从软件开发到 AI 领域工程师:模型训练篇
前言
4 月热播的韩剧《王国》,不知道大家有没有看?我一集不落地看完了。王子元子出生时,正逢宫内僵尸作乱,元子也被咬了一口,但是由于大脑神经元尚未形成,寄生虫无法控制神经元,所以医女在做了简单处理后,判断不会影响大脑。这里提到了人脑神经元,它也是 AI 神经网络的研究起源,具体展开讲讲。
人脑中总共有 860 亿个神经元,其中大脑皮层有 160 亿个神经元。大脑皮层的神经元数量决定了动物的智力水平,人的大脑皮层中神经元数量远高于其他物种,所以人类比其他物种更聪明。大象的脑子总共有 2570 亿个神经元,但是其中 98% 的神经元都存在于大象的小脑中,而大象的大脑皮层只有 56 亿个神经元,无法与人类相比。大脑皮层中的神经元数量越大,能耗也越大。人脑每天消耗的能量占人体全部耗能的 25%,这也就是为什么我们每天都要吃多餐,很容易饿的原因。人之所以能够很快超越其他物种,主要是因为人类掌握了烹饪技术,能够在短时间内摄入大量卡路里以支持大脑运转,其他物种则将摄入的卡路里用于维护身体运转,不得不牺牲大脑皮层的神经元数量。
之所以先谈大脑神经元原理,也是为了引出本文的重点–现代 AI 技术。在正式进入 AI 技术前,我先讲讲软件工程师这份工作,因为现在有很多软件工程师准备转入 AI 行业。
软件工程师
我是软件工程师出身,2004 年刚毕业时我写的是 JSP 代码(一种将 Java 语言嵌入在 HTML 代码中的编写方式),工作几年后转入分布式软件技术,再后来进入大数据技术领域,最近的 4 年时间我一直在从事 AI 平台研发工作。
软件工程师的要求,我总体分为基础编码和系统架构两方面,因此我对于软件工程师的考察,特别是校招学生时,为了进一步考察他们的综合能力,我每次都会自己准备面试题,这些题目包括了编程基本概念、算法编程题、操作系统、数据库编程、开源代码阅读、垃圾回收机制、系统架构描述等。
编码的话题展开来可以讲很久,发展历史很悠久,我 15 岁学编程时用的是 Basic 语言,读大学时学的是 C 语言,大学毕业参加工作后第一门用的语言是 Java,其中的各种故事和理解可以写几篇文章,这里不展开谈。
我觉得谈到软件工程师工作,避不开软件架构设计。大众谈软件架构,很多人会认为软件架构就是一堆框架的组合,其实不对,软件架构本身是对于软件实体的组织形式的阐述,使用框架的意义是快速完成软件架构设计,而不是取代软件架构设计,两者本质上不是一类事物,更像是设计图纸和所使用的原材料。软件架构就是通过对软件生命周期的拆分,在符合业务架构的前提下,以达到软件本身访问增长目的的方式。这个增长需要软件开发的增长,也需要软件运行的增长,由此达到所支撑业务的增长。
市面上也确实有很多例如“分布式系统架构”、“微服务架构”等等跟随着潮流的书籍,但是看完后只停留在会采用一些开源框架进行整体框架搭建,我说的是搭建,而不是设计。确实是搭建,你所拥有的能力就好像小孩子搭积木,只会采用固定讨论,或者学得差点,连固定套路都没学会,这样对你的个人能力发展其实没有多大好处,这也是为什么很多程序员在完成了程序员 - 架构师的转型后,没过多久就转为纯管理,或者彻底离开了技术界,因为从来没有大彻大悟理解系统架构。
之所以谈了这么多系统架构相关的工作理解,是因为我认为系统架构师系统化的思维,我们搞 AI 系统也是系统化的思维,从有较强编程能力的系统架构师转 AI 技术,相对容易一些。
AI 工程师
为什么要从软件工程师转行到 AI 产品研发?因为 AI 产品研发有更大的吸引力,因为它更难,难到我们并不确定什么时候才能真正做出来,做出来真正能够可复制的 AI 产品。表面上看它也是一个门槛—一个“可用”且“可复制”的 AI 技术,但因为难度足够大,所以有挑战性,必须不断地改善技术,做全球范围内还没有做出来的技术。搞软件开发时处理的一些问题可能是其他公司已经解决的,并非“人类”都还没有解决的问题。
AI 的研究最早可以被追溯到亚里士多德的三段论,然后莱布尼茨创立了处理逻辑,布尔在布尔代数上的贡献,弗雷德在近代逻辑上的贡献,罗素在逻辑主义方面的贡献,这些工作都是在数据逻辑上的。一般认为,现代 AI 技术讨论,起源于 1956 年在达特茅斯学院召开的夏季研讨会,而这门学科的源头可能是 Alan Turing(阿兰. 图灵) 1948 年在英国国家物理实验室(NPL)写过的一份内部报告,这份报告中提到了肉体智能和无肉体智能,从某种意义上预示了后来符号派和统计派之争,或是 Turing 在 1950 年在哲学杂志《心》(Mind)上发表的文章“计算机与智能”,反正都是 Turing。
