聊聊序列化
倘若世间有十万个未知的谜题,我便前去寻,那十万个谜底。
什么是序列化与反序列化
第一次接触到序列化是在我大一的时候,那个时候正好是期末考完要课设,其中数据结构的课设题目我们选了一个家谱管理系统,需要用 C++ 实现。在做课设的时候遇到一个问题是这样的——如何将家谱树的结构存储到文本中,然后再次打开程序读取文本的时候将其中的内容 load 到系统中呢?
后来我们查阅资料就发现了 序列化 和 反序列化 这两个东西,我朋友又在网上看了一些代码样例准备试试(当时课设是小组制的,每个人都有自己的分工)。
第二天,朋友拖着疲惫的身体,顶着沉重的黑眼圈过来跟我讲:“ made ,昨晚肝到两点,终于搞定了!” 于是他打开了管理系统的程序,给我演示了如何将树的结构进行 序列化 到文本中,然后再将文本中的内容 反序列化 映射到程序中。看着朋友的熊猫眼,我内心不禁竖起了大拇指(大一都这么能肝,工作了还得了)。所以,我深深地记住了这两个词。
对于多叉树和二叉树的序列化和反序列化在 leetcode 上有原题,这也算是一个面试的高频题吧,而且实现起来还是有些难度的,感兴趣的同学可以挑战一下。
二叉树的序列化与反序列化 难度:困难 。
序列化和反序列化二叉搜索树 难度:中等 。
序列化和反序列化 N 叉树 难度: 困难 。
那个时候我所理解的序列化和反序列化其实就是 将对象转换为字节序列和将字节序列转换为对象的过程 。
后来接触了 Java ,认识到了 Serializable 接口,慢慢又看了很多书,才意识到关于序列化和反序列化的学问远不止这些。
Java 中如何实现序列化和反序列化
我们让对象支持序列化和反序列化仅仅需要实现一个 Serializable 接口就行了。而对于 Serializable 接口,你查看源码会发现,这东西就一个接口声明,再没其他的了。
public interface Serializable {
}
复制代码
对于这个接口的解释在文件注释中也写的很清楚了, only to identify the semantics of being serializable 仅仅用来判断对象是否支持序列化和反序列化。
序列化原理浅析
那么如何进行对象的序列化和反序列化操作呢?
主要通过 ObjectOutputStream 和 ObjectInputStream 这两个类来实现。例如,我们可以将 Boy 的一个实例对象序列化到文件中,然后再反序列化构建另一个 Boy 对象。
@Data
public class Boy implements Serializable {
private int girlFriendCount;
}
// 测试方法
public static void main(String[] args) throws IOException, ClassNotFoundException {
Boy b1 = new Boy();
b1.setGirlFriendCount(10);
// 序列化
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("test")));
objectOutputStream.writeObject(b1);
// 反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("test"));
Boy b2 = (Boy)objectInputStream.readObject();
// 得到结果为10
System.out.println(b2.getGirlFriendCount());
}
复制代码
而在 writeObject(obj) 这个方法中(序列化),是如何判断能否进行序列化呢?其实答案很简单,我们可以 debug 查看核心源码。
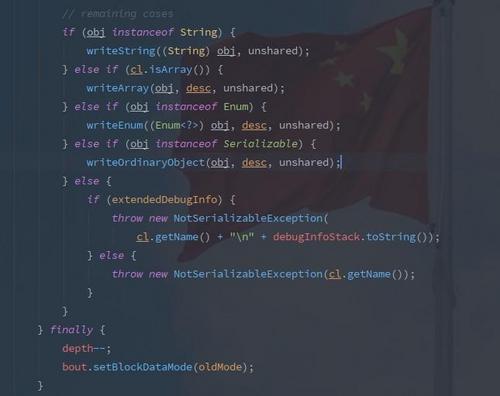
这段代码中就是判断了需要序列化对象的类型,如果走到 instanceof Serializable 还是不符合的话就会抛出 NoSerializableException 异常。所以如果你声明的类没有实现 Serializable 接口那么就会抛出这个异常。
以此类推,如果我对一个实现了 Serializable 接口的类的对象进行序列化, 但是它持有的一个对象并没有实现 Serializable 接口,此过程是否一定会抛出 NoSerializableException 异常呢 ?我看很多博客中都写到会抛出,其实我觉得不一定。如果说,该对象持有的那个未实现 Serializable 接口的对象并没有进行初始化(也就是说为 null ),那么此时是不会报错的,其原因也在源代码中。
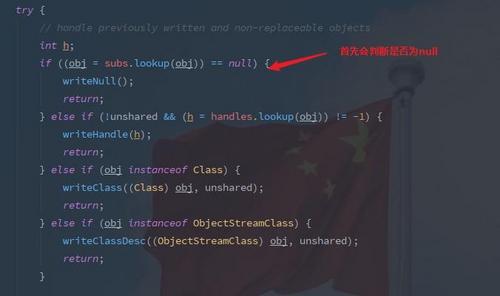
其实你可以尝试一下对 null 进行序列化,也是不会报错的。
而对于 Serialize 还有一个注意点就是,如果 父类实现了 Serialize 接口,子类继承了父类,子类是也默认实现了 Serialize 的 。这其实是一个设计的问题,没有那么多为什么,如果究其原因还是在那句 obj instanceof Serializable ,因为继承实现了 Serializable 接口的类的类,必然符合这个条件。
对于一个类的 静态成员 来说是不会被序列化的,而序列化本身就是对 对象 状态的记录,需要的是对象的属性而不是类的属性。但是有个有意思的地方, 内部静态类 可以实现序列化接口,甚至我们还可以使用静态类来创建 序列化代理 以此来提升序列化的安全能力。
public class Test implements Serializable {
private static final long serialVersionUID = 3005560411086043165L;
private int age;
private boolean sex;
private static class SerializableProxy implements Serializable {
private static final long serialVersionUID = 2677759736303136145L;
private final int age;
private final boolean sex;
SerializableProxy(Test test) {
this.age = test.age;
this.sex = test.sex;
}
}
private void readObject(ObjectInputStream stream) throws InvalidObjectException {
System.out.println("执行了 Test 的 readObject 方法");
throw new InvalidObjectException("需要代理!");
}
private Object writeReplace() {
System.out.println("执行了替代方法");
return new SerializableProxy(this);
}
}
复制代码
在上面代码中的 readObject 和 writeReplace 方法是序列化过程中会被调用的方法(可以理解为钩子函数),你可能会有疑问,不是调用的 objectInputStream.readObject(obj) 这个方法么,这两个钩子函数为什么会被执行?它们没有继承 ObjectInputStream 并且重写 readObject 方法呀,为什么会被调用?
