为什么Java的泛型要用"擦除"实现
在 Java 中的 泛型 ,常常被称之为 伪泛型 ,究其原因是因为在实际代码的运行中,将实际类型参数的信息擦除掉了 (Type Erasure) 。那是什么原因导致了 Java 做出这种妥协的呢?下面我就带着大家以 Java 语言设计者的角度,带领大家一起了解这里面的辛酸过往。
什么是真泛型
在了解 Java "伪泛型" 之前,我们先简单讲一讲"真泛型"与“伪泛型”的区别。
- 真泛型:泛型中的类型是真实存在的。
- 伪泛型:仅于编译时类型检查,在运行时擦除类型信息。
编程语言实现“真泛型”的一般思路
一般编程语言引入泛型的思路,都是通过 编译时膨胀法 。
以 Java 语言实现"真泛型"为例,首先,对 泛型类型(泛型类、泛型接口) 、 泛型方法 的名字使用特别的编码,例如将 Factory<T> 类生成为一个名为 “Factory@@T” 的类,这种特别的编码后的名字将被编译器识别,作为判断是否为泛型的依据。方法中使用占位符 T 的地方可以临时生成为 Object ,并带上特别的 Annotation 让 Java 编译器能得知这个是占位符。然后,如果编译时发现有对 Factory<String> 的使用,则将 “Factory@@T” 的所有逻辑复制一份,新建 “Factory@String@” 类,将原本的占位符 T 替换为 String 。然后在编译 new Factory<String>() 时生成 new Factory@String@() 即可。
| 术语 | 中文含义 | 举例 |
|---|---|---|
| Parameterized type | 参数化类型 | List<String> |
| Actual type parameter | 实际类型参数 | String |
| Formal type parameter | 形式类型参数 | E |
以 Factory<String> 与 Factory<Integer> 为例,其生成的代码为:
//替换前的代码 Factory<String>() f1 = new Factory<String>(); Factory<Integer>() f2 = new Factory<Integer>(); //替换后的代码 Factory<String>() f1 = new Factory@String@() Factory<Integer>() f2 = new Factory@Integer@(); 复制代码
- 其中
Factory@String@类中的T已经被替换为 String。 - 其中
Factory@Integer@类中的T已经被替换为 Integer。
因为含有不同的 实际类型参数 的 泛型类型 都被替换为了不同的类,且泛型类型中的类型也都得到了确认。所以我们在程序中可以这么做:
class Factory<T> {
T data;
public static void f(Object arg){
if(arg instanceof T){...}//success
T var = new T();//success
T[] array = new T[10];//success
}
}
复制代码
Java 直接使用 “真泛型” 带来的问题
单从技术来说,Java 是完全 100% 能实现我们所说的 ”真泛型”。想要实现真泛型,有如下两件事Java 必须要处理:
- 修改 JVM 源代码,让 JVM 能正确的的读取和校验泛型信息(之前的Java 是没有泛型这种概念的,所以需要修改)。
- 为了兼容老程序,需为原本不支持泛型的 API 平行添加一套泛型 API(主要是容器类型)。
就拿 ArrayList 来说,也就是必须这么做:
ArrayList<T>
即使以上的事情都做了,Java 也并不能采用这种方案。试想如下情况:
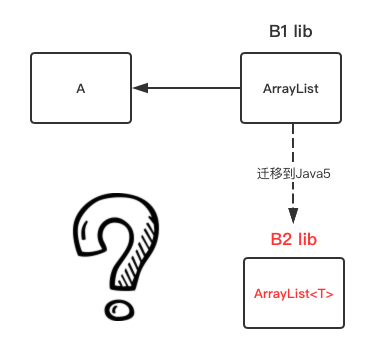
如果我有一个 Java 5 之下 的 A 项目与第三方的 B1 lib,其中有 A 项目中引用了 B1 lib 中的某个 ArrayList ,随着 Java 的升级,B1 lib 的开发者为了使用 Java 新特性--泛型,故将代码迁移到了 Java 5,并重新生成了 B2 lib,那么 A 项目要兼容 B2 lib,那么 A 项目中必须升级到 Java 5 并同时修改代码。
A 项目为什么必须要升级 Java 5?
