耗时集中在 256ms
到 521ms
之间,整体上散射保持一致。
压测工具
不同的压测工具的优缺点是不同的,设置压测出来的指标也会有较大差异。我们在执行压测时,更应该发现压测中出现的各种各样的问题。
比如,我用 jmeter
压测 30s 的 QPS
是 5000,而用 wrk
的 QPS
可能只有 1000,这种情况都是有具体原因的。 jmeter
在连接数还每达到最大值的时候,就已经开始计算 QPS 了,导致短时间压测的 QPS 偏大,随着压测时间增长, QPS
会降低。
本文使用 mdnice 排版
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

