JVM笔记-后端编译与优化
1. 概述
前面分析了 JVM 的前端编译器 Javac,本文分析后端编译器:即时编译器(JIT 编译器)和提前编译器(AOT 编译器)。
其实二者都不是 JVM 必需的组成部分。但是,后端编译器编译性能的好坏、代码优化质量的高低,却是衡量一款商用 JVM 优秀与否的关键指标之一,也是其核心所在。
2. 即时编译器
目前主流的两款商用 JVM(HotSpot、OpenJ9)中,Java 程序最初都是通过「解释器(Interpreter)」解释执行的,当 JVM 发现某个方法或代码块的执行特别频繁,就会认为它们是“热点代码(Hot Spot Code)”。
为了提高热点代码的执行效率,JVM 会在「运行时」把这部分代码编译成本地机器码,并用各种手段去优化代码。运行时完成这个任务的后端编译器被称为「即时编译器」。
这种机制可以类比我们平时调用接口查询数据:
-
某个接口如果查询比较简单、且访问量较少,就没必要使用缓存,直接查询数据库就行;
-
当该接口访问量很大时,为了提高查询效率,可以使用缓存提高效率。
HotSpot VM 内置了三个即时编译器,分别为:
-
客户端编译器(Client Compiler),简称 C1 编译器。
-
服务端编译器(Server Compiler),简称 C2 编译器,或 Opto 编译器。
-
Graal 编译器(JDK 10 出现,长期目标是替代 C2 编译器)。
2.1 解释器与编译器
2.1.1 执行流程
解释器的执行流程大致如下:
输入的代码 -> [ 解释器 解释执行 ] -> 执行结果
即时编译器的执行流程大致如下:
输入的代码 -> [ 编译器 编译 ] -> 编译后的代码 -> [ 执行 ] -> 执行结果
此处引用了 RednaxelaFX 大佬在知乎的回答,链接:https://www.zhihu.com/question/37389356/answer/73820511 。若想了解更深层次的内容,要去看编译原理相关的书了。
2.1.2 对比分析
目前主流的商用 JVM 内部都同时包含解释器与编译器,二者各有优势:
-
程序需要迅速启动和执行时,解释器可以省去编译时间,立即执行。
-
程序启动后,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,可以减少解释器的中间消耗,提高执行效率。
-
若运行环境的内存资源限制较大,可使用解释器执行节约内存;反之可使用编译执行来提升效率。
总结起来就是:
-
解释器启动较快,占用内存较小,但是执行效率稍低。
-
编译器启动较慢,占用内存较大,但执行效率较高。
此外,解释器还可以作为编译器激进优化时后备的“逃生门”,也就是给编译器来“兜底”,反之则不行。
凡事有利弊。这里仍以查询接口为例做类比:
-
解释执行可以理解为直接查询数据库,也就是不使用缓存。程序启动起来比较快(无需连接缓存服务器),但后面运行的时候由于每次都要去查数据库,会有磁盘 IO 开销,会相对慢一些。
-
而编译执行就相当于使用了缓存。虽然启动会稍慢一些(需要连接缓存服务器,初次查询时既要查询数据库,又要存入缓存),而且需要额外的开销(需要缓存服务器),但是后续的查询效率会提高很多,因为可以直接从缓存获取,不必再查询数据库。
因此,使用缓存其实就是“空间换时间”,编译器与解释器也可以类比来理解。
2.1.3 运行模式
解释器与编译器配合使用的方式在虚拟机中被称为“混合模式(Mixed Mode)”,比如我们查看 JDK 版本时:
$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
最后面的 mixed mode 就表示混合模式。
此外,也可以使用参数 -Xint 强制虚拟机运行于“解释模式(Interpreter Mode)”:
$ java -Xint -version
java version ...
...
... (build 25.191-b12, interpreted mode)
还可以使用参数 -Xcomp 强制虚拟机运行于“编译模式(Compiled Mode)”:
$ java -Xcomp -version
java version ...
...
... (build 25.191-b12, compiled mode)
2.2 分层编译
JIT 编译器的编译过程是在「运行期」,这就不可避免会占用应用程序的资源。而且,想要把代码优化得更好,就要花费更多的时间。而且可能还需要解释器帮忙收集一些性能监控信息,又降低了解释器的效率。这可怎么办?