在 Java 中不支持高版本的 Java 编译生成的 class 文件在低版本的 JRE 上运行,如果尝试这么做,就会得到 UnsupportedClassVersionError 错误。如下图所示:
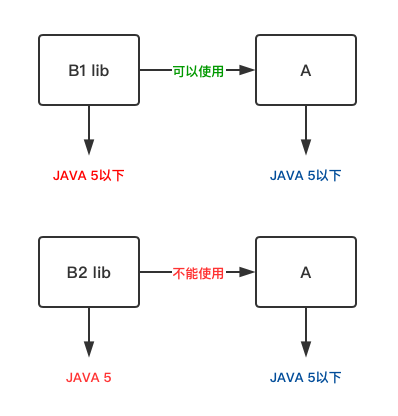
故 A 项目要适配 B2 lib,必要要把 Java 升级到 Java 5。
那现在我们再回过头来想想,Java 版本迭代都从 1.0 到 5.0了,有多少的开源框架,有多少项目,如果为了引入泛型,强行让开发者修改代码。这种情况,各位同学。自行脑补。估计数以万计的开发者拿着刀,在堵 Java 语言架构师的门吧。
逼不得已的类型擦除
在上节中,我们探讨了 Java 不能直接引入“真泛型” 的实际原因。因为“真泛型”的引入,势必会为原本不支持泛型的 API 平行添加一套泛型 API。而新增了API,对于 Java 开发者来说,又必须要做迁移。
那还有什么方案,能让开发者平滑的过渡到 Java 5, 又能使用泛型新特性呢?

有的,有的。Java 如果想摆脱用户新版本的迁移问题。Java 必要要做以下两件事情:
- 不再新增一套泛型 API, 直接把已有的类型原地泛型化 。
- 处理泛化前后类型的兼容。
下面我们分别探讨一下这两件事做的目的及其原因。
做第一件事,是保证了开发者不会因为 Java 的升级,而对以前的老代码进行修改,以 ArrayList 为例, 直接在原有包(java.util)下进行修改 ,也就是这样:
//:point_down:Java老版本
class ArrayList{}
//:point_down:Java5泛型版本
class ArrayList<T>{}
复制代码
做第二件事的目的,还是以我们之前的例子进行分析,在 A 项目中,A 项目引用了 B1 lib 中的 ArrayList(用 list 变量记录),那么假设 A 项目升级到 Java 5 后,还是引用的 B1 lib,那么必然会出现如下这种情况:
下述代码中,A 项目将泛化后 ArrayList<T> 的传递给了 B1 lib 中的 ArrayList 。
ArrayList list = new ArrayList<String>(); 复制代码
ArrayList<T>
这种情况的出现,会导致一个问题。就是 b1 项目中的 ArrayList 是不知道 A 项目中的 Arraylist 已经泛型化了的,那么如何保证 泛型化后 的 ArrayList( 也就是ArrayList<T> )与 老版本 的 ArrayList 等价呢?
如果按照我们之前讲解的 “真泛型” 思路来处理 Java 的泛型, 那么 new ArrayList<String>() 实际会被替换为 new ArrayList@String@() ,那么实际运行代码是这样:
ArrayList list = new Factory@String@() 复制代码
从代码逻辑上来看,根本就跑不通。因为 ArrayList 与 ArrayList@String@ 根本就不是同一类, 那怎么办呢?
最为直接的解决方案就是,不再为参数化类型创造新类了,同时在编译期间将 泛型类型 中的 类型参数 全部替换 Object (因为不创建新类了,那么在泛型类中的 T 对应的类型,只能用 Object 替换)。
在 Java 的泛型实际实现中,会根据泛型类型中的类型参数有无边界,来选择是否替换为边界或 Object。
举个例子:

在上述代码中,声明了一个泛型类型 Node<T> ,在编译器替换后,实际为 Node。也就是这样:
//编译器的代码 Node node = new Node<String>(); //编译后的代码 Node node = new Node(); 复制代码
通过编译器的”魔法“,Java 就解决了处理泛型兼容老版本的问题。
总结
阅读到这里,我相信大家已经明白了 Java 中的泛型为什么要擦除类型信息了。虽然 Java 的 "伪泛型“ 一直被其他编程语言所歧视,但不管怎样,兼容老版本这种行为,也是一件值得尊敬以及认可的一件事。
不管 Java 做了什么,总是功大于过的。这里推荐一个视频给大家。相信看了这个视频之后,大家会知道 Java 对于整个世界的重要性。
- 如果Java在全世界突然被禁用会怎样
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

