浅谈 Java 集合 | 底层源码解析
在 Java 中,我们经常会使用到一些处理缓存数据的集合类,这些集合类都有自己的特点,今天主要分享下 Java 集合中几种经常用的 Map、List、Set。
1、Map
一、背景
二、Map家族
三、HashMap、Hashtable等
四、HashMap 底层数据结构
2、List
一、List 包括的子类
二、ArrayList
三、ArrayList 源码分析
四、LinkedList
五、LinkedList 源码分析
3、Set
一、Set的实质
二、HashSet
三、TreeSet
01
集合 1:Map
背景
如果一个海量的数据中,需要查询某个指定的信息,这时候,可能会犹如大海捞针,这时候,可以使用 Map 来进行一个获取。因为 Map 是键值对集合。Map这种键值(key-value)映射表的数据结构,作用就是通过key能够高效、快速查找value。
举一个例子:
import java.util.HashMap;
import java.util.Map;
import java.lang.Object;
public class Test {
public static void main(String[] args) {
Object o = new Object();
Map<String, Object> map = new HashMap<>();
map.put("aaa", o); //将"aaa"和 Object实例映射并关联
Student target = map.get("aaa"); //通过key查找并返回映射的Obj实例
System.out.println(target == o); //true,同一个实例
Student another = map.get("bbb"); //通过另一个key查找
System.out.println(another); //未找到则返回null
}
}
Map<K, V>是一种键-值映射表,当我们调用put(K key, V value)方法时,就把key和value做了映射并放入Map。当我们调用V get(K key)时,就可以通过key获取到对应的value。如果key不存在,则返回null。和List类似,Map也是一个接口,最常用的实现类是HashMap。
在 Map<K, V> 中,如果遍历的时候,其 key 是无序的,如何理解:
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("dog", "a");
map.put("pig", "b");
map.put("cat", "c");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
cat = c
dog = a
pig = b
从上面的打印结果来看,其是无序的,有序的答案可以在下面找到。
接下来我们分析下 Map ,首先我们先看看 Map 家族:
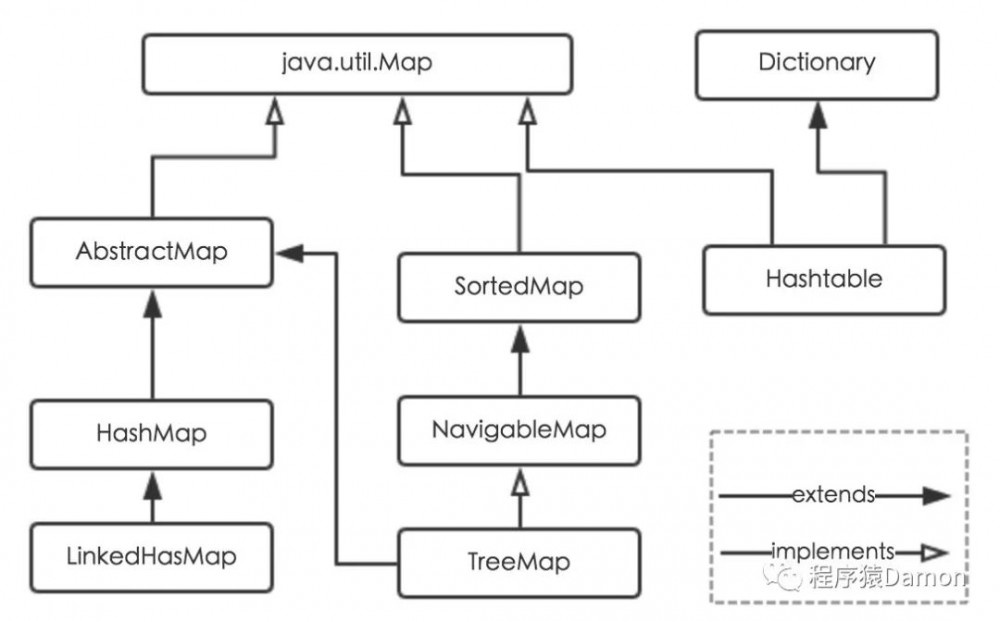
它的子孙下面有我们常用的 HashMap、LinkedHashMap,也有 TreeMap,另外还有继承 Dictionary、实现 Map 接口的 Hashtable。
下面针对各个实现类的特点来说明:
(1)HashMap:它根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有高效的访问速度,但遍历顺序却是不确定的。HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap 非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的静态方法 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap(分段加锁)。
(2)LinkedHashMap:LinkedHashMap 是 HashMap 的一个子类,替 HashMap 完成了输入顺序的记录功能,所以要想实现像输出同输入顺序一致,应该使用 LinkedHashMap。
(3)TreeMap:TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用 TreeMap 时,key 必须实现Comparable 接口或者在构造 TreeMap 传入自定义的 Comparator,否则会在运行时抛出 ClassCastException 类型的异常。
(4)Hashtable:Hashtable继承 Dictionary 类,实现 Map 接口,很多映射的常用功能与 HashMap 类似, Hashtable 采用"拉链法"实现哈希表 ,不同的是它来自 Dictionary 类,并且是线程安全的,任一时间只有一个线程能写 Hashtable,但并发性不如 ConcurrentHashMap,因为ConcurrentHashMap 引入了分段锁。Hashtable 使用 synchronized 来保证线程安全,在线程竞争激烈的情况下 HashTable 的效率非常低下。不建议在新代码中使用,不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换。Hashtable 并不是像 ConcurrentHashMap 对数组的每个位置加锁,而是对操作加锁,性能较差。
上面讲到了 HashMap、Hashtable、 ConcurrentHashMap ,接下来先看看 HashMap 的源码实现:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/**
