Java 8 Stream 总结
Classes to support functional-style operations on streams of elements, such as map-reduce transformations on collections.
Stream 是 Java 8 新特性,可对 Stream 中元素进行函数式编程操作,例如 map-reduce。
先来看一段代码:
int sum = widgets.stream()
.filter(b -> b.getColor() == RED)
.mapToInt(b -> b.getWeight())
.sum();
这段 Java 代码看起来是不是像通过 SQL 来操作集合:
select sum(weight) from widgets where color='RED';
Stream 类型
java.util.stream 包下提供了一下四种类型的 Stream:
Stream IntStream LongStream DoubleStream
如何获得 Stream
Collection to Stream
List 、 Set 等 Collection 接口的实现类,可以通过 Collection.stream() 或 Collection.parallelStream() 方法返回 Stream 对象:
List<String> stringList = ...; Stream<String> stream = stringList.stream();
Array to Stream
可以通过静态方法 Arrays.stream(T[] array) 或 Stream.of(T... values) 将数组转为 Stream:
String[] stringArray = ...; Stream<String> stringStream1 = Arrays.stream(stringArray); // 方法一 Stream<String> stringStream2 = Stream.of(stringArray); // 方法二
基本类型数组可以通过类似的方法转为 IntStream 、 LongStream 、 DoubleStream :
int[] intArray = {1, 2, 3};
IntStream intStream1 = Arrays.stream(intArray);
IntStream intStream2 = IntStream.of(intArray);
另外, Stream.of(T... values) 、 IntStream.of(int... values) 等静态方法支持 varargs(可变长度参数),可直接创建 Stream:
IntStream intStream = IntStream.of(1, 2, 3);
Map to Stream
Map 本身不是 Collection 的实现类,没有 stream() 或 parallelStream() 方法,可以通过 Map.entrySet() 、 Map.keySet() 、 Map.values() 返回一个 Collection :
Map<Integer, String> map = ...; Stream<Map.Entry<Integer, String>> stream = map.entrySet().stream();
其他
String 按字符拆分成 IntStream :
String s = "Hello World"; IntStream stringStream = s.chars(); // 返回将字符串每个 char 转为 int 创建 Stream
BufferedReader 生成按行分隔的 Stream<String> :
BufferedReader bufferedReader = ...; Stream<String> lineStream = bufferedReader.lines();
IntStream 、 LongStream 提供了静态方法 range 生成对应的 Stream:
IntStream intStream = IntStream.range(1, 5); // 1,2,3,4 (不包含5)
Stream 的方法
intermediate operation 和 terminal operation
Stream operations are divided into intermediate and terminal operations, and are combined to form stream pipelines. A stream pipeline consists of a source (such as a Collection , an array, a generator function, or an I/O channel); followed by zero or more intermediate operations such as Stream.filter or Stream.map ; and a terminal operation such as Stream.forEach or Stream.reduce .
Stream 操作分为 中间操作(intermediate operation)和 最终操作(terminal operation),这些操作结合起来形成 stream pipeline。stream pipeline 包含一个 Stream 源,后面跟着零到多个 intermediate operations(例如 Stream.filter 、 Stream.map ),再跟上一个 terminal operation(例如 Stream.forEach 、 Stream.reduce )。
intermediate operation 用于对 Stream 中元素处理和转换,terminal operation 用于得到最终结果。
例如在本文开头的例子中,包含以下 intermediate operation 和 terminal operation:
int sum = widgets.stream()
.filter(b -> b.getColor() == RED) // intermediate operation
.mapToInt(b -> b.getWeight()) // intermediate operation
.sum(); // terminal operation
intermediate operation
Intermediate operations return a new stream. They are always lazy; executing an intermediate operation such as filter() does not actually perform any filtering, but instead creates a new stream that, when traversed, contains the elements of the initial stream that match the given predicate. Traversal of the pipeline source does not begin until the terminal operation of the pipeline is executed.