可以这么认为,现代 AI 是一系列通用目的技术的总称。现代 AI 技术,主要指基于机器学习(Machine Learning,简称 ML)/ 深度学习(Deep Learning,简称 DL)的一系列方法和应用,这只是 AI 领域的一个分支,也是目前发展最快、应用最广的分支。
机器学习 / 深度学习的原理可以这样理解:建立一个模型,给一个输入,通过模型的运算,得到一个输出。可以用于解决一个简单问题,例如识别图片是不是狗,也可以用来解决复杂问题,例如下棋、开车、医疗诊断、交通治理等等,也可以理解为,模型就是一个函数 f(x),上述过程,可以表达为:f(一张图片)= 狗 / 不是狗。
一个 AI 应用开发,大概分为三个阶段:
第一阶段,识别问题、构建模型、选择模型。AI 的开发和培养一个小孩子类似,不同的孩子有不同的爱好和特长,同样地,AI 也有很多模型 / 算法,不同的模型 / 算法适合解决不同的问题。所以,首先要识别你要解决的是个什么问题,然后选择一个合适的模型 / 算法;
第二阶段,训练模型。和培养小孩子一样,即使你发现小孩子有音乐天分,他也不可能天生就是钢琴家,他需要专业的训练。AI 开发也一样,选定模型 / 算法后,即使算法再好,也不能马上有效工作,你需要用大量的数据训练这个模型,训练过程中不断优化参数,让模型能够更为有效地工作。这个阶段 AI 模型的工作状态,叫做“训练”;
第三阶段,模型部署。模型训练结束后就可以部署了。比如一个人脸识别的模型,你可以把它部署在手机上,用于开机鉴权,也可以把它部署在园区闸机上,用于出入管理,还可以把它部署在银行的客户端上,用于业务鉴权,等等。如同一个孩子成长为钢琴家后,既可以在音乐会上演奏,也可以在家庭聚会上表演。AI 模型部署之后的工作状态,专业的说法,叫做“推理”。
通过上述 AI 开发过程的简述,可以发现,算法、数据和算力,是驱动 AI 发展的三大动力,三者缺一不可。
算法相当于是基因。基因不好,再努力也白搭。如何识别问题,并根据问题选择算法,甚至开发新的算法,是高端 AI 专家的核心竞争力;
数据相当于是学习材料。光基因好,没有好的教材,也教不出大师。AI 的训练,需要海量的、高质量的数据作为输入。AlhpaGo 通过自己和自己下棋,下了几千万盘,人类一辈子最多也就下几千盘。没有这样的训练量,AlhpaGo 根本不可战胜人类。自动驾驶,Google 已经搞了 10 年,训练了几十万小时,远远超过一个专业赛车手的训练量,但离真正的无人驾驶还差很远。另外,数据的质量也很重要,如果你给 AI 输入的数据是错的,那么训练出来的 AI,也会做出错误的结果。简单的说,如果你把猫的图片当做狗的图片去训练 AI,那么训练出来的 AI,就一定会把猫当做狗。数据的重要性直接导致了中国涌现了大批以数据标注为生存手段的公司和个人;
一个小孩,光有天分和好的学习材料,自己如果不努力,不投入时间和精力好好学习,绝对不可能成为大师。同样的道理,一个 AI 模型,算法再好、数据再多,如果没有足够的算力,支撑它持续不断的训练,这个模型永远也不能成为一个真正好用的模型。这就是为什么英伟达崛起的原因,这家公司的 GPU 芯片提供了最为适配于人脑神经网络的计算算力,现在国内工业界也有了类似的公司产品 - 华为的达芬奇芯片。
训练 AI 应用模型
动手实践前
接下来,我们通过对一个 AI 应用模型的训练和推理过程介绍,开始动手实践。
训练模型需要算力,对于算力的获取,训练和推理可以根据自己的业务需求,选择使用公有云或自己购买带算力芯片的服务器,本文案我选择的是某花厂的 AI 开发平台,因为近期他们刚推出一个免费算力的推广活动,可以省下一笔训练费用。为了便于调试,我首先在自己的 CPU 个人电脑上编写代码、训练模型,这样做的缺点是模型收敛的时间长了一些。
疫情期间,对于民众来说,佩戴口罩是最有效防止被传染新冠病毒的方式,保护自己的同时也保护他人。所以本文的案例是佩戴口罩的识别模型训练。
识别算法离不开目标检测。目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小。由于各类物体有不同的形状、大小和数量,加上物体间还会相互遮挡, 因此目标检测一直都是机器视觉领域中最具挑战性的难题之一。