* 默认大小 16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* 最大容量是必须是2的幂30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 负载因子默认为0.75,hashmap每次扩容为原hashmap的2倍
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 链表的最大长度为8,当超过8时会将链表装换为红黑树进行存储
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
从上面看到,HashMap 主要是数组 + 链表结构组成。HashMap 扩容是成倍的扩容。为什么是成倍,而不是1.5或其他的倍数呢?既然 HashMap 在进行 put 的时候针对 key 做了一些列的 hash 以及与运算就是为了减少碰撞的一个概率,如果扩容后的大小不是2的n次幂的话,之前做的不是白费了吗?
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
扩容后会重新把原来的所有的数据 key 的 hash 重新计算放入扩容后的数组里面去。为什么要这样做?因为不同的数组大小通过 key 的 hash 出来的下标是不一样的。 还有,数组 长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引 in de x 更加均匀。
为何说 Hashmap 是非线程安全的呢?原因:当多线程并发时,检测到总数量超过门限值的时候就会同时调用 resize 操作,各自生成新的数组并rehash 后赋给底层数组,结果最终只有最后一个线程生成的新数组被赋给table 变量,其他线程均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的 table 作为原始数组,这样也是有问题滴。
疑问:
-
HashMap 中某个 entry 链过长,查询时间达到最大限度,如何处理呢?这个在 Jdk1.8,当链表过长,把链表转成红黑树(TreeNode)实现了更高的时间复杂度的查找。
-
HashMap中哈希算法实现?我们使用put(key,value)方法往HashMap中添加元素时,先计算得到key的 Hash 值,然后通过Key高16位与低16位相异或(高16位不变),然后与数组大小-1相与,得到了该元素在数组中的位置, 流程:

-
延伸:如果一个对象中,重写了equals()而不重写hashcode()会发生什么样的问题?尽管我们在进行 get 和 put 操作的时候,使用的key从逻辑上讲是等值的(通过equals比较是相等的),但由于没有重写hashCode(),所以put操作时,key(hashcode1)-->hash-->indexFor-->index,而通过key取出value的时候 key(hashcode2)-->hash-->indexFor-->index,由于hashcode1不等于hashcode2,导致没有定位到一个数组位置而返回逻辑上错误的值null。所以,在重写equals()的时候,必须注意重写hashCode(),同时还要保证通过equals()判断相等的两个对象,调用hashCode方法要返回同样的整数值。而如果equals判断不相等的两个对象,其hashCode也可以相同的(只不过会发生哈希冲突,应尽量避免)。( 1. hash相同,但key不一定相同:key1、key2产生的hash很有可能是相同的,如果key真的相同,就不会存在散列链表了,散列链表是很多不同的键算出的hash值和index相同的 2. key相同,经过两次hash,其hash值一定相同 )
ConcurrentHashMap 采用了分段锁技术来将数据分成一段段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
02
集合 2:List
集合 List 是接口 Collection 的子接口,也是大家经常用到的数据缓存。 List 进 行了元素 排序,且允许存放相同的元素,即有序,可重复 。我们先看看有哪些子类:

可以看到,其中包括比较多的子类,我们常用的是 ArrayList、LinkedList:
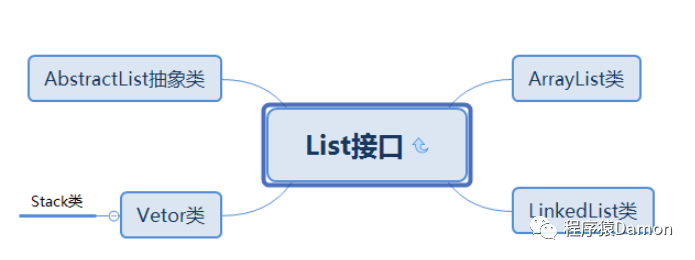
ArrayList:
优点:操作读取操作效率高,基于数组实现的,可以为null值,可以允许重复元素,有序,异步。
缺点:由于它是由动态数组实现的,不适合频繁的对元素的插入和删除操作,因为每次插入和删除都需要移动数组中的元素。
LinkedList:
优点:LinkedList由双链表实现,增删由于不需要移动底层数组数据,其底层是链表实现的,只需要修改链表节点指针,对元素的插入和删除效率较高。
缺点:遍历效率较低。HashMap和双链表也有关系。
ArrayList 底层是一个变长的数组,基本上等同于Vector,但是ArrayList对writeObjec() 和 readObject()方法实现了同步。
transient Object[] elementData;
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
If multiple threads access an <tt>ArrayList</tt> instance
concurrently, and at least one of the threads modifies
the list structurally, it <i>must</i> be synchronized externally.