intermediate operation 会再次返回一个新的 Stream,所以可以支持链式调用。
intermediate operation 还有一个重要特性,延迟(lazy)性:
IntStream.of(0, 1, 2, 3).filter(i -> {
System.out.println(i);
return i > 1;
});
以上这段代码并不会输出: 1 2 3 4 ,实际上这段代码运行后没有任何输出,也就是 filter 并未执行。因为 filter 是一个 intermediate operation,如果想要 filter 执行,必须加上一个 terminal operation:
IntStream.of(0, 1, 2, 3).filter(i -> {
System.out.println(i);
return i > 1;
}).sum();
intermediate operation 常用方法
-
filter: 按条件过滤,类似于 SQL 中的where语句 -
limit(long n): 截取 Stream 的前 n 条数据,生成新的 Stream,类似于 MySQL 中的limit n语句 -
skip(long n): 跳过前 n 条数据,结合limit使用stream.skip(offset).limit(count),效果相当于 MySQL 中的LIMIT offset,count语句 -
sorted: 排序,类似于 SQL 中的order by语句 -
distinct: 排除 Stream 中重复的元素,通过equals方法来判断重复,这个和 SQL 中的distinct类似 -
boxed: 将IntStream、LongStream、DoubleStream转换为Stream<Integer>、Stream<Long>、Stream<Double> -
peek: 类似于forEach,二者区别是forEach是 terminal operation,peek是 intermediate operation -
map、mapToInt、mapToLong、mapToDouble、mapToObj: 这些方法会传入一个函数作为参数,将 Stream 中的每个元素通过这个函数转换,转换后组成一个新的 Stream。mapToXxx中的 Xxx 表示转换后的元素类型,也就是传入的函数返回值,例如 mapToInt 就是将原 Stream 中的每个元素转为 int 类型,最终返回一个 IntStream -
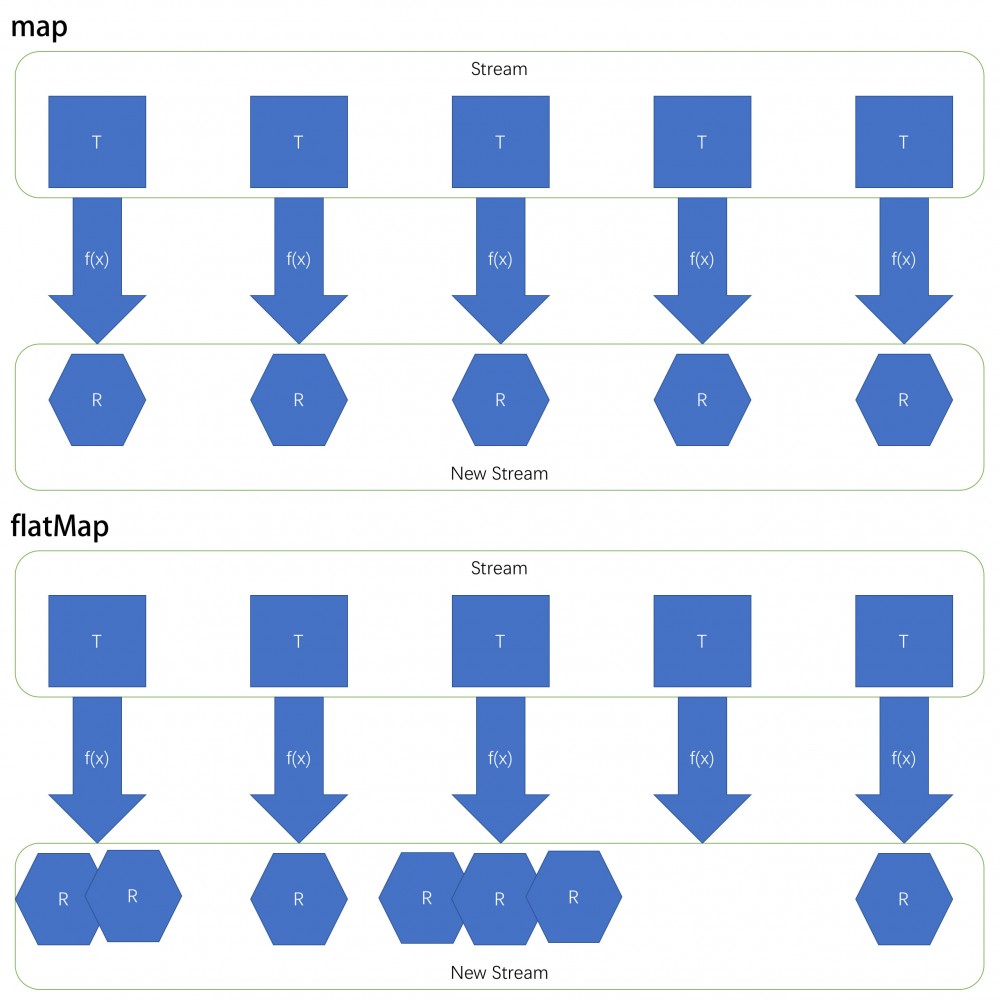
flatMap、flatMapToInt、flatMapToLong、flatMapToDouble: 类似map、mapToXxx,不同的是flatMap会将一个元素转为一个 Stream,其中可包含0到多个元素,最终将每个 Stream 中的所有元素组成一个新的 Stream 返回
map、flatMap 区别
map 和 flatMap 的区别就是 map 是一对一, flatMap 是一对零到多,可以用下图简单说明:
-
map示例通过
mapToInt获取一个字符串集合中每个字符串长度:Stream<String> stringStream = Stream.of("test1", "test23", "test4"); IntStream intStream = stringStream.mapToInt(String::length);通过
String.length函数可以将每个 String 转为一个 int,最终组成一个 IntStream。以上代码中的stringStream和intStream中的元素是一一对应的,每个字符串对应一个长度,两个 Stream 的元素数量是一致的。 -
flatMap示例通过
flatMapToInt将一个字符串集合中每个字符串按字符拆分,组成一个新的 Stream:Stream<String> stringStream = Stream.of("test1", "test23", "test4"); IntStream intStream = stringStream.flatMapToInt(String::chars);每个字符串按字符拆分后可能会得到 0 到多个字符,最终得到的
intStream元素数量和stringStream的元素数量可能不一致。
以下表格列出了所有map相关的方法以及转换规则:
| Stream | 方法 | 函数类型 | 函数参数 | 函数返回值 | 转换后 |
|---|---|---|---|---|---|
| Stream
|
map | Function | T | R | Stream
