JAVA concurrency -- 阻塞队列ArrayBlockingQueue源码详解
概述
ArrayBlockingQueue 顾名思义,使用数组实现的阻塞队列。今天我们就来详细讲述下他的代码实现
阻塞队列
什么是阻塞队列?
阻塞队列是一种特殊的队列,使用场景为并发环境下。在某种情况下(当线程无法获取锁的时候)线程会被挂起并且在队列中等待,如果条件具备(锁被释放)那么就会唤醒挂起的线程。
通俗点来讲的话,阻塞队列类似于理发店的等待区,当没有理发师空闲的时候,客人会在等待区等待,一旦有了空闲,就会有人自动递补。
类的继承关系
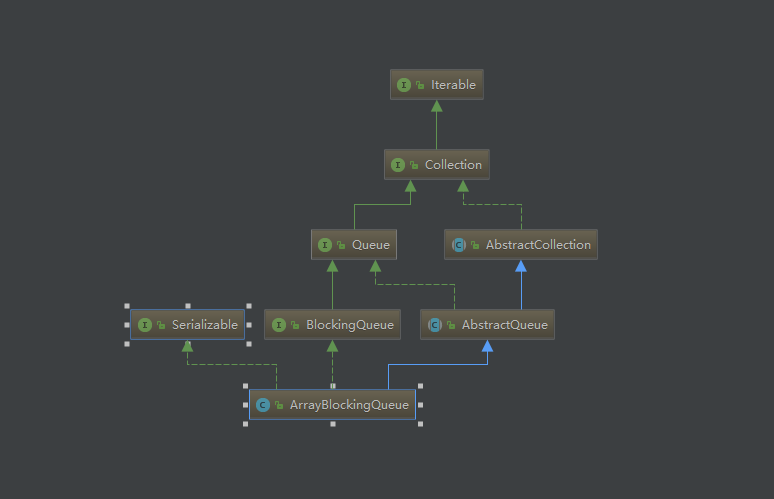
ArrayBlockingQueue 继承了抽象队列,并且实现了阻塞队列,因此它具备队列的所有基本特性。
基本实现原理
ArrayBlockingQueue 的实现是基于 ReentrantLock 以及 AQS 内部实现的锁机制以及 Condition 机制。
ArrayBlockingQueue 内部声明了两个 Condition 变量,一个叫 notEmpty ,一个叫 notFull ,当有数据加入队列时尝试唤醒 notEmpty ,当有数据移除队列时则唤醒 notFull ,从而实现一个类似于生产者消费者模型的机制。
源码分析
类成员变量
// 队列的存储对象数组
final Object[] items;
// 下一个取出的序号
int takeIndex;
// 下一个放入队列的序号
int putIndex;
// 队列中的元素数目
int count;
// 锁以及用来控制队列的两个条件变量
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
transient Itrs itrs = null;
构造函数
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
// 通用的构造函数,以容量和是否公平锁为参数,余下两个构造函数均调用此函数
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
// 调用构造函数
this(capacity, fair);
// 为阻塞队列初始化数据(此操作需要上锁)
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = 0;
try {
// 将集合中的数据存放到数组中并且进行判空操作
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
// 修改count和putIndex的值
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
这里有一点疑问,这里明明是构造函数,是类初始化的地方,照理来说不会产生竞争,为什么要进行加锁操作呢?此处原本有一句原版的注释 Lock only for visibility, not mutual exclusion 锁是为了可见性而不是互斥。这句话怎么理解呢?我们仔细观察代码,发现当我们把集合中的数据全部插入队列中之后,我们会修改相应的 count 以及 putIndex 的数值,但是如果我们没有加锁,那么在集合插入完成前 count 以及 putIndex 没有完成初始化操作的时候如果有其他线程进行了插入等操作的话,会造成数据同步问题从而使得数据不准确,因此这里的锁是必要的。
队列操作
基础队列操作enqueue和dequeue
// 队列的插入操作
private void enqueue(E x) {
// 本地声明一个item数组的引用
final Object[] items = this.items;
// 将元素放入数组中
items[putIndex] = x;
// 如果此时已经到了数组的末尾了,将putIndex重置为0
if (++putIndex == items.length)
putIndex = 0;
// 元素数目加1
count++;
// 发出通知告诉所有取数据的线程可以取数据
notEmpty.signal();
}
// 队列的移除操作
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
// 找到要移除的数据置空
E x = (E) items[takeIndex];
items[takeIndex] = null;
// 如果此时已经到了数组的末尾了,将takeIndex重置为0
if (++takeIndex == items.length)
takeIndex = 0;
// 元素数目减1
count--;
// 迭代器操作,这个之后再说