那找个折衷的方案?其实就是分层编译(Tiered Compilation)。
分了哪几个层次呢?主要包括:
-
程序纯解释执行,且解释器不开启性能监控功能。
-
使用 C1 编译器将字节码编译为本地代码来执行,进行简单可靠的稳定优化,不开启性能监控功能。
-
使用 C1 编译器执行,仅开启一部分性能监控功能(方法及回边次数统计等)。
-
使用 C1 编译器执行,开启全部性能监控(在第二层之外,还会收集如分支跳转、虚方法调用版本等全部的统计信息)。
-
使用 C2 编译器将字节码编译为本地代码(相比 C1 编译器,C2 编译器会启用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化)。
这几个层次并非固定不变,可以根据不同的运行参数灵活使用。
2.3 热点代码
运行时会被即时编译器编译的目标是“热点代码”,主要包括下面两类:
-
被多次调用的方法。
-
被多次执行的循环体。
前者比较容易理解:一个方法被调用的次数多了,自然就成了热点代码。
后者是什么场景呢?当一个方法被调用的次数虽然不多,但方法体内部存在循环次数较多的循环体。这种代码也是“热点代码”(可以理解为方法的一部分是热点代码)。比如:
public void test() {
// 一些其他代码...
// 即便 test() 方法被调用的次数不多,但当 N 足够大时,该部分代码也会成为“热点代码”
for (int i=0; i<N; i++) {
// 执行一些操作...
}
// 一些其他代码...
}
前者是 JVM 标准的即时编译。
至于后者,虽然热点代码只是方法的一部分,但编译器仍会把「整个方法」作为编译对象,只是入口不同(并非从方法的第一行代码开始)。由于该情况发生在方法执行的过程中,也被称为栈上替换(On Stack Replacement,OSR)。也就是方法的栈帧还在栈上,但方法已经被替换了(“狸猫换太子”)。
PS: 每个方法被执行时,虚拟机栈都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈等信息。每个方法从被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