|
| Stream
|
mapToInt | ToIntFunction | T | int | IntStream |
| Stream
|
mapToLong | ToLongFunction | T | long | LongStream |
| Stream
|
mapToDouble | ToDoubleFunction | T | double | DoubleStream |
| Stream
|
flatMap | Function | T | Stream
|
Stream
|
| Stream
|
flatMapToInt | Function | T | IntStream | IntStream |
| Stream
|
flatMapToLong | Function | T | LongStream | LongStream |
| Stream
|
flatMapToDouble | Function | T | DoubleStream | DoubleStream |
| IntStream | map | IntUnaryOperator | int | int | IntStream |
| IntStream | mapToLong | IntToLongFunction | int | long | LongStream |
| IntStream | mapToDouble | IntToDoubleFunction | int | double | DoubleStream |
| IntStream | mapToObj | IntFunction | int | R | Stream
|
| IntStream | flatMap | IntFunction | int | IntStream | IntStream |
| LongStream | map | LongUnaryOperator | long | long | LongStream |
| LongStream | mapToInt | LongToIntFunction | long | int | IntStream |
| LongStream | mapToDouble | LongToDoubleFunction | long | double | DoubleStream |
| LongStream | mapToObj | LongFunction | long | R | Stream
|
| LongStream | flatMap | LongFunction | long | LongStream | LongStream |
| DoubleStream | map | DoubleUnaryOperator | double | double | DoubleStream |
| DoubleStream | mapToInt | DoubleToIntFunction | double | int | IntStream |
| DoubleStream | mapToLong | DoubleToLongFunction | double | long | LongStream |
| DoubleStream | mapToObj | DoubleFunction | double | R | Stream
|
| DoubleStream | flatMap | DoubleFunction | double | DoubleStream | DoubleStream |
例如对一个 Stream<Stirng> 执行 stream.mapToInt(String::length) ,可以理解为将一个参数为 String 返回值为 int 的函数 String::length 传入 mapToInt 方法作为参数,最终返回一个 IntStream 。
terminal operation
Terminal operations, such as Stream.forEach or IntStream.sum, may traverse the stream to produce a result or a side-effect. After the terminal operation is performed, the stream pipeline is considered consumed, and can no longer be used; if you need to traverse the same data source again, you must return to the data source to get a new stream.