if (itrs != null)
itrs.elementDequeued();
// 发出通知告知插入线程可以工作
notFull.signal();
return x;
}
这两个方法是队列操作的基本方法,基本上就是常规的数组数据插入移除,只是有一点很让人困惑 final Object[] items = this.items; 这段代码实现将类成员对象在本地创建了一个引用,然后在本地使用引用进行操作,为什么要多此一举呢?除此之外,代码中大量用到了这种手法,例如: final ReentrantLock lock = this.lock; 这又是为了什么呢?对此笔者猜测可能是和优化相关,因为jdk7中的实现与之不同,是使用的类变量直接操作。在进行了资料查阅后,笔者找到了一个相对靠谱的解释:
这是ArrayBlockingQueue的作者Doug Lea的习惯,他认为这种书写习惯是对机器更加友好的书写
当然也有一些大神有一些其他的解释:
final本身是不可变的,但是由于反射以及序列化操作的存在,final的不可变性就变得捉摸不定,除此之外一些编译器层面上在final上优化的不够好,导致会在使用到数据的时候反复重载导致缓存失效
希望大家可以自己认真思考下,然后尝试下,得到自己的结论。
阻塞队列的插入操作
public boolean offer(E e) {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 如果阻塞队列已满,那么插入失败
if (count == items.length)
return false;
else {
// 否则插入成功
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
阻塞队列插入操作大致就以上几种,这几种的区别在代码中也体现得比较清楚了:
-
offer返回的是布尔值,插入成功返回true否则(队列已满)返回false -
put没有返回值,假如队列是满的,他会一直阻塞直到队列为空的时候执行插入操作 -
add实际上调用的就是offer,只是他在加入失败后会抛出异常
阻塞队列的移除操作
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return itemAt(takeIndex);
} finally {
lock.unlock();
}
}
poll take peek
迭代器实现
由于迭代器和内部队列共享数据,再加上阻塞队列的特性,导致为了实现迭代器功能,需要新增一些很复杂的代码实现。
内部声明了两个类来实现迭代器,一个是 Itr 继承 Iterator<E> ,一个则是 Itrs 。
Itrs
Itrs 是用来管理迭代器的。由于阻塞队列内部可能会有多个迭代器在同时工作,在迭代器内部发生删除或者是一些不常见的操作时可能会产生一些问题,比如他们会丢失自己的数据之类的。所以 Itrs 内部会维护一个变量用于记录循环的圈数,并且在删除操作 removeAt 的时候会通知所有的迭代器。
class Itrs {
// 创建一个Node类作为单向链表(节点是弱引用)来管理迭代器
private class Node extends WeakReference<Itr> {
Node next;
Node(Itr iterator, Node next) {
super(iterator);
this.next = next;
}
}
// 循环圈数
int cycles = 0;
// 链表头
private Node head;
// 清理相关的变量
private Node sweeper = null;
private static final int SHORT_SWEEP_PROBES = 4;
private static final int LONG_SWEEP_PROBES = 16;
Itrs(Itr initial) {
register(initial);
}
// 清理无效的迭代器(如果sweeper为空,则从头开始,否则从sweeper记录的节点开始)
void doSomeSweeping(boolean tryHarder) {
}
// 新增加一个迭代器
void register(Itr itr) {
head = new Node(itr, head);
}
// 当takeIndex为0时调用此方法
void takeIndexWrapped() {
// cycle数+1,内部实现通知所有迭代器并进行清理(链表遍历)
}
// 有移除操作的时候调用此方法,并通知所有迭代器进行清理
void removedAt(int removedIndex) {
// 简单的链表遍历,内部调用Itr的removedAt方法
