详解双边队列 Deque
堆栈(Stack)数据结构也是常用的数据结构之一,但是官方建议使用 Deque 这种双边队列才替代之,所以,本文就对 Deque 这种数据结构进行详细地剖析下。
一、简介
这是数据结构系列的第二篇文章,上篇文章见: 【详解 HashMap 数据结构】
Deque 是 java.util 包下的一个接口,源码首行也讲明了,它是 double ended queue 的缩写,所以本文称之为 双边队列 ,顾名思义,它和队列 Queue 是有千丝万缕的联系的,看源码也可知,它继承自 java.util.Queue<E> 接口。
public interface Deque<E> extends Queue<E> {}
另外,Deque 发音同 deck ,不要读错了哦。
其实源码的注释很多都蛮有意思的,比如上面的发音,便是在源码中写到的
二、LIFO:Deque VS Stack
万物存在皆有因,那 Deque 存在的意义是啥呢?我个人的理解是剑指 Stack。
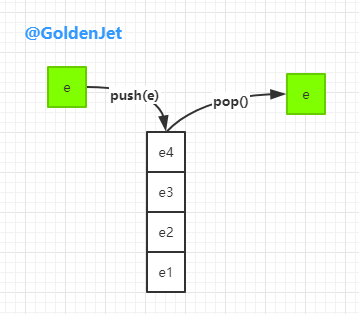
因为我们都知道,在处理 LIFO (Last-In-First-Out) 数列的时候,即后进先出,首先想到的数据模型便是 Stack(栈数据结构),因为它有两个最关键的方法: push(e) (压栈) 和 pop() (弹栈),Java util 包下也是有相关类的:
/**
* @since JDK1.0
*/
public class Stack<E> extends Vector<E> {}
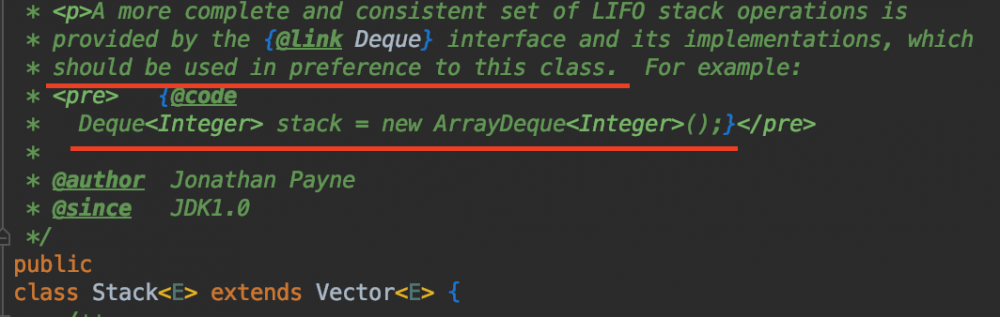
但是看源码内的注释,很明确地告诉我们,不建议使用 Stack 类,而使用 Deque<Integer> stack = new ArrayDeque<Integer>(); 来取代:
为什么呢?首先参考 SO 上面的回答: stack overflow
下面来简单说下:
1、首先,正如 SO 上面的回答,Stack 类继承自 Vector,确实蛮奇怪的,有点混乱,毕竟杂家也是个很实在的数据结构啊,怎么样也得和 Map 一样作为一个接口而存在吧,不然每个扩展类都要继承 Stack 类,蛮奇怪的。
2、其次,Stack 最大的弊端就是同步,即线程安全,因为它在方法上面都使用了重量级的锁命令 synchronized ,这样做造成的最大的问题就是性能会大打折扣,即效率低下,例如: public synchronized E pop() 。
上文已经提到了,Deque 是双边队列,双边的意思是即可以操作 头数据 也可以操作 尾数据 ,所以自然而然, Deque 是可以实现 Stack 中的 push(e) 和 pop() 方法的,两者的方法对应图如下:
| Deque | Stack | 说明 |
|---|---|---|
addFirst(e) |
push(e) |
向栈顶插入数据,失败则抛出异常 |
offerFirst(e) |
无 | 向栈顶插入数据,失败则返回 false |
removeFirst() |
pop() |
获取并删除栈顶数据,失败则抛出异常 |
pollFirst() |
无 | 获取并删除栈顶数据,失败则返回 null |
getFirst() |
peek() |