当 terminal operation 执行过后,Stream 就不能再使用了,如果想要再使用就必须重新创建一个新的 Stream:
IntStream intStream = IntStream.of(1, 2, 3); intStream.forEach(System.out::println); // 第一次执行 terminal operation forEach 正常 intStream.forEach(System.out::println); // 第二次执行会抛出异常 IllegalStateException: stream has already been operated upon or closed
terminal operation 常用方法
-
forEach: 迭代Stream -
toArray: 转为数组 -
max: 取最大值 -
min: 取最小值 -
sum: 求和 -
count: Stream 中元素数量 -
average: 求平均数 -
findFirst: 返回第一个元素 -
findAny: 返回流中的某一个元素 -
allMatch: 是否所有元素都满足条件 -
anyMatch: 是否存在元素满足条件 -
noneMatch: 是否没有元素满足条件 -
reduce: 执行聚合操作,上面的sum、min、max方法一般是基于reduce来实现的 -
collect: 执行相对reduce更加复杂的聚合操作,上面的average方法一般是基于collect来实现的
reduce
先看一段使用 reduce 来实现 sum 求和的代码:
IntStream intStream = IntStream.of(1, 2, 4, 5, 8); int sum = intStream.reduce(0, Integer::sum);
或者
IntStream intStream = IntStream.of(1, 2, 4, 5, 8); int sum = intStream.reduce(0, (a, b) -> a + b);
上面例子中的 reduce 方法有两个参数:
-
identity: 初始值,当 Stream 中没有元素是也会作为默认值返回 -
accumulator: 一个带有两个参数和一个返回值的函数,例如上面代码中的Integer::sum或者(a, b) -> a + b求和函数
以上代码等同于:
int result = identity;
for (int element : intArray)
result = Integer.sum(result, element); // 或者 result = result + element;
return result;
collect
先看一段代码,将一个 Stream<String> 中的元素拼接成一个字符串,如果用 reduce 可以这样实现:
Stream<String> stream = Stream.of("Hello", "World");
String result = stream.reduce("", String::concat); // 或者 String result = stream.reduce("", (a, b) -> a + b);
当 Stream 中有大量元素是,用字符串拼接方式性能会大打折扣,应该使用性能更高的 StringBuilder ,可以通过 collect 方法来实现:
Stream<String> stream = Stream.of("Hello", "World");
StringBuilder result = stream.collect(StringBuilder::new, StringBuilder::append, StringBuilder::append);
上面例子中的 collect 方法有三个参数:
-
supplier: 传入一个函数,用于创建一个存放聚合计算结果的容器(result container),例如上面的例子中第一个传入参数StringBuilder::new,该函数用于创建一个新的StringBuilder来存放接成字符串的结果 -
accumulator: 传入一个函数,用于将 Stream 中的一个元素合并到 result container 中,例如上面的例子中第二个传入参数StringBuilder::append,该函数用于将 Stream 中的字符串 append 到 StringBuilder 中 -
combiner: 传入一个函数,用于将两个 result container 合并,这个函数一般会在并行流中用到,例如上面的例子中第三个传入参数StringBuilder::append,该函数用于将两个StringBuilder合并
下面再用 collect 实现求平均数:
计算平均数需要有两个关键的数据:数量、总和,首先需要创建一个 result container 存放这两个值,并定义相关方法:
public class Averager {
private int total = 0;
private int count = 0;
public double average() {
return count > 0 ? ((double) total) / count : 0;
}
public void accumulate(int i) {
total += i;
count++;
}
public void combine(Averager other) {
total += other.total;
count += other.count;
}
}
通过计算平均值:
IntStream intStream = IntStream.of(1, 2, 3, 4); Averager averager = intStream.collect(Averager::new, Averager::accumulate, Averager::combine); System.out.println(averager.average()); // 2.5
Collector
Stream 接口中还有一个 collect 的重载方法,仅有一个参数: collect(Collector collector) 。
Collector 是什么:
This class encapsulates the functions used as arguments in the collect operation that requires three arguments (supplier, accumulator, and combiner functions).