}
// 当发现队列为空的时候调用此方法,清理迭代器内的弱引用
void queueIsEmpty() {
}
// 有元素被取时是调用
void elementDequeued() {
// 如果数组为空调用queueIsEmpty进行清理
if (count == 0)
queueIsEmpty();
// 如果takeIndex为0,调用takeIndexWrapped,来进行循环+1操作
else if (takeIndex == 0)
takeIndexWrapped();
}
}
Itr
Itrs 是管理迭代器的, Itr 则是迭代器的具体实现
private class Itr implements Iterator<E> {
// 游标,用于寻找下一个元素
private int cursor;
// 下一个元素
private E nextItem;
// 下一个元素的下标
private int nextIndex;
// 上一个元素
private E lastItem;
// 上一个元素的下标
private int lastRet;
// 上一个take的下标
private int prevTakeIndex;
// 上一个循环
private int prevCycles;
// 标记为空
private static final int NONE = -1;
// 删除标记
private static final int REMOVED = -2;
// DETACH标记专用于prevTakeIndex
private static final int DETACHED = -3;
Itr() {
// 这是构造函数,内部实现主要是初始化为主,
// 并且在Itrs不为空的时候进行一波清理操作
}
boolean isDetached() {
return prevTakeIndex < 0;
}
private int incCursor(int index) {
// 游标+1,并重新计算值(判断是否走完一个循环,是否等于putIndex)
if (++index == items.length)
index = 0;
if (index == putIndex)
index = NONE;
return index;
}
// 判断给的删除数是否是有效值
private boolean invalidated(int index, int prevTakeIndex,
long dequeues, int length) {
}
// 计算在迭代器的上一次操作后所有的删除(出队)操作
private void incorporateDequeues() {
// 主要方法为通过当前圈数和之前的圈数以及偏移量计算
// 真实的删除数,并且和prevTakeIndex以及index的偏移量进行比较
}
// 进行detach操作并进行清理
private void detach() {
}
// 判断是否有下一个节点
public boolean hasNext() {
}
// 没有下一个节点(没有detach的节点将会被执行detach操作)
private void noNext() {
}
// 找到下个节点
public E next() {
// 实现不复杂,主要是需要判断节点是否是detach模式
}
// 删除节点
public void remove() {
}
// 当队列为空或者后续很难找到下个节点的时候通知迭代器
void shutdown() {
}
// 辅助计算游标和prevTakeIndex之间的距离
private int distance(int index, int prevTakeIndex, int length) {
}
// 删除节点
boolean removedAt(int removedIndex) {
}
// 当takeIndex归0时调用
boolean takeIndexWrapped() {
}
}
总结
ArrayBlockingQueue 的实现可以说是比较的简单清晰,主要是利用了 ReentrantLock 内部的 Condition ,通过设置两个条件来巧妙地完成阻塞队列的实现,只要能够理解这两个条件的工作原理,源码的理解就没有太大的难度。 ArrayBlockingQueue 较难理解的反而是它内部的迭代器,由于阻塞队列的特性,他的迭代器可能会有丢失当前数据的风险,因此,作者创作的时候加入了许多复杂的方法来保证可靠性,但是在这里由于篇幅限制,以及迭代器在阻塞队列中的地位和重要性并不高,所以简单讲述,如果有兴趣可以自己找一份源码阅读。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