查询栈顶数据,失败则抛出异常 |
peekFirst() |
无 | 查询栈顶数据,失败则返回 null |
三、FIFO:Deque VS Queue
上文提到,Deque 继承自 Queue 接口,所以他们俩肯定是有相关性的,下面我们就来看看这两个接口是个啥情况。
首先,Queue 是队列,数据结构是 FIFO(First-In-First-Out),即先进先出,意思是元素的添加,是发生在末尾的,而元素的删除,则发生在首部。
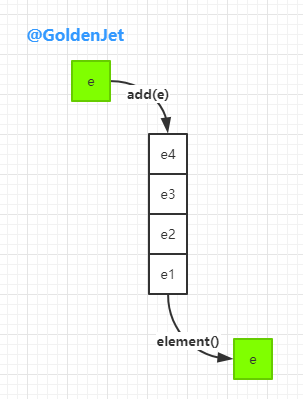
类似上图中的 add(e) 和 element() 方法,在 Deque 中都是有对应的方法的。
两个接口中方法的对应图如下:
| Deque | Queue | 说明 |
|---|---|---|
addLast(e) |
add(e) |
尾部插入数据,失败则抛出异常 |
offerLast(e) |
offer(e) |
尾部插入数据,失败则返回 false |
removeFirst() |
remove() |
获取并删除首部数据,失败则抛出异常 |
pollFirst() |
poll() |
获取并删除首部数据,失败则返回 null |
getFirst() |
element() |
查询首部数据,失败则抛出异常 |
peekFirst() |
peek() |
查询首部数据,失败则返回 null |
四、使用场景
无论是 Stack,还是 Queue,它们都只能操作头或尾,那如何同时支持操作头和尾呢,这便体现出 Deque(双边队列)的优势了,即 Deque 既可以用于 LIFO ,也可以用于 FIFO 。
Deque 和 List 最大的区别是,它不支持索引访问元素,但是 Deque 也提供了相应的方法来操作指定的元素:
removeFirstOccurrence(Object o) 和 removeLastOccurrence(Object o)
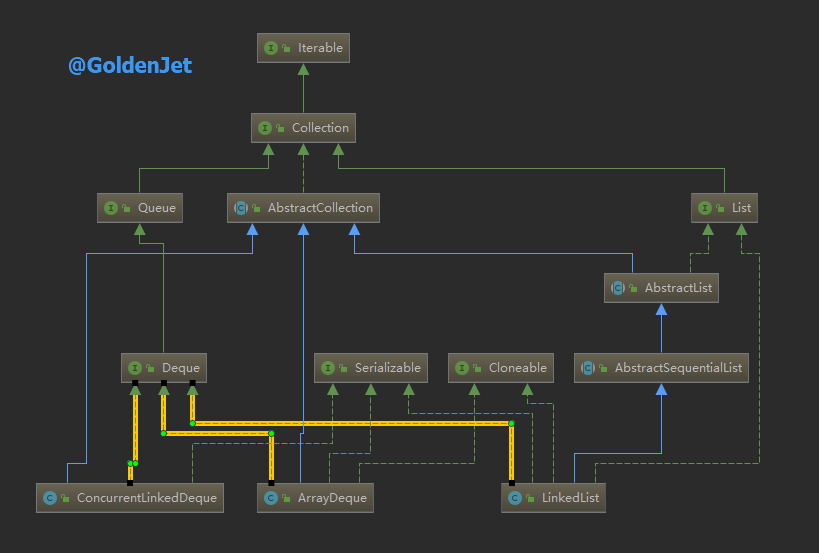
Deque 是一个数据结构的标准接口,只定义标准方法,其下有若干实现了该接口的类,比如常用的 ArrayDeque 、 LinkedList 、 ConcurrentLinkedDeque 。
由上面列举的三个类是我们常用的实现,看它们的名字我们便可以知晓, ArrayDeque 是基于数组的, LinkedList 和 ConcurrentLinkedDeque 很显然是基于链表的,并且后者是线程安全的。
这三个类的主要特性和应用场景见下表:
| 类 | 特点 & 使用场景 |
|---|---|
ArrayDeque |
①数组 ②大小可变,涉及自动扩容 ③无序 ④不可插入 null ⑤线程不安全 |
LinkedList |
①链表 ②大小可变,不需要扩容 ③无序 ④可以插入 null ⑤线程不安全 |
ConcurrentLinkedDeque |
①链表 ②大小可变,不需要扩容 ③无序 ④不可以插入 null ⑤线程安全 |
继承关系见下图:
五、ArrayDeque
下面我们从源码层面来介绍下它最重要的几个方法: 添加 和 删除 ,另外,ArrayDeque 底层是一个数组,所以自然而然会联想到数组固有的方法: 扩容 。
1、数据结构