其实原因也很简单,就在 ObjectInputStream 的执行流程中,这里我展示一下 ObjectOutpuStream 中的相关调用流程,原理都是一样的。
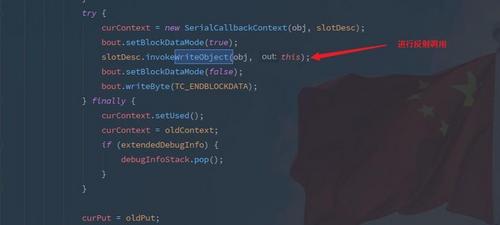
你可以进行 debug 然后查看里面具体的调用流程。而对于 Java 的序列化来说可以实现很多钩子函数, writeReplace() 亦是如此。
使用序列化代理来提高安全性
继续来说说,使用静态类来进行 序列化代理 的目的是什么?为什么要这么麻烦呢? Java 中为什么要定义这么多序列化钩子函数呢?
其实答案就是 安全 ,为了安全我们甚至可以牺牲一定的 性能开销 。如果一个类决定了实现 Serializable 接口那么也就意味着我们可以通过 语言机制 以外的方式去创建实例(因为我们可以调用 readObject ,通过字节流创建了呀)。可以这么理解,反序列化其实就是一个 隐藏的构造器 ,反序列化过程中我们可以去违反类原本的构造器 约束 ,甚至去干一些构造以外的事情。
这必定会带来不可估量的安全问题,比如说,业界中常常提到的 反序列化炸弹 来实现 DoS 拒绝服务攻击 ,我们可以通过互相引用的200个 HashSet 互相引用实例来构建 2^100 次的 hashCode 方法调用;而攻击者还能根据 反序列化期间被调用的方法 ,形成根据序列化形成的调用代码来 任意 的在程序中进行执行,这个后果也就意味着攻击者能直接控制你所谓的程序。
序列化破坏单例
所以,是否该实现序列化是一个慎重的决定,例如如果让 单例 的类去实现 Serializable 接口,那么就会破话单例模式。
当然你可以再次使用一个钩子函数 readResolve ,当对象已经通过 readObject 方法产生了,如果说你书写了这个 readResolve 方法,那么就会调用这个方法并且返回你想要的真正的对象。
private Object readResolve() {
// 直接返回单例
return INSTANCE;
}
复制代码
但是这种方式也 并不是绝对安全 ,如果一个单例包含一个非瞬时(未被 transient 修饰)对象,那么这个域的内容就可以在单例的 readResolve 方法运行之前被反序列化,具体编码方式可以参考 《Effective Java》,这里不做过多描述。
谈谈 serialVersionUID
在上文中的 Test 类以及它的序列化代理类我都添加了 serialVersionUID 这个私有静态不可变属性,为什么要添加呢?
所谓 serialVersionUID ,顾名思义,其实就是 序列化版本ID ,序列化为什么要和版本牵扯关系呢?
首先需要明确的是即使我们不加上 serialVersionUID 这个字段, Java 也会根据这个类的 类名称、所实现接口的名称、以及所有 public protected 字段 通过加密散列函数来生成一个默认的 serialVersionUID 。这个序列号在反序列化过程中会用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的 版本号不同 ,则反序列化将会导致 InvalidClassException 。
所以给类加上一个 serialVersionUID 字段,以确保兼容问题是一个明智的选择。
其他序列化方式以及安全防范
现如今有很多前沿的序列化机制,例如 JSON 、 ProtoBuf 等,他们能更好地支撑不同平台之间的序列化问题,而对于 Java 原生的序列化因为其性能,安全,应用的问题也有可能会在未来被淘汰。
也并不是说其他序列化方式没有漏洞,就比如我们常使用的 fastJSON 就被曝出过好几次漏洞,因为反序列化本身就是一个范围比较广的安全问题,如果黑客利用反序列化漏洞构造执行链就相当于控制了你的整个程序,他就可以为所欲为了。
而对于如何进行安全防范也是一个比较头疼的问题。比如说如何去阻止黑客去构造调用链,其实对于黑客来说构建调用链都是基于类的方法,我们可以去添加一个黑名单,让一些本不必要执行序列化的类纳入到 黑名单 中。
像我们前面提到的很多 钩子函数 ,这也是一种序列化安全的解决方案 RASP 。我们可以在钩子函数中加入一层规则判断,判断是否有非正常代码的执行,甚至我们可以直接限制程序的序列化反序列化过程。
《Effective Java》第三版 。
Java工程师成神之路 | 2020正式版 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

