缓存之路-Caffeine的原理
Caffeine Cache参照了Guava Cache的API,使用方式也基本一样。
Cache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(30, TimeUnit.MINUTES)
.maximumSize(1000)
.build();
// cache.put("key1", "val");
Object val = cache.get("key1", key -> {
return key + "_new";
});
System.out.println(val);
复制代码
关于Caffeine的其他用法,不再赘述,下面主要看看Caffeine相对于其他本地缓存框架有哪些优势,其中的一些算法和思想能够给我们编程带来很大的帮助。
Caffeine的优化
Caffeine 除了提供像 Guava Cache 一样丰富的功能外,在缓存淘汰上使用了更加高效的 W-TinyLFU 算法。
W-TinyLFU 算法结合了 LRU和LFU 算法,先来回顾下这两种算法。
LRU 算法
在 LRUHashMap 提到过,LRU(最近最少被使用),使用队列存储数据项,每次会把被访问的数据移到队头,淘汰时直接淘汰队尾的数据。但偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降。
LFU 算法
LFU(最不经常使用)。他的核心思想是 **“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小” ,**会记录数据访问的次数,当需要进行淘汰操作时,淘汰掉访问次数最少的数据。
LFU和LRU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的。
**
LFU算法淘汰图示:
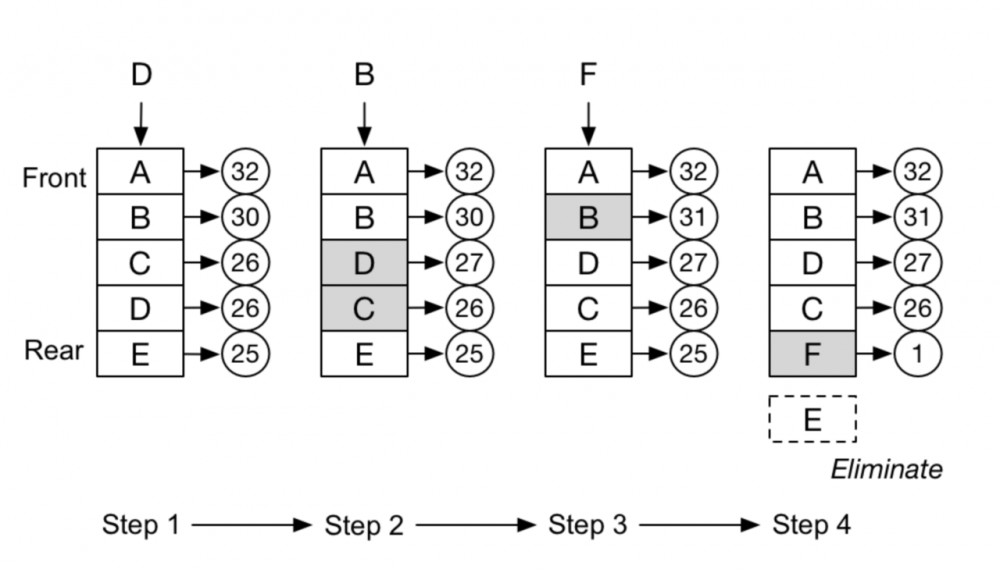
缺点:
LFU算法根据次数进行缓存淘汰,还是以热点数据为例,某天有明星XXX出轨,XXX这个词被搜索了十万次,过了一个月后,热度过去了,大家搜索量少了,但XXX明星出轨的相关数据依然在缓存中,这份数据可能需要很久才能被淘汰掉。
另外,LFU 算法由于需要额外的存储空间记录访问次数,数据量非常大的情况下对于存储的消耗也是很大的。
W-TinyLFU 算法
过期策略
LFU 算法需要额外记录访问次数,最简单的做法就是用一个大的 hashmap 存储每个数据的访问次数,但是当数据量非常大的时候,hashmap 占用的空间也非常大。
在W-TinyLFU中,数据首先会进入到 Window LRU, 从 Window LRU 中淘汰后,会进入到过滤器中过滤,当新来的数据比要驱逐的数据高频时,这个数据才会被缓存接纳,这么做的目的主要是为了使新数据积累一定的访问频率,以便于通过过滤器,进入到后面的缓存段中。
W-TinyLFU 使用 Count-Min Sketch 算法作为过滤器,该算法 是 布隆过滤器 的一种变种。
**
这里简单回顾一下,布隆过滤器的思想是,创建一个数组(同理,也可以是bytes),针对每一个数据进行多次hash,最终将hash后的数组位置置为1(array[hash%length] = 1),并不直接存储数据,由此来判断数据是否可能重复。Count-Min Sketch 算法也是类似的,根据不同的hash算法创建不同的数组,针对每一个数据进行多次hash,并在该hash算法的对应数组hash索引位置上+1,由于hash算法存在冲突,那么在最后取计数的时候,取所有数组中最小的值即可。
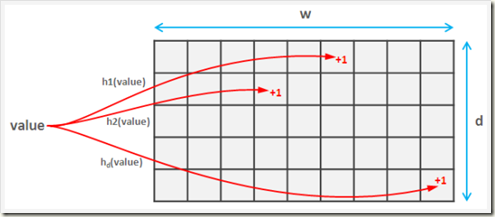
(Count-Min Sketch算法)
在Caffeine的实现中,会先创建一个Long类型的数组,数组的大小为 2,数组的大小为数据的个数,如果你的缓存大小是100,他会生成一个long数组大小是和100最接近的2的幂的数,也就是128。另外,Caffeine将64位的Long类型划分为4段,每段16位,用于存储4种hash算法对应的数据访问频率计数。
分段LRU(SLRU)
对于长期保留的数据,W-TinyLFU 使用了分段 LRU 策略。起初,一个数据项存储被存储在试用段(ProbationDeque)中,在后续被访问到时,它会被提升到保护段(ProtectedDeque)中(保护段占总容量的 80%)。保护段满后,有的数据会被淘汰回试用段,这也可能级联的触发试用段的淘汰。这套机制确保了访问间隔小的热数据被保存下来,而被重复访问少的冷数据则被回收。
读写优化
Guava Cache读写时会夹杂着缓存淘汰的操作,所以在读写操作时会浪费一部分性能。在Caffine中,这些事件操作都是异步的,他将这些事件提交到队列中。然后会通过默认的ForkJoinPool.commonPool(),或者自己配置线程池,进行取队列操作,然后在进行后续的淘汰,过期操作。读和写操作分别有自己的队列。
readBuffer
读队列采用 RingBuffer(参考: 你应该知道的高性能无锁队列Disruptor ),为了进一步减少读并发,采用多个 RingBuffer(striped ring buffer 条带环形缓冲),通过线程 id 哈希到对应的RingBuffer。环形缓存的一个显著特点是不需要进行 GC,直接通过覆盖过期数据。
当一个 RingBuffer 容量满载后,会触发异步的执行操作,而后续的对该 ring buffer 的写入会被丢弃,直到这个 ring buffer 可被使用,因此 readBuffer 记录读缓存事务是有损的。因为读记录是为了优化驱策策略,允许他有损。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