数据结构很简单,没啥好说的,我们应该也能猜出来,就是一个数组,然后因为要操作头和尾,所以肯定有头部索引和尾部索引。
public class ArrayDeque<E> extends AbstractCollection<E> implements Deque<E>, Cloneable, Serializable {
// 底层的数据结构是一个数组
transient Object[] elements;
// 头部索引
transient int head;
// 尾部索引
transient int tail;
// 最小容量是 8
private static final int MIN_INITIAL_CAPACITY = 8;
}
2、构造函数
构造函数有三个,分别是:
- 无参构造(初始化一个容量为 16 的数组)
- 有参构造,参数是指定的容量
- 有参构造,参数是 Collection 集合
下面介绍下第二个有参构造,即初始化一个指定容量的数组,为什么要单独拎出来说呢,因为初始化的容量是有一定规则的。
// 初始化一个指定容量的 Deque
private void allocateElements(int numElements) {
// 初始化出来的数组容量,始终是 2 的幂次方
elements = new Object[calculateSize(numElements)];
}
还记得在上文 【详解 HashMap 数据结构】 中,谈过了它在扩容的时候的骚操作,此处 ArrayDeque 也是如初一折,即扩容的时候,容量始终是 2 的幂次方。
和 HashMap 不一样的是,HashMap 中有一个 -1 的动作,即计算而得的容量始终是大于等于参数的,例如参数是 8,则返回值也是 8。但是此处计算而得的容量始终是大于参数的,例如参数是 8,返回值则是 16。
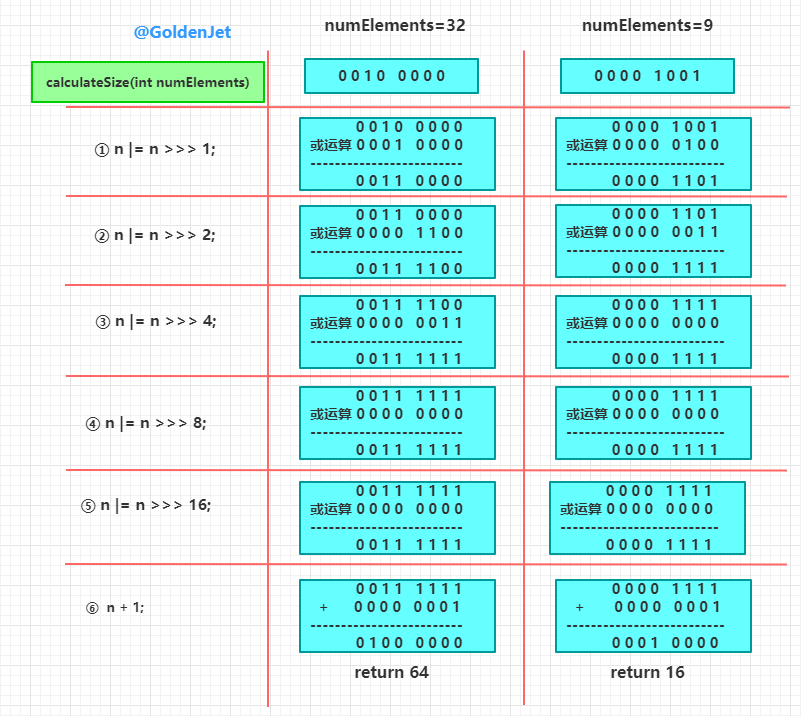
// 计算容量,容量始终是 2 的幂次方
// 容量最小是 8
// 返回值是 > 传入的参数的
private static int calculateSize(int numElements) {
// 容量最小值
int initialCapacity = MIN_INITIAL_CAPACITY;
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0)
initialCapacity >>>= 1;
}
return initialCapacity;
}
上面的位运算很精妙,就不再详细赘述了,详细可以看之前的文章 【详解 HashMap 数据结构】 ,然后精妙的计算逻辑,就贴一张前文中的图吧:
大致原理就是保证低位上面,每一位都是 1,最后 +1 ,这样就是实现了除了高位以外全是 0,也就是 2 的幂次方。
3、扩容
当容量不够的时候肯定就要进行扩容了,扩容的具体时机暂不进行叙述,等到下文讲 添加元素 方法的时候再详细描述下,下面就着源码讲解下扩容的方法:
// 扩容,扩容至 2 倍大小
private void doubleCapacity() {
// 断言,true 则继续,false 则抛 AssertionError 异常
assert head == tail;
int p = head;
// 当前容量
