面试官再问currentHashMap,就将这篇文章甩给他
点击上方 "IT牧场" ,选择 "设为星标"
技术干货每日送达!
currentHashMap的介绍
currentHashMap 是线程安全并且高效的一种容器,我们就需要研究一下 currentHashMap 为什么既能够保证线程安全,又可以保证高效的操作。
为什么使用 currentHashMap ,我们就需要和 HashMap 以及 HashTable 进行比较?
HashMap 是线程不安全的,在多线程的情况下, HashMap 的操作会引起死循环,导致 CPU 的占有量达到100%,所以在并发的情况下,我们不会使用 HashMap 。
死锁原因
在 HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
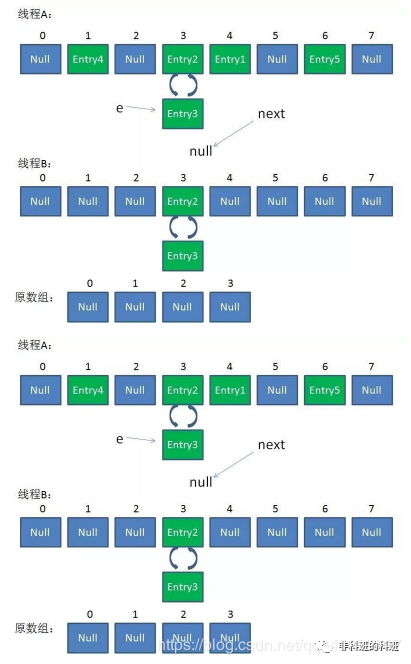
HashTable 其中使用synchronize来保证线程安全,即当有一个线程拥有锁的时候,其他的线程都会进入阻塞或者轮询状态,这样会使得效率越来越低。
而 currentHashMap 的锁分段技术可以有效的提高并发访问率
HashTable 访问效率低下的原因,就是因为所有的线程在竞争同一把锁。
如果容器中有多把锁,不同的锁锁定不同的位置,这样线程间就不会存在锁的竞争,这样就可以有效的提高并发访问效率,这就是 currentHashMap 所使用的锁分段技术将数据一段一段的存储,为每一段都配一把锁,当一个线程只是占用其中的一个数据段时,其他段的数据也能被其他线程访问。
jdk7 的currentHashMap
在 JDK1.7 中 ConcurrentHashMap 采用了 数组+Segment+分段锁 的方式实现。
采用 Segment (分段锁)来减少锁的粒度, ConcurrentHashMap 中的分段锁称为 Segment ,它即类似于 HashMap 的结构,即内部拥有一个 Entry 数组,数组中的每个元素又是一个链表,同时又是一个 ReentrantLock ( Segment 继承了 ReentrantLock )。
currentHashMap内部结构
ConcurrentHashMap 使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
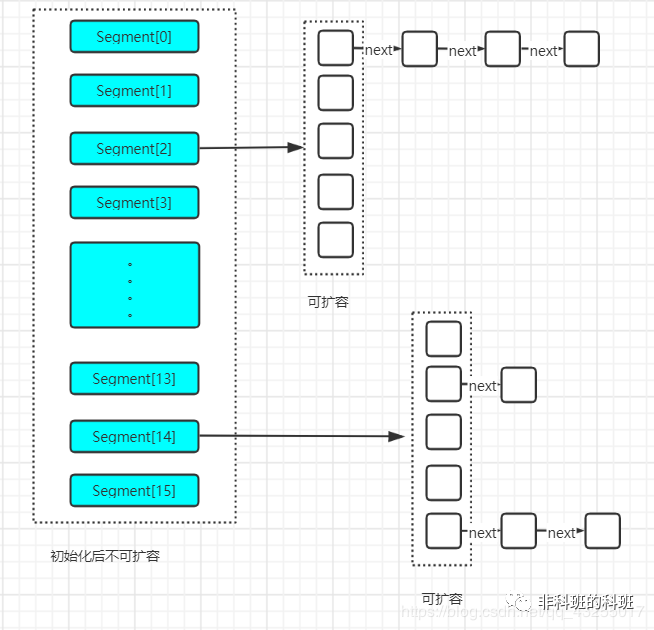
Segment 默认是
16 ,按理说最多同时支持
16 个线程并发读写,但是是操作不同的
Segment ,初始化时也可以指定
Segment 数量,每一个
Segment
都会有一把锁,保证线程安全。
该结构的优劣势
-
坏处是这一种结构的带来的副作用是
Hash的过程要比普通的HashMap要长。 -
好处是写操作的时候可以只对元素所在的
Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
所以,通过这一种结构, ConcurrentHashMap 的并发能力可以大大的提高。
JDK1.8的currentHashMap
