聊一聊过滤器与监听器

不少读者催我写「过滤器和监听器」,于是我就又来了。
什么是过滤器?
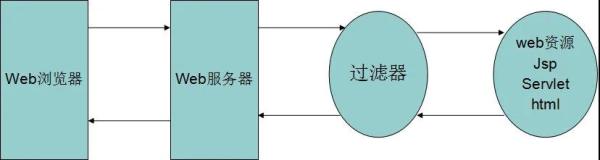
我们很容易发现,过滤器可以比喻成一张滤网。我们想想现实中的滤网可以做什么:在泡茶的时候,过滤掉茶叶。那滤网是怎么过滤茶叶的呢?规定大小的网孔,只要网孔比茶叶小,就可以实现过滤了!
引申在Web容器中,过滤器可以做:过滤一些敏感的字符串【规定不能出现敏感字符串】、避免中文乱码【规定Web资源都使用UTF-8编码】、权限验证等等等,过滤器的作用非常大,只要发挥想象就可以有意想不到的效果

这次的PDF共有「58」页,PDF涉及到的内容:
- 过滤器入门和应用
- 监听器入门和应用
- 几道简单的过滤器和监听器面试题
过滤器的知识点
「学某项技术之前,首先要知道它能干什么,学了这项技术有什么好处,再细学」
知道了什么是过滤器以后,其实我们学的东西就不是很多了,感觉花半天就能学完了。
首先,我们来认识一下Filter接口和相对应的doFilter()方法以及它的参数。
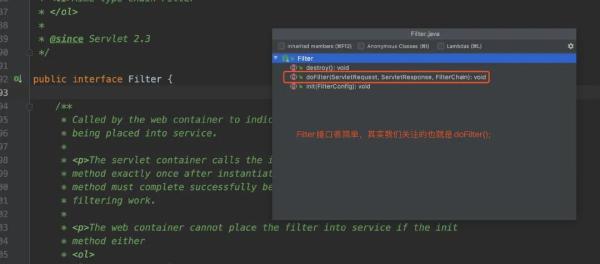
学过我之前的「Servlet」教程,对doFilter()里边的ServletRequest和ServletResponse应该就很了解了,我这里也不赘述了。唯一可能让人难以理解的就是FilterChain这个接口。
而FilterChain接口里边其实也是一个doFilter方法。
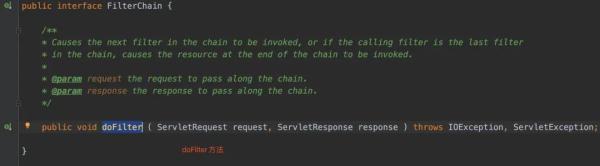
我们可以这样理解:过滤器不单单只有一个,那么我们怎么管理这些过滤器呢?在Java中就使用了链式结构。把所有的过滤器都放在FilterChain里边,如果符合条件,就执行下一个过滤器(如果没有过滤器了,就执行目标资源)。
上面的话好像有点拗口,我们可以想象生活的例子:现在我想在茶杯上能过滤出石头和茶叶出来。石头在一层,茶叶在一层。所以茶杯的过滤装置应该有两层滤网。这个过滤装置就是FilterChain,过滤石头的滤网和过滤茶叶的滤网就是Filter。在石头滤网中,茶叶是属于下一层的,就把茶叶放行,让茶叶的滤网过滤茶叶。过滤完茶叶了,剩下的就是茶
对上面的API了解完了以后,我们试着自己写一个过滤器(实际上就是实现Filter接口,重写doFilter()方法),然后以注解/xml配置的方式来部署自己的过滤器。
随后看一下FilterChain的执行顺序是不是自己配置的那样,再写几个常见的过滤器应用就好了,比如说「禁止浏览器缓存」「实现自动登录」「编码过滤器」「敏感词过滤器」「压缩资源过滤器」「HTML转义过滤器」「缓存数据」…

工作中用「过滤器」多吗?
三歪在工作时间不长哈,接触了好多些系统,由我们自己去写「过滤器」的场景还是不多的。但我觉得有一点可以好好学学,就是「责任链模式」。
之前为啥我写了一篇「责任链模式」,其实就是这个设计模式在系统中用得挺多的,号称能搞掂if else。
过滤器其实也是责任链模式的一种实现,FilterChain层层往下执行,直到最后没有过滤器,就到了「目标资源」