(A structural modification is any operation that adds or deletes one or more elements, or explicitly resizes the backing array; merely setting the value of an element is not a structural modification.)
This is typically accomplished by synchronizing
on some object that naturally encapsulates the list.
从注释,我们知道 ArrayList 是线程不安全的,多线程环境下要通过外部的同步策略后使用,比如List list = Collections.synchronizedList(new ArrayList(…))。
源码实现:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
当调用add函数时,会调用ensureCapacityInternal函数进行扩容,每次扩容为原来大小的1.5倍,但是当第一次添加元素或者列表中元素个数小于10的话,列表容量默认为10。
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*/
private int size;
扩容原理:根据当前数组的大小,判断是否小于默认值10,如果大于,则需要扩容至当前数组大小的1.5倍,重新将新扩容的数组数据copy只当前elementData,最后将传入的元素赋值给size++位置。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
接下来我们分析为什么 ArrayList 增删很慢,查询很快呢?
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
根据源码可知,当调用add函数时,首先要调用ensureCapacityInternal(size + 1),该函数是进行自动扩容的,效率低的原因也就是在这个扩容上了,每次新增都要对现有的数组进行一次1.5倍的扩大,数组间值的copy等,最后等扩容完毕,有空间位置了,将数组size+1的位置放入元素e,实现新增。
删除时源码:
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
在删除index位置的元素时,要先调用 rangeCheck(index) 进行 index 的check,index 要超过当前个数,则判定越界,抛出异常,throw new IndexOutOfBoundsException(outOfBoundsMsg(index)),其他函数也有用到如:get(int index),set(int index, E element) 等后面删除重点在于计算删除的index是末尾还是中间位置,末尾直接--,然后置空完事,如果是中间位置,那就要进行一个数组间的copy,重新组合数组数据了,这一就比较耗性能了。
而查询:
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
获取指定index的元素,首先调用rangeCheck(index)进行index的check,通过后直接获取数组的下标index获取数据,没有任何多余操作,高效。
LinkedList 继承AbstractSequentialList和实现List接口,新增接口如下:
addFirst(E e):将指定元素添加到刘表开头
addLast(E e):将指定元素添加到列表末尾
descendingIterator():以逆向顺序返回列表的迭代器
element():获取但不移除列表的第一个元素
getFirst():返回列表的第一个元素
getLast():返回列表的最后一个元素
offerFirst(E e):在列表开头插入指定元素
offerLast(E e):在列表尾部插入指定元素
peekFirst():获取但不移除列表的第一个元素
peekLast():获取但不移除列表的最后一个元素
pollFirst():获取并移除列表的最后一个元素
pollLast():获取并移除列表的最后一个元素
pop():从列表所表示的堆栈弹出一个元素
push(E e);将元素推入列表表示的堆栈
removeFirst():移除并返回列表的第一个元素
removeLast():移除并返回列表的最后一个元素
removeFirstOccurrence(E e):从列表中移除第一次出现的指定元素
removeLastOccurrence(E e):从列表中移除最后一次出现的指定元素
LinkedList 的实现原理:LinkedList 的实现是一个双向链表。在 Jdk 1.6中是一个带空头的循环双向链表,而在 Jdk1.7+ 中则变为不带空头的双向链表,这从源码中可以看出:
//jdk 1.6
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;
//jdk 1.7
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
从源码注释看,LinkedList不是线程安全的,多线程环境下要通过外部的同步策略后使用,比如List list = Collections.synchronizedList(new LinkedList(…)):
If multiple threads access a linked list concurrently,
and at least one of the threads modifies the list structurally,
it <i>must</i> be synchronized externally.