int n = elements.length;
// p 右侧的元素数量
int r = n - p;
// 新容量扩大两倍
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
// 新数组
Object[] a = new Object[newCapacity];
// 拷贝 head 右侧的数据,拷至目标数组0索引处
// 说下5个参数分别是:元数据、元数据中需要拷贝的元素的起始位置、目标数据、目标数据中需要粘贴的元素的起始位置、数据长度
System.arraycopy(elements, p, a, 0, r);
// 拷贝 head 左侧的数据,拷至目标数组 r 索引处
System.arraycopy(elements, 0, a, r, p);
elements = a;
// 首部索引
head = 0;
// 尾部索引
tail = n;
}
注意,上面的扩容操作,涉及到元数据拷贝至新数组的操作,此处是通过两次拷贝来进行的,为什么这么做呢,其实这就涉及到元素的添加了,下文接着讲。
4、添加元素
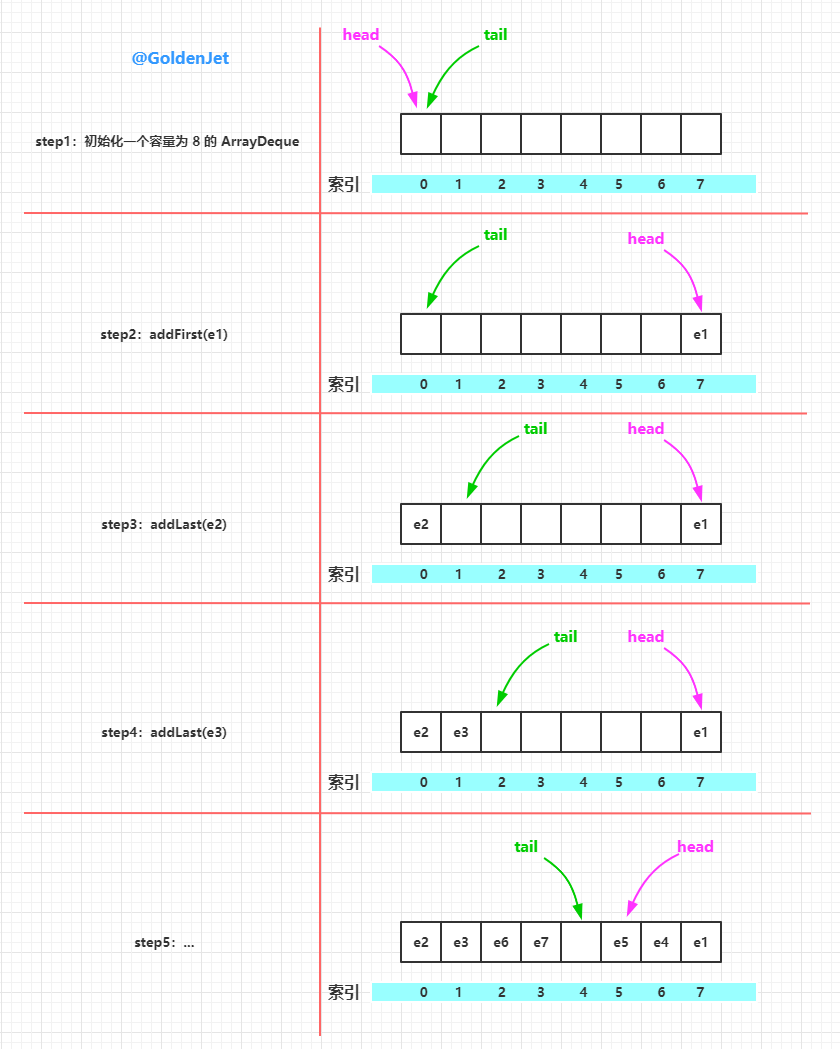
元素的添加,我们介绍两个典型的方法,其它的呢大同小异,分别是 首部添加 和 尾部添加 ,即 addFirst(E e) 和 addLast(E e) 。
// 首部添加元素
public void addFirst(E e) {
// 插入的元素不能为空,否则抛出空指针异常
if (e == null)
throw new NullPointerException();
// 首部索引减一,并将该索引处的元素设置为 e
elements[head = (head - 1) & (elements.length - 1)] = e;
// 判断是否需要扩容
if (head == tail)
doubleCapacity();
// 尾部添加元素
public void addLast(E e) {
// 插入的元素不能为空,否则抛出空指针异常
if (e == null)
throw new NullPointerException();
// 尾部索引处的元素设置为 e
elements[tail] = e;
// 尾部索引后移一位,并且判断是否需要扩容
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
从上面的源码中我们可以看到几个很有趣的点:
- 首部添加元素时,先将 head 索引前移,然后再添加元素,说明,head 索引处是有元素的
- 尾部添加元素时,直接在 tail 索引处添加元素,然后再将 tail 索引后移,说明,tail 索引处是没有元素的
- 从中可以看出数组中肯定有一个索引处是空的,即 tail 索引处,所以可以先插入元素然后再进行扩容的判断
- 扩容的判断条件是判断首尾索引是否一致,即 head == tail
首部添加元素的时候,如果 head 是 0,那么在进行 elements[head = (head - 1) & (elements.length - 1)] = e; 操作的时候,head – 1 = -1,elements.length – 1 = 15,将两者进行“与”运算的时候,因为“-1”的二进制其实是 “1111 1111… 1111”,即所有位上都是 1,所以与运算得出的结果自然也是 15。