2.4 热点探测
关于热点代码的判定,前面一直提的都是“多次”,到底多少次才叫“多”呢?这个问题不仅要“定性”,还要“定量”。
要判定一段代码是不是热点代码、是否触发即时编译的行为称为“热点探测(Hot Spot Code Detection)”。
2.4.1 定量方法
热点探测的主流方法有以下两种:
-
基于采样的热点探测(Sample Based Hot Spot Code Detection)
就是每隔一段时间去检查一下所有线程的调用栈顶,若发现某个(或某些)方法经常出现在栈顶,该方法就会被认为是“热点代码”。J9 虚拟机使用过该方法。
这种做法的优缺点如下:
-
优点:实现简单高效,而且可以通过堆栈信息获取到方法之间的调用关系;
-
缺点:难以精确的确定方法热度,容易受到线程阻塞的干扰(即方法阻塞时可能长时间处于栈顶,可能产生误判)。
-
基于计数器的热点探测(Counter Based Hot Spot Code Detection)
为每个方法(或代码块)建立计数器来统计方法的执行次数,当次数超过一定的阈值就认为是“热点代码”。HotSpot 虚拟机就是使用该方法进行探测的。
该方法的同样也有优缺点:
-
优点:统计结果更加精确严谨;
-
缺点:统计起来稍麻烦(要为每个方法建立并维护计数器),而且不能直接获取到方法的调用关系。
2.4.2 两种计数器
HotSpot 为每个方法准备了两类计数器,下面分别介绍。
2.4.2.1 方法调用计数器
方法调用计数器(Invocation Counter)用来统计方法被调用的次数。它在客户端和服务端模式下的默认阈值分别为 1500 次和 10000 次。
该计数器触发即时编译的流程图如下:
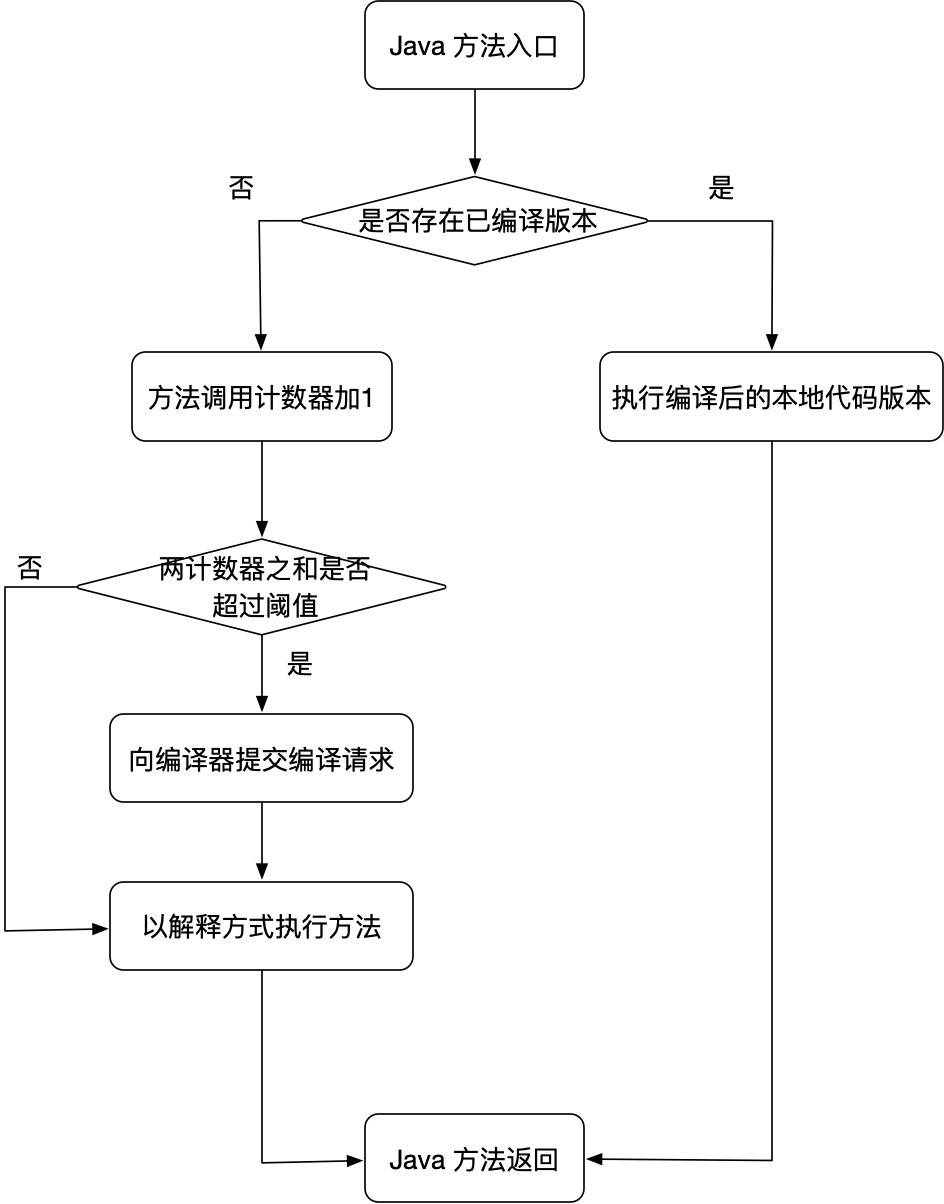
PS: 方法调用计数器统计的并非方法被调用的绝对次数,而是是一个相对的执行频率。
什么意思呢?
也就是在一段时间内,如果方法的调用次数未到达阈值,计数器就会减少为原先的一半。该过程被称为热度衰减(Counter Decay),这段时间则被称为半衰周期(Counter Half Life Time)。