基于深度学习的人脸检测算法,多数都是基于深度学习目标检测算法进行的改进,或者说是把通用的目标检测模型,为适应人脸检测任务而进行的特定配置。而众多的目标检测模型(Faster RCNN、SSD、YOLO)中,人脸检测算法最常用的是 SSD 算法(Single Shot MultiBox Detector,“Single Shot”指的是单目标检测,“MultiBox”中的“Box”就像是我们平时拍摄时用到的取景框,只关注框内的画面,屏蔽框外的内容。创建“Multi”个 "Box",将每个 "Box" 的单目标检测结果汇总起来就是多目标检测。换句话说,SSD 将图像切分为 N 片,并对每片进行独立的单目标检测,最后汇总每片的检测结果。),其他如 SSH 模型、S3FD 模型、RetinaFace 算法,都是受 SSD 算法的启发,或者基于 SSD 进行的任务定制化改进, 例如将定位层提到更靠前的位置,Anchor 大小调整、Anchor 标签分配规则的调整,在 SSD 基础上加入 FPN 等。本文训练口罩识别模型采用了 YOLO。
目标检测过程都可以分解为两个独立的操作:
- 定位(location): 用一个矩形(bounding box)来框定物体,bounding box 一般由 4 个整数组成,分别表示矩形左上角和右下角的 x 和 y 坐标,或矩形的左上角坐标以及矩形的长和高。
- 分类(classification): 识别 bounding box 中的(最大的)物体。
我选择采用 keras-yolo3-Mobilenet 方案,开源项目地址:
https://github.com/Adamdad/keras-YOLOv3-mobilenet。
MobileNet 的创新亮点是 Depthwise Separable Convolution(深度可分离卷积),与 VGG16 相比,在很小的精度损失情况下,将运算量减小了 30 倍。YOLOv3 的创新亮点是 DarkNet-53、Prediction Across Scales、多标签多分类的逻辑回归层。
基于开源数据集的实验结果:

动手训练模型
训练模型自然需要训练数据集和测试数据集,大家可以在这里下载:
https://modelarts-labs-bj4.obs.cn-north-4.myhuaweicloud.com/casezoo/maskdetect/datasets/maskdetectdatasets.zip
Yolo v3-MobileNet 目标检测工程的目录结构如下:
复制代码
|--model_data |--voc_classes.txt |--yolo_anchors.txt |--yolo3 |--model.py |--model_Mobilenet.py |--utiles.py |--convert.py |--kmeans.py |--train.py |--train_Mobilenet.py |--train_bottleneck.py |--voc_annotation.py |--yolo.py |--yolo_Mobilenet.py |--yolo_video.py
开源项目的好处是已经帮你封装了流程,例如涉及的 Yolo 代码不用修改,本次训练过程需要修改的代码主要是以下三个:
1.train_Mobilenet.py:模型训练代码;
2.yolo/model_Mobilenet.py:基于 mobilenet 的 yolo 的模型代码,如果相对模型代码仔细研究的人,可以研究这个代码;
3.yolo_Mobilenet.py:模型推理代码。
接下来具体介绍我们需要修改的代码,按照功能分为数据类、模型类、可视化类、迁移上云准备类。
•数据类:
仿照 modeldata/vocclasses.txt 写一个是否有戴口罩的类别的 txt,内容只有 yes_mask、no_mask 两个字符。
如果你下载我给出的数据集,你会发现,口罩数据集中给出的 xml 标注格式是 VOC 的标准的,仿照 convert.py 和 voc_annotation.py 写一个数据转换文件,代码如下所示:
复制代码
import xml.etree.ElementTreeasET
import os
def convert_annotation(classes, label_path):
in_file =open(label_path)
tree=ET.parse(in_file)
root = tree.getroot()
output_list = []
forobj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