JDK1.8 的 currentHashMap 参考了 1.8HashMap 的实现方式,采用了 数组+链表+红黑树 的实现方式,其中大量的使用 CAS 操作. CAS (compare and swap)的缩写,也就是我们说的比较交换。
CAS 是一种基于锁的操作,而且是乐观锁。java的锁中分为乐观锁和悲观锁。悲观锁是指将资源锁住,等待当前占用锁的线程释放掉锁,另一个线程才能够获取线程.乐观锁是通过某种方式不加锁,比如说添加version字段来获取数据。
CAS 操作包含三个操作数(内存位置,预期的原值,和新值)。如果内存的值和预期的原值是一致的,那么就转化为新值。 CAS 是通过不断的循环来获取新值的,如果线程中的值被另一个线程修改了,那么A线程就需要自旋,到下次循环才有可能执行。
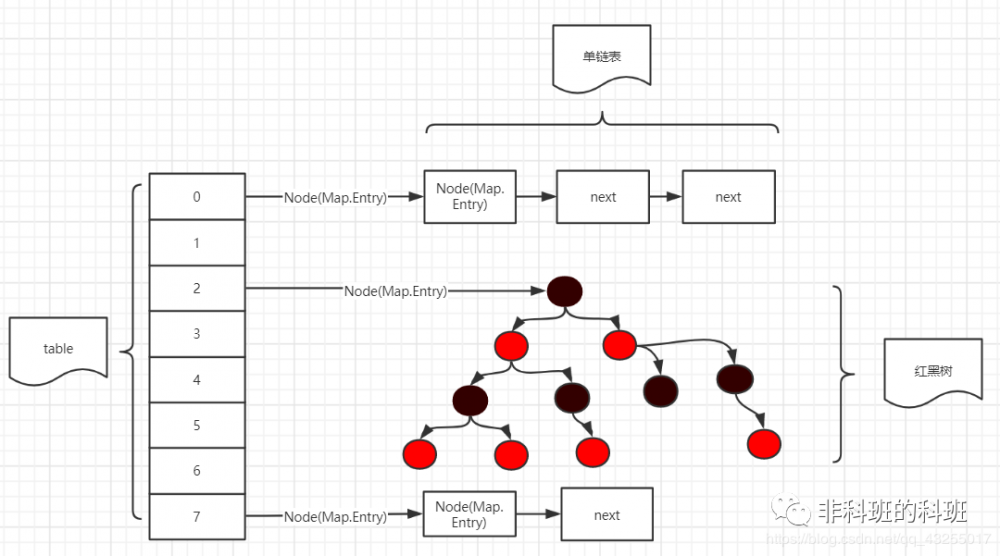
JDK8 中彻底放弃了 Segment 转而采用的是 Node ,其设计思想也不再是 JDK1.7 中的分段锁思想。
Node :保存 key , value 及 key 的 hash 值的数据结构。其中 value 和 next 都用 volatile 修饰,保证并发的可见性。
Java8 的 ConcurrentHashMap 结构基本上和 Java8 的 HashMap 一样,不过保证线程安全性。在 JDK8 中 ConcurrentHashMap 的结构,由于引入了红黑树,使得 ConcurrentHashMap 的实现非常复杂。
我们都知道,红黑树是一种性能非常好的二叉查找树,其查找性能为 O(logN) ,早期完全采用链表结构时 Map 的查找时间复杂度为 O(N) , JDK8 中 ConcurrentHashMap 在链表的长度大于某个阈值的时候会将链表转换成红黑树进一步提高其查找性能。
总结
看完了整个 HashMap 和 ConcurrentHashMap 在 1.7 和 1.8 中不同的实现方式相信大家对他们的理解应该会更加到位。其实这块也是面试的重点内容,通常的套路是:
-
谈谈你理解的 HashMap,讲讲其中的 get put 过程。
-
1.8 做了什么优化?
-
是线程安全的嘛?
-
不安全会导致哪些问题?
-
如何解决?有没有线程安全的并发容器?
-
ConcurrentHashMap 是如何实现的?1.7、1.8 实现有何不同?为什么这么做?
这一串问题相信大家仔细看完都能怼回面试官。
干货分享
最近将个人学习笔记整理成册,使用PDF分享。关注我,回复如下代码,即可获得百度盘地址,无套路领取!
• 001:《Java并发与高并发解决方案》学习笔记; • 002:《深入JVM内核——原理、诊断与优化》学习笔记; • 003:《Java面试宝典》 • 004:《Docker开源书》 • 005:《Kubernetes开源书》 • 006:《DDD速成(领域驱动设计速成)》 • 007: 全部 • 008: 加技术讨论群
近期热文
想知道更多?长按/扫码关注我吧↓↓↓  >>>技术讨论群<<< 喜欢就点个 "在看" 呗^_^
>>>技术讨论群<<< 喜欢就点个 "在看" 呗^_^
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