比如,若阈值是 10000,半衰周期是 1 小时。如果在 1 小时内,某个方法被调用了 8000 次(未达到即时编译的条件),计数器就会认为该方法没那么“热”,就要给它“泼冷水”,把次数降为 4000 (纯属个人理解)。
当然,有 JVM 参数可以对此进行调整,如下:
# 指定计数器的阈值
-XX:CompileThreshold
# 关闭热度衰减
-XX:-UseCounterDecay
# 设置半衰期时间(秒)
-XX:CounterHalfLifeTime
2.4.2.2 回边计数器
回边计数器(Back Edge Counter)用来统计方法中循环体代码执行的次数(字节码中遇到控制流向后跳转的指令称为“回边”),目的是为了触发栈上替换。
回边计数器触发即时编译的流程如下:
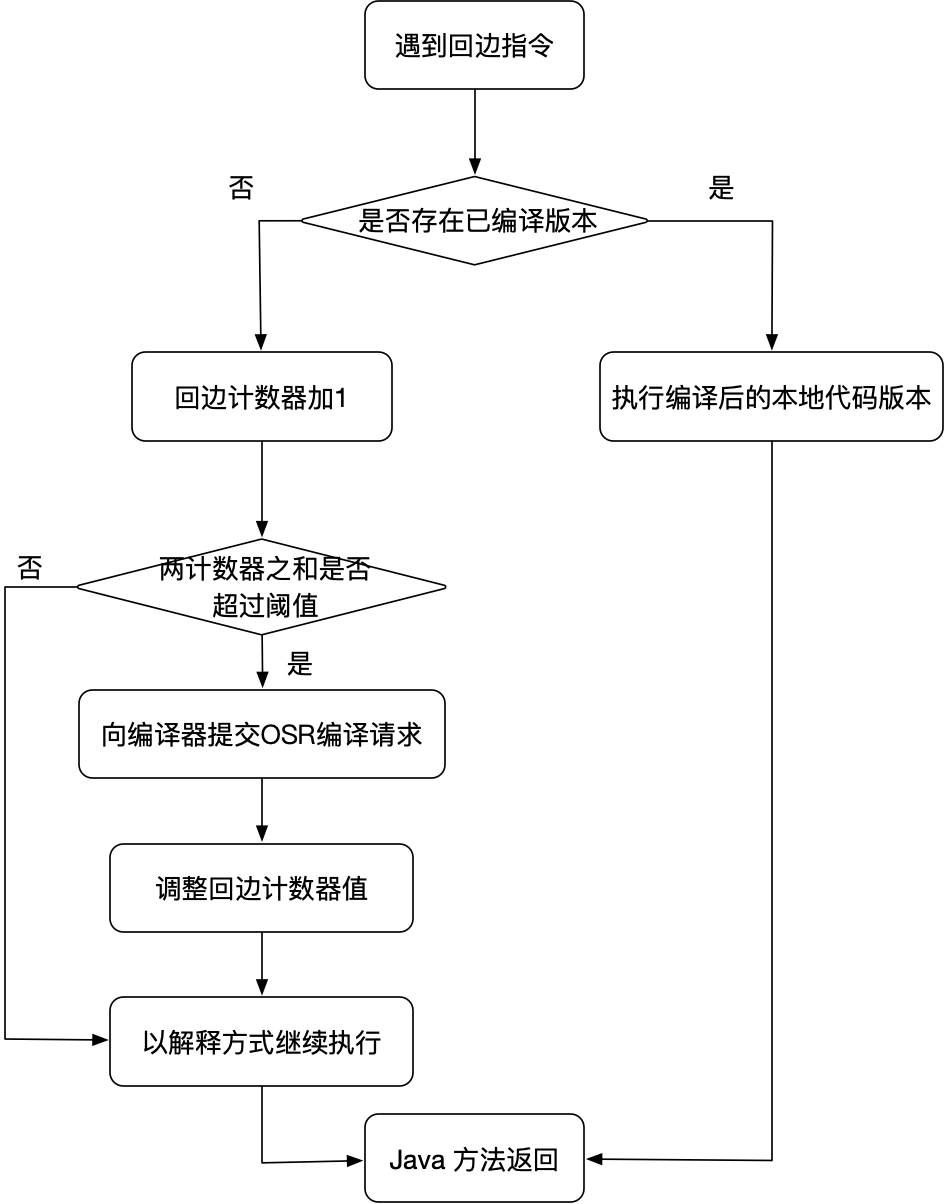
与此相关的几个 JVM 参数:
# OSR 比率,默认 933
-XX:OnStackReplacePercentage
# 解释器监控比率,默认 33
-XX:InterpreterProfilePercentage
3. 提前编译器
对提前编译的研究主要有下面两条分支。
3.1 静态翻译
第一条就是在程序运行之前,把程序代码“翻译”成机器码。
JIT 编译器的主要缺点在于:它是在「运行期」进行编译的。这就不可避免地要占用应用程序的运行资源(CPU、内存等),进而影响程序的执行性能。
而这种提前编译就是把这个编译阶段放到程序的「运行期」之前,这样就可以不占用应用程序的资源。
3.2 即时编译缓存
其实就是把 JIT 编译器要做的编译工作先做好,并保存下来,当触发 JIT 编译时,直接调用这里的代码就好了。本质上就是给 JIT 编译做缓存。
这种方式也被称为动态提前编译(Dynamic AOT)或者即时编译缓存(JIT Caching)。
3.3 即时编译&提前编译
从上面对提前编译器的分析来看,似乎提前编译比 JIT 编译运行效率更高。那它就没缺点了吗?当然不是,否则还要 JIT 编译器干嘛。
相比提前编译器,JIT 编译器的优势在哪里呢?