什么是监听器?
监听器就是一个实现特定接口的普通Java程序,这个程序专门用于监听一个Java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行。
上面这句话应该也很好理解,比如说我有一个SanWai对象,里边有一个eat()方法。每当SanWai.eat()的时候,我的监听器可以监听到SanWai.eat()被调用了,于是我们就可以搞一波逻辑,做别的事了。
- 比如说,三歪女朋友发现三歪要吃饭了,于是打电话让三歪少吃点。
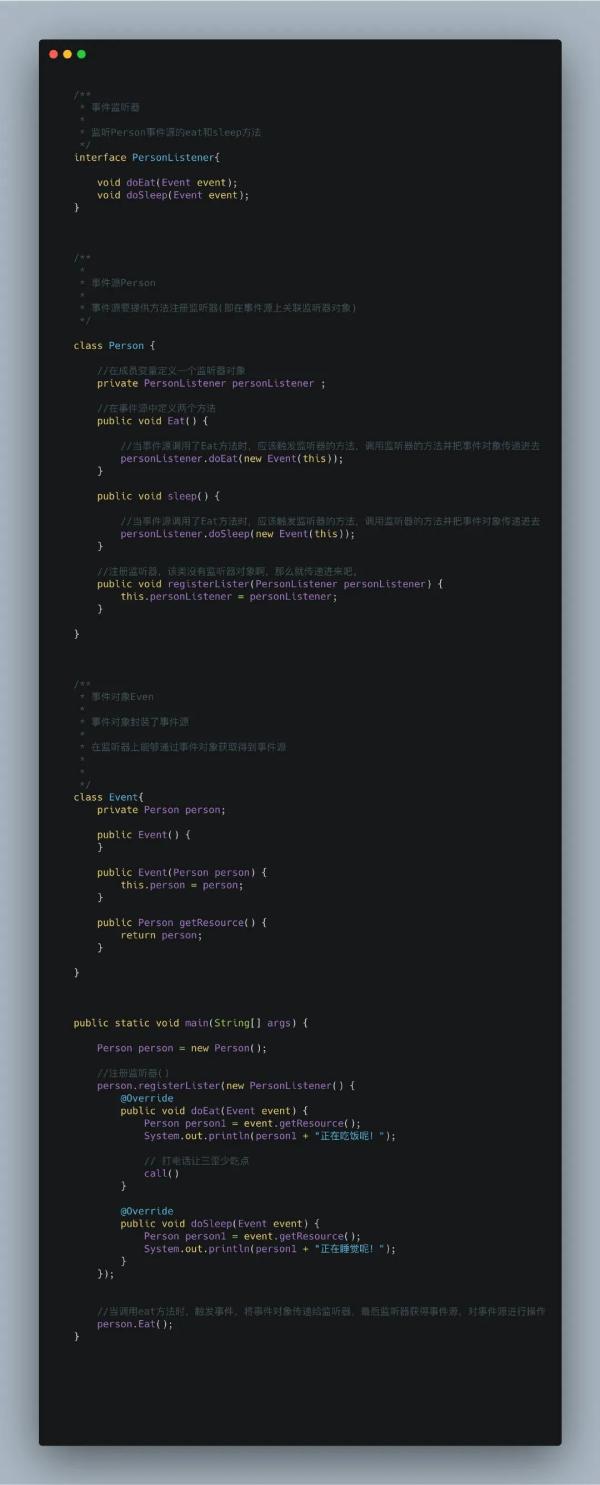
回到Servlet层面上,我们更多的监听的是「Session」「Request」「ServletContext」这几个对象的创建/销毁/属性内的变化。
针对监听上面的几个对象,我们可以做出一些小例子,比如说「统计网站的在线人数」「自动踢人」「定时清除Session的值」

监听器在工作中用得多吗?
监听器在写业务代码的时候,同样也用得不多,我几乎没怎么写过监听器的代码。
但是理解监听器这个概念我觉得还是很有必要的。以我的理解,大概可以认为「A发生了变化,B需要依赖A发生的变化做出处理」,这就是监听器。
有人认为,这不就是「事件驱动」吗?我觉得也可以那样理解。
监听器和过滤器再总结
监听器和过滤器在工作中可能让我们自己「手写」的概率不是很大,但我觉得这两个技术还是需要了解的。如果你了解过Struts2,你就会发现Struts2就是用的过滤器来实现很多的功能。监听器在Spring源码里边也有很多的实现,我觉得都可以看看。
过滤器和监听器还是需要理解它的思想,这块对我们学习Spring也是很有帮助的。
现在已经工作有一段时间了,为什么还来写过滤器和监听器呢,原因有以下几个:
- 我是一个对排版有追求的人,如果早期关注我的同学可能会发现,我的GitHub、文章导航的read.me会经常更换。现在的GitHub导航也不合我心意了(太长了),并且早期的文章,说实话排版也不太行,我决定重新搞一波。
- 我的文章会分发好几个平台,但文章发完了可能就没人看了,并且图床很可能因为平台的防盗链就挂掉了。又因为有很多的读者问我:”你能不能把你的文章转成PDF啊?“
- 我写过很多系列级的文章,这些文章就几乎不会有太大的改动了,就非常适合把它们给”持久化“。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