ifcls not in classesorint(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b= (int(xmlbox.find('xmin').text),int(xmlbox.find('ymin').text),int(xmlbox.find('xmax').text),int(xmlbox.find('ymax').text))
output_list.append(" "+",".join([str(a)forainb]) +','+ str(cls_id))
return(' '.join(output_list))
def mask_convert(data_path, classes):
img_list = []
fori inlist(os.listdir(data_path)):
ifi.split('.')[1] =='jpg':
img_list.append(i.split('.')[0])
output_list = []
forimage_id in img_list:
img_path = (data_path +'/%s.jpg'% (image_id))
label_path = (data_path +'/%s.xml'% (image_id))
annotation = convert_annotation(classes, label_path)
output_list.append(img_path + annotation)
returnoutput_list
•模型类:
训练过程中会有一个 tensor 对不上的错误,需要修改 model_data/model.py 这个代码中的 140-141 行,如下所示:
复制代码
box_xy = (K.sigmoid(feats[..., :2]) + grid)/K.cast(grid_shape[..., ::-1],K.dtype(feats)) box_wh =K.exp(feats[...,2:4])*anchors_tensor/K.cast(input_shape[..., ::-1],K.dtype(feats))
•可视化类:
为了直观判断模型效果,增加了一个在图片上直接标注的可视化代码,也就是在图片上打印输出结果(yes_mask 或 no_mask),代码如下所示:
复制代码
#!/usr/bin/env python
# coding: utf-
img_path ="D:/Code/mask_detection/data/test"
save_path ="D:/Code/mask_detection/data/test_result/"
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplotasplt
import matplotlib.patchesaspatches
import matplotlib.imageasmpimg
importrandom
import json
# 推理输出路径
withopen('D:/Code/mask_detection/keras-YOLOv3-mobilenet-master/annotation_YOLOv3.json')asjson_file:
data = json.load(json_file)
imgs = list(data.keys())
def parse_json(json):
bbox = []
foriteminjson['annotations']:
name =item['label']
xmin =item['x']
ymin =item['y']
xmax =item['x']+item['width']
ymax =item['y']+item['height']
bbox_i = [name, xmin, ymin, xmax, ymax]
bbox.append(bbox_i)
returnbbox
def visualize_bbox(image, bbox, name):
fig, ax = plt.subplots()
plt.imshow(image)
colors = dict()#指定标注某个对象的边框的颜色
forbbox_iinbbox:
cls_name = bbox_i[0]#得到 object 的 name