(A structural modification is any operation that adds or
deletes one or more elements; merely setting the value of
an element is not a structural modification.)
This is typically accomplished by synchronizing on some object
that naturally encapsulates the list.
为什么说 LinkedList 增删很快呢?
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
从注释看,add函数实则是将元素append至list的末尾,具体过程是:新建一个Node节点,其中将后面的那个节点last作为新节点的前置节点,后节点为null;将这个新Node节点作为整个list的后节点,如果之前的后节点l为null,将新建的Node作为list的前节点,否则,list的后节点指针指向新建Node,最后size+1,当前llist操作数modCount+1。
在add一个新元素时,LinkedList 所关心的重要数据,一共两个变量,一个first,一个last,这大大提升了插入时的效率,且默认是追加至末尾,保证了顺序。
再看删除一个元素:
/**
* Removes the element at the specified position in this list. Shifts any
* subsequent elements to the left (subtracts one from their indices).
* Returns the element that was removed from the list.
*
* @param index the index of the element to be removed
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
删除指定index的元素,删除之前要调用checkElementIndex(index)去check一下index是否存在元素,如果不存在抛出throw new IndexOutOfBoundsException(outOfBoundsMsg(index));越界错误,同样这个check方法也是很多方法用到的,如:get(int index),set(int index, E element)等。
注释讲,删除的是非空的节点,这里的node节点也是通过node(index)获取的,分别根据当前Node得到链表上的关节要素:element、next、prev,分别对 prev 和 next 进行判断,以便对当前 list 的前后节点进行重新赋值,frist和last,最后将节点的element置为null,个数-1,操作数+1。根据以上分析,remove节点关键的变量,是Node实例本身的局部变量 next、prev、item 重新构建内部变量指针指向,以及list的局部变量first和last保证节点相连。这些变量的操作使得其删除动作也很高效。
而对于查询:
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
获取指定index位置的node,获取之前还是调用checkElementIndex(index)进行检查元素,之后通过node(index)获取元素,上文有提到,node的获取是遍历得到的元素,所以相对性能效率会低一些。
03
集合 3:Set
Set 集合在我们日常中,用到的也比较多。用于存储不重复的元素集合,它主要提供下面几种方法:
-
将元素添加进
Set<E>:add(E e) -
将元素从
Set<E>删除:remove(Object e) -
判断是否包含元素:
contains(Object e)
这几种方法返回结果都是 boolean值,即返回是否正确或成功。Set 相当于只存储key、不存储value的Map。我们经常用 Set 用于去除重复元素,因为 重复add同一个 key 时,会返回 false。
public HashSet() {
map = new HashMap<>();
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
Set 子孙中主要有:HashSet、 SortedSet 。HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口,而 TreeSet 实现了 SortedSet接口,从而保证元素是有序的 。
HashSet 添加后输出也是无序的:
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("2");
set.add("6");
set.add("44");
set.add("5");
for (String s : set) {
System.out.println(s);
}
}
}
44
2
5
6
看到输出的顺序既不是添加的顺序,也不是String排序的顺序,在不同版本的JDK中,这个顺序也可能是不同的。
换成TreeSet:
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("2");
set.add("6");
set.add("44");
set.add("5");
for (String s : set) {
System.out.println(s);
}
}
2
44
5
6
在遍历TreeSet时,输出就是有序的,不是添加时的顺序,而是 元素的排序顺序。
注意:添加的元素必须实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
在看和转发是对笔者最大的激励哦!
公众号【 源码笔记 】,专注于Java后端系列框架的源码分析。

正文到此结束
- 本文标签: 集合类 JVM HashSet git UI CEO key http 专注 equals 并发 struct map 空间 Collections DDL id ArrayList stream ip 安全 注释 实例 src Collection LinkedList zab node cat 时间 遍历 同步 IO 索引 缓存 tab 线程 代码 解析 final ConcurrentHashMap 哈希算法 源码 tar 多线程 HTML 锁 数据缓存 HashTable synchronized java Bootstrap App list Word HashMap 静态方法 tk https 数据 CTO value 删除
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