下面画图来介绍下元素的插入过程:
5、移除元素
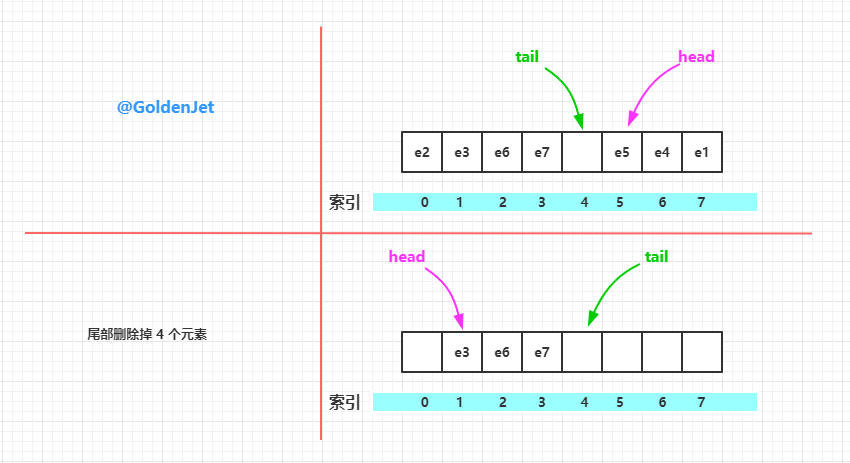
Deque 是不可以按照索引来删除元素的,只能删除首尾的元素( pollFirst() 、 pollLast() ),或者删除指定内容的元素( removeFirstOccurrence(Object o) 、 removeLastOccurrence(Object o) )
// 删除首部元素
public E pollFirst() {
// 首部索引
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
// 首部索引处元素置为 null
elements[h] = null; // Must null out slot
// 调整首部索引
head = (h + 1) & (elements.length - 1);
return result;
}
// 删除尾部元素
public E pollLast() {
// 尾部索引前的一个索引,因为尾部索引指向的索引处是没有元素的
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
// 置为 null
elements[t] = null;
tail = t;
return result;
}
删除元素的代码其实也很简单,有趣的是删除了元素之后的数组,可能出现数组的前部和后部有数据,也可能出现数组的中间部分有数据,也就是说 head 不一定总等于 0,tail 也不一定总是比 head 大。所以我们称之为 环形数组 。
六、LinkedList
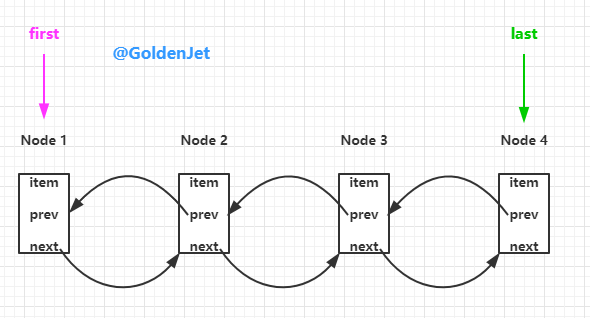
LinkedList 相对 ArrayDeque 而言,底层数数据结构由数组变为了链表,所以 LinkedList 自然而然是不用进行扩容操作的。
LinkedList 是由一个个的 Node<V> 组成的,每个 node 都会记录当前的数据、前一个 node 和 后一个 node,所以就形成了一个 链表 ,数据模型如下:
具体的方法就不赘述了,比较简单。
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// 链表长度
transient int size = 0;
// 第一个 元素
transient Node<E> first;
// 最后一个元素
transient Node<E> last;
// 每个节点的数据结构
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
七、ConcurrentLinkedDeque
上文提到的 ArrayDeque 和 LinkedList 都是 List 包下的工具类,而 ConcurrentLinkedDeque 就有意思了,它是 concurrent 并发包下面的类,其实看名字我们应该也能略知其中的一二了,它是线程安全的无边双向队列。
它内部的变量等都是使用 volatile 来修饰的,所以它是线程安全的。因为 volatile 的作用就是阻止变量访问前后的指令重排,从而保证指令的顺序执行。