ifcls_namenotincolors:
colors[cls_name] = (random.random(),random.random(),random.random())#随机生成标注 name 为 cls_name 的 object 的边框颜色
xmin = bbox_i[1]
ymin = bbox_i[2]
xmax = bbox_i[3]
ymax = bbox_i[4]
#指明对应位置和大小的边框
rect = patches.Rectangle(xy=(xmin, ymin), width=xmax-xmin, height=ymax-ymin, edgecolor=colors[cls_name],facecolor='None',linewidth=3.5)
plt.text(xmin, ymin-2,'{:s}'.format(cls_name), bbox=dict(facecolor=colors[cls_name], alpha=0.5))
ax.add_patch(rect)
plt.axis('off')
plt.savefig(save_path+'{}_gt.png'.format(name))#将该图片保存下来
plt.close()
foriteminimgs:
img = mpimg.imread(img_path+item)
bbox = parse_json(data[item])
visualize_bbox(img, bbox,item.split('.')[0])
•上云准备类:
开源代码写的比较随意,直接就是在训练代码 trian_Mobilenet.py 代码中一开头指定所有的参数。华为云中训练作业是需要指定 OBS 的输入路径和输出路径的,最好使用 argparse 的形式将路径参数传进去。其他参数可以按照自己需求做增加,修改样例如下:
复制代码
import argparse
parser = argparse.ArgumentParser(description="training a maskmodel in modelarts")
# 训练输出路径
parser.add_argument("--train_url",default='logs/maskMobilenet/003_Mobilenet_finetune/',type=str)
# 数据输入路径
parser.add_argument("--data_url",default="D:/code/mask_detection/data/MASK_MERGE/",type=str)
# GPU 数量
parser.add_argument("--num_gpus",default=0,type=int)
args = parser.parse_args()
开源代码中,数据处理的部分是将 xml 转换成 yolo 读的 txt 文档,这样导致数据输入需要有一个写入到 txt 文件,然后训练工程读取这个 txt 文件和图片的过程。上云后,这种流程不太方便,需要将数据处理,数据转换和训练代码打通。这里我使用缓存将数据直接传到训练代码中,这样改起来比较方便,但是当数据量较大的时候并不科学,有兴趣的人可以自己修改。
迁移公有云
我使用某厂商公有云的 AI 训练平台,用的是 OBS 桶上传已经调试好的代码(建议大家体验 Notebook 方式,在线编程、编译),如下图所示:
接着启动 Notebook,不过我没有用 jupyter 方式写代码,而是采用同步 OBS 桶的资源,通过 Notebook 启动一个 GPU 镜像:
创建一个 Notebook 环境:
确认计算资源规格:
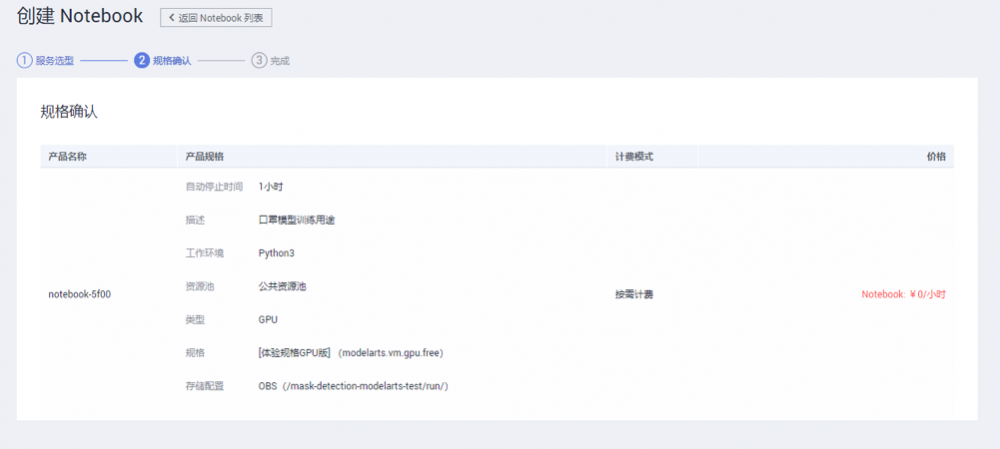
创建 Notebook 环境成功:

从 OBS 桶同步相关文件:
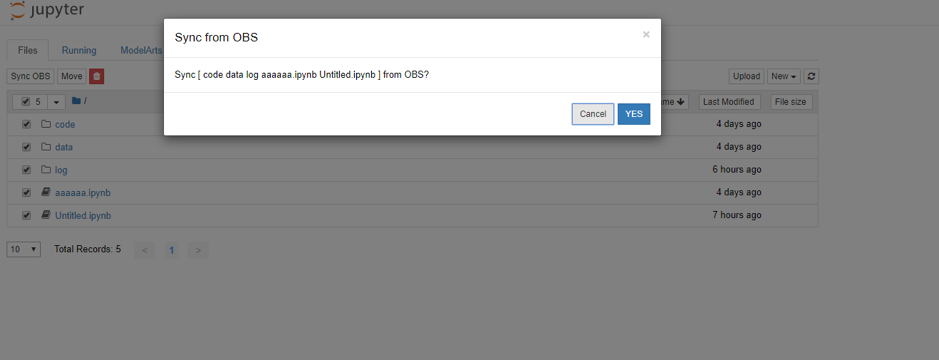
接下来进入该 Notebook 的终端环境,运行以下代码,启动训练任务:

训练过程输出片段如下所示:
复制代码