Collector 实际上就是一个包含 supplier 、 accumulator 、 combiner 函数的类,可以实现对常用聚合算法的抽象和复用。
例如将 Stream<String> 中的元素拼接成一个字符串,用 Collector 实现:
public class JoinCollector implements Collector<String, StringBuilder, String> {
@Override
public Supplier<StringBuilder> supplier() {
return StringBuilder::new;
}
@Override
public BiConsumer<StringBuilder, String> accumulator() {
return StringBuilder::append;
}
@Override
public BinaryOperator<StringBuilder> combiner() {
return StringBuilder::append;
}
@Override
public Function<StringBuilder, String> finisher() {
return StringBuilder::toString;
}
@Override
public Set<Characteristics> characteristics() {
return Collections.emptySet();
}
}
或者直接用 Collector.of() 静态方法直接创建一个 Collector 对象:
Collector<String, StringBuilder, String> joinCollector = Collector.of(StringBuilder::new,
StringBuilder::append,
StringBuilder::append,
StringBuilder::toString);
Stream<String> stream = Stream.of("Hello", "World");
String result = stream.collect(joinCollector);
另外还有一个更简单的方式,使用 Collectors.joining() :
Stream<String> stream = Stream.of("Hello", "World");
String result = stream.collect(Collectors.joining());
Collectors
在 java.util.stream.Collectors : 中提供了大量常用的 Collector :
-
Collectors.toList(): 将 Stream 转为 List -
Collectors.toSet(): 将 Stream 转为 Set -
Collectors.joining(): 将 Stream 中的字符串拼接 -
Collectors.groupingBy(): 将 Stream 中的元素分组,类似于 SQL 中的group by语句 -
Collectors.counting(): 用于计算 Stream 中元素数量,stream.collect(Collectors.counting())等同于stream.count() -
Collectors.averagingDouble()、Collectors.averagingInt()、Collectors.averagingLong(): 计算平均数
上面只列出了 Collectors 中的一部分方法,还有其他常用的方法可以参考文档。
下面列出一些 Collectors 的实用示例:
-
将 Stream 转为 List:
Stream<String> stream = Stream.of("Hello", "World"); List<String> list = stream.collect(Collectors.toList()); -
将学生(Student)按年龄分组,返回每个年龄对应的学生列表:
Stream<Student> stream = ...; Map<Integer, List<Student>> data = stream.collect(Collectors.groupingBy(Student::getAge));
-
将学生(Student)按年龄分组,返回每个年龄对应的学生数量,实现和 SQL 一样的结果:
select age,count(*) from student group by age:Stream<Student> stream = ...; Map<Integer, Long> data = stream.collect(Collectors.groupingBy(Student::getAge, Collectors.counting()));
-
计算学生(Student)年龄平均数:
Stream<Student> stream = ...; Double data = stream.collect(Collectors.averagingInt(Student::getAge)); // 或者可以 double average = stream.mapToInt(Student::getAge).average().getAsDouble();
参考文档
- https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
- https://docs.oracle.com/javase/tutorial/collections/streams/reduction.html
- https://docs.oracle.com/javase/tutorial/collections/streams/examples/ReductionExamples.java
正文到此结束
- 本文标签: 静态方法 学生 CTO 总结 ORM https UI Collections rmi dist equals Oracle 代码 参数 函数式编程 ip map Select mysql build id find API list http mina tag sql HTML example Collection tar IDE value tab entity stream cat App consumer IO 数据 key java src
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