另外,其内部使用了 自旋+CAS 的非阻塞算法来保证线程并发访问时的数据一致性,例如在首部添加元素 addFirst(E e) 方法:
public void addFirst(E e) {
linkFirst(e);
}
/**
* Links e as first element.
*/
private void linkFirst(E e) {
// 检查待插入的元素是否为空
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
// 锚点设计,作用是便于在多层 for 循环的内部 for 循环中,可以直接 continue 到该锚点
restartFromHead:
for (;;)
// 从head节点往前寻找first节点
for (Node<E> h = head, p = h, q;;) {
if ((q = p.prev) != null && (q = (p = q).prev) != null)
// Check for head updates every other hop.
// If p == q, we are sure to follow head instead.
// 如果head被修改,返回head重新查找
p = (h != (h = head)) ? h : q;
else if (p.next == p) // PREV_TERMINATOR
continue restartFromHead;
else {
// p is first node
newNode.lazySetNext(p); // CAS piggyback
if (p.casPrev(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this deque,
// and for newNode to become "live".
if (p != h) // hop two nodes at a time
casHead(h, newNode); // Failure is OK.
return;
}
// Lost CAS race to another thread; re-read prev
}
}
}
执行流程大致为:
(p.prev==null&&p.next!=p) lazySetNext
注意这里 CAS 指令成功后会判断 first 节点是否已经跳了两个节点,只有在跳了两个节点才会 CAS 更新 head,这也是为了节省 CAS 指令执行开销。
ConcurrentLinkedDeque 数据结构,本文就简单提了一点,详细的分析会放到后面介绍 java.util.concurrent 包(简称 JUC 包)的时候再详细阐述,尤其是 ConcurrentLinkedDeque 中的节点删除的操作,需要详细分析下。
八、小结
Deque 双边队列这种数据结构,为两端数据的操作提供了便捷性,并且也是官方建议的替换 Stack 数据结构的方案,另外,其不仅有最常用的 ArrayDeque ,也有线程安全的 ConcurrentLinkedDeque ,数据结构也是比较丰富的。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