2020-04-0718:58:14.497319: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0locally 7/7[==============================] -17s2s/step - loss:4226.4421- val_loss:22123.3750 Epoch2/50 7/7[==============================] -6s855ms/step - loss:1083.1558- val_loss:1734.1427 Epoch3/50 7/7[==============================] -6s864ms/step - loss:521.8567- val_loss:455.0971 Epoch4/50 7/7[==============================] -6s851ms/step - loss:322.8907- val_loss:193.3107 Epoch5/50 7/7[==============================] -6s841ms/step - loss:227.7257- val_loss:150.8902 Epoch6/50 7/7[==============================] -6s851ms/step - loss:179.0605- val_loss:154.9351 Epoch7/50 7/7[==============================] -6s868ms/step - loss:150.4297- val_loss:147.3101 Epoch8/50 7/7[==============================] -8s1s/step - loss:129.5681- val_loss:144.8283
模型生成后,创建一个 python 脚本,代码如下,实现了模型文件拷贝到 OBS 桶:
复制代码
frommodelarts.sessionimportSession session=Session() session.upload_data(bucket_path="/mask-detection-modelarts-test/run/log/",path="/home/ma-user/work/log/trained_weights_final.h5")
运行推理脚本,我把推测结果打印在了测试图片上,如下图所示,识别出了口罩:

后记
AI 技术的兴起,已经带动了科技行业的革命,而每一次业界的革命,都会让一些公司落寞而让另一些公司崛起,程序员也一样,每一次技术换代也都会让一些程序员没落而让另一些程序员崛起。抓住目前正在流行的 AI 技术趋势,使用云端的免费计算资源,上手学习并实践 AI 技术,会是相当一部分软件工程师、数据科学家的选择。此外,由于在图像识别、文本识别、语音识别等技术领域,算法的精度已经给有大幅度的提升,在很多场景下已经达到可商用级别,也进一步让自动机器学习技术(模型的自动设计和训练)的发展成为可能。因此,在上述几个技术领域的很多应用场景下,公有云已经可以做到根据用户自定义数据进行 AI 模型的自动训练。
作者介绍:
周明耀,九三学社社员,2004 年毕业于浙江大学,工学硕士。现任华为云 AI 产品研发总监,著有《大话 Java 性能优化》、《深入理解 JVM&G1 GC》、《技术领导力 - 如何带领一支软件研发团队》、《程序员炼成记》等。职业生涯从软件工程师起步,后转为分布式技术工程师、大数据技术工程师,2016 年开始接触 AI 技术。微信号 michael_tect。
正文到此结束
- 本文标签: 病毒 编译 stream js 教材 调试 NFV App list 开源 http Deep Learning MQ 本质 服务器 微服务 https 数据库 UI Google 智能 key 语音识别 ask 神经网络 垃圾回收 root 缓存 git 银行 系统架构 管理 CTO XML final 推广 免费 IO 工程师 JVM ip description 配置 领导 软件工程师 json 开发 统计 下载 图片 模型 zip session 质量 find cat 大数据 时间 DOM 操作系统 src 文章 深度学习 分布式系统 ssh 架构师 db 科技 产品 开源项目 需求 parse 参数 lib python executor 分布式 java 架构设计 测试 部署 文案 IDE 代码 HTML 软件 同步 ACE ORM id 目录 性能优化 定制 rand 家庭 学生 数据 GitHub 程序员 组织 生命 数据科学 Master 云
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