-
性能分析制导优化
解释器或客户端编译器在运行的过程中,会不断收集性能监控信息(方法版本选择、条件判断等),这些信息可以帮助 JIT 编译器对代码进行集中优化。
这一点在静态分析时是很难做到的。
-
激进预测性优化
也就是 JIT 编译器可以进行一些稍微“激进”的优化行为,即便这些行为失败了,也有解释器可以“兜底”。而静态优化就做不到了。
此外,提前编译还会破坏 Java 平台中立性、产生字节膨胀等问题。
4. 编译器优化技术
前面分析了 JIT 编译器和提前编译器,它们做的都是“翻译”工作。但关键问题不在于“能不能”翻译,而是翻译的“好不好”。也就是编译出来的代码质量高不高。
那么,它们用什么手段来提升“翻译”的质量呢?
HotSpot VM 的 JIT 编译器使用了不少优化技术(可参考:https://wiki.openjdk.java.net/display/HotSpot/PerformanceTacticIndex),下面介绍几个非常重要的。
PS: JIT 编译器对代码的优化,这里的“代码”并非我们编写的源代码,而是被编译后的字节码或者机器码。毕竟已经通过类加载器把 Class 文件加载到 JVM 了。
4.1 方法内联
方法内联是编译器最重要的优化手段,业内戏称为“优化之母”。是其他优化手段的基础。
它的行为理解起来其实很简单:就是在方法调用中,把目标方法的代码“复制”到调用的方法之中,避免发生真实的方法调用。示例代码如下:
public static void foo() {
if (obj != null) {
System.out.println("hello");
}
}
public static void testInline() {
Object obj = null;
foo(obj);
}
该段代码实际是无用代码(Dead Code),经过方法内联(把 foo 方法的代码代入到 testInline 方法中)之后可以发现。
但若不做内联,后续即便进行了无用代码消除的优化,也无法发现该无用代码。
4.2 逃逸分析
逃逸分析(Escape Analysis)是目前 JVM 中比较前沿的优化技术。但它并不直接优化代码,而是一种为其他优化措施提供依据的分析技术。
它的基本原理是分析对象的动态作用域,当一个对象在方法中被定义后,按照逃逸程度从低到高可分为:
-
不逃逸:对象只能在本方法内使用。
-
方法逃逸:对象可能被外部方法引用(例如作为调用参数传递到其他方法)。
-
线程逃逸:对象可能被外部线程访问到(例如赋值给线程共享的变量)。
若一个对象未发生逃逸,或者逃逸程度较低,可以为这个对象采取不同程度的优化。
4.2.1 栈上分配
JVM 中,对象的内存空间分配在堆上似乎是一个常识。当对象不再使用时,垃圾收集器会将其内存空间回收,这个过程其实是要消耗大量资源的。
假如……把对象的内存空间分配到栈上呢?
What ???这简直是颠覆认知!
但是,不妨沿着这个思路考虑一下:如果这样做了有什么好处呢?
这样一来对象占用的内存空间就会随着栈帧出栈而销毁,不必再由垃圾收集器费时费力地去回收了,可以节省不少资源。这样一想似乎也是不是不可以。
这就是所谓的栈上分配(Stack Allocations),它可以支持「方法逃逸」,但不支持线程逃逸。
PS:由于复杂度等原因,HotSpot 目前暂未做这项优化,但有些 JVM(例如 Excelsior JET)已经在使用了。
4.2.2 标量替换
先看一下标量(Scalar)和聚合量(Aggregate)的概念:
-
标量:无法再分解为更小数据的数据,例如 JVM 中的原始数据类型(int、long、reference 等)。
-
聚合量:可以继续分解的数据,例如 Java 中的对象。
所谓「标量替换(Scalar Replacement)」,就是根据实际访问情况,将一个对象“拆解”开,把用到的成员变量恢复为原始类型来访问。
简单来说,就是把聚合量替换为标量。
若一个对象不会逃逸出「方法」,且可以被拆散,那么程序真正执行时就可能不去创建这个对象,而是直接创建它的若干个被该方法使用的成员变量代替。
还有这操作?
其实细想一下,这个操作跟前面的「栈上分配」还是有些类似的:栈上分配的是对象,而标量替换则是在栈上分配对象的一部分成员变量,连对象都懒得创建了。
4.2.3 同步消除
线程同步本身相对耗时,如果逃逸分析能够确定一个变量不会逃逸出线程,则该变量的读写就不会有线程安全问题,对该变量的同步措施就可以安全的消除了。
换句话说,如果对线程安全的数据加了锁,JVM 就可以把它优化消除。示例代码如下:
public void t1() {
// 变量 o 不会逃逸出线程。因此,对它加的锁就可以被消除
Object o = new Object();
synchronized (o) {
System.out.println(o.toString());
}
}
4.3 代码示例
上面介绍了方法内联和逃逸分析的相关优化手段,这里以伪代码的形式演示它们优化的过程。
-
原始代码
// 原始代码
public class Point {
private int x;
private int y;
// getter/setter ...
}
public int test(int x) {
int xx = x + 2;
Point p = new Point(xx, 42);
return p.getX();
}
-
方法内联
首先,将 Point 的构造函数和 getX() 方法进行内联:
// 方法内联优化后
public int test(int x) {
int xx = x + 2;
Point p = point_memory_alloc(); // 堆中分配内存示意方法
p.x = xx; // Point 构造函数内联后
p.y = 42;
return p.x; // p.getX() 方法内联后
}
-
逃逸分析
经过逃逸分析,发现 Point 对象不会逃逸出 test() 方法,可以进行「标量替换」,如下:
// 标量替换优化后
public int test(int x) {
int xx = x + 2;
int px = xx; // 标量替换
int py = 42;
return px;
}
-
无效代码消除
经过数据流分析,发现变量 py 对方法不会造成任何影响,可以进行消除,如下:
// 无效代码消除优化后
public int test(int x) {
return x + 2;
}
可以看到,原始代码经过一系列的优化,最终结果简洁了很多。
更少的代码也意味着占用的内存空间更少,执行起来效率也更高,这也是优化的意义所在。
4.3 公共子表达式消除
4.3.1 公共子表达式
所谓公共子表达式,就是当有一个表达式 E 在以前被计算过,而且下次再遇到的时候 E 的所有变量都未改变,则这次 E 的出现就被称为「公共子表达式」。也就是不必再花功夫重新计算,直接拿来用就好了。有木有“缓存”的感觉?
根据作用域,公共子表达式的消除可分为两种:局部公共子表达式消除和全局公共子表达式消除。
4.3.2 示例代码
若有如下代码:
public class Test {
public int t1() {
int a=1, b=2, c=3;
int d = (c * b) * 12 + a + (a + b * c);
return d;
}
}
Javac 编译后生成的字节码如下:
public int t1();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=4, locals=5, args_size=1
# ...
6: iload_3
7: iload_2
8: imul # 计算 b*c
9: bipush 12
11: imul # 计算 (c * b) * 12
12: iload_1
13: iadd # 计算 (c * b) * 12 + a
14: iload_1
15: iload_2
16: iload_3
17: imul # 计算 b*c
18: iadd # 计算 (a + b * c)
19: iadd # 计算 (c * b) * 12 + a + (a + b * c)
20: istore 4
22: iload 4
24: ireturn
# ...
Javac 编译器并未做任何优化,每次都会重新计算。
这段代码进入即时编译器后,将进行如下优化:
编译器检测到 c * b 与 b * c 是一样的表达式,且在计算期间 b 和 c 的值不变,因此:
int d = E * 12 + a + (a + E);
此时,编译器还可能进行代数化简(Algebraic Simplification),如下:
int d = E * 13 + a + a;
这样计算起来就可以节省一些时间。
4.4 数组边界检查消除
假如有一个数组 array,当我们访问数组下标在 [0, array.length) 范围之外的元素时,就会抛出 java.lang.ArrayIndexOutOfBoundsException
异常,也就是数组越界了,例如:
public void test1() {
String[] array = new String[]{"a", "b", "c"};
// 数组越界
String s = array[3];
}
其实是 JVM 在执行的时候隐含了一次边界判断(运行期)。当这样的判断很多时,肯定对性能有一定的影响。
但这个判断看起来似乎又是必要的,就不能优化了吗?
实际上也并非不能,如果把这些判断放在编译期呢?代码在编译的时候,就根据控制流分析(可参考前文的前端编译)是否会产生数组越界,那么在运行期间不是就不用判断了吗?
5. 小结
本文主要分析了即时编译器和提前编译器,主要内容梳理如下:

相关阅读:
JVM笔记-前端编译与优化
JVM笔记-类加载机制
JVM笔记-运行时内存区域划分
本文内容就到这里,希望对大家有所帮助~

【觉得不错,鼓励一下~】
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

