Spring之AntPathMatcher
AntPathMatcher是什么?主要用来解决什么问题? 背景:在做uri匹配规则发现这个类,根据源码对该类进行分析,它主要用来做类URLs字符串匹配; 复制代码
效果
可以做URLs匹配,规则如下
- ?匹配一个字符
- *匹配0个或多个字符
- **匹配0个或多个目录
用例如下
/ar/api/x 是否匹配 /ar/api/*x :true /ar/api/ax 是否匹配 /ar/api/*x :true /ar/api/abx 是否匹配 /ar/api/*x :true /ar/abc/x 是否匹配 /ar/api/*x :false /ar/api/x 是否匹配 /ar/api/?x :false /ar/api/ax 是否匹配 /ar/api/?x :true /ar/api/abx 是否匹配 /ar/api/?x :false /ar/api/x 是否匹配 /**/api/x :true /ar/data/api/x 是否匹配 /**/api/x :true /ar/api/x 是否匹配 /**/api/x :true /ar/api/x 是否匹配 /**/*.html :true /ar/data/api/x 是否匹配 /**/*.html :true /ar/api/x 是否匹配 /**/*.html :true 复制代码
核心
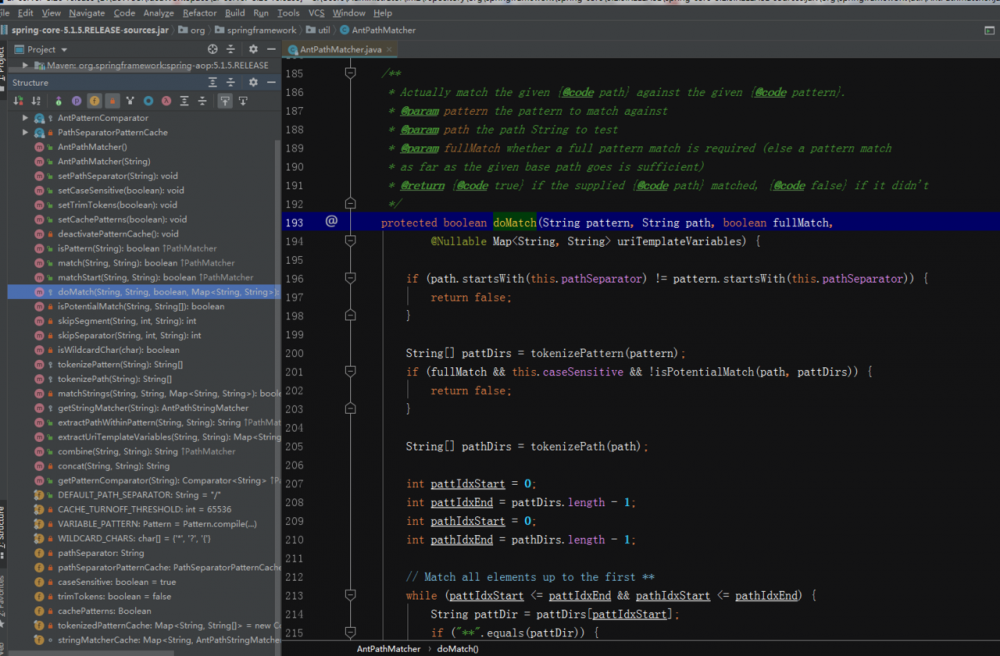
caseSensitive:是否区分大小写; trimTokens:是否去除前后空格; cachePatterns:是否缓存匹配规则; 复制代码
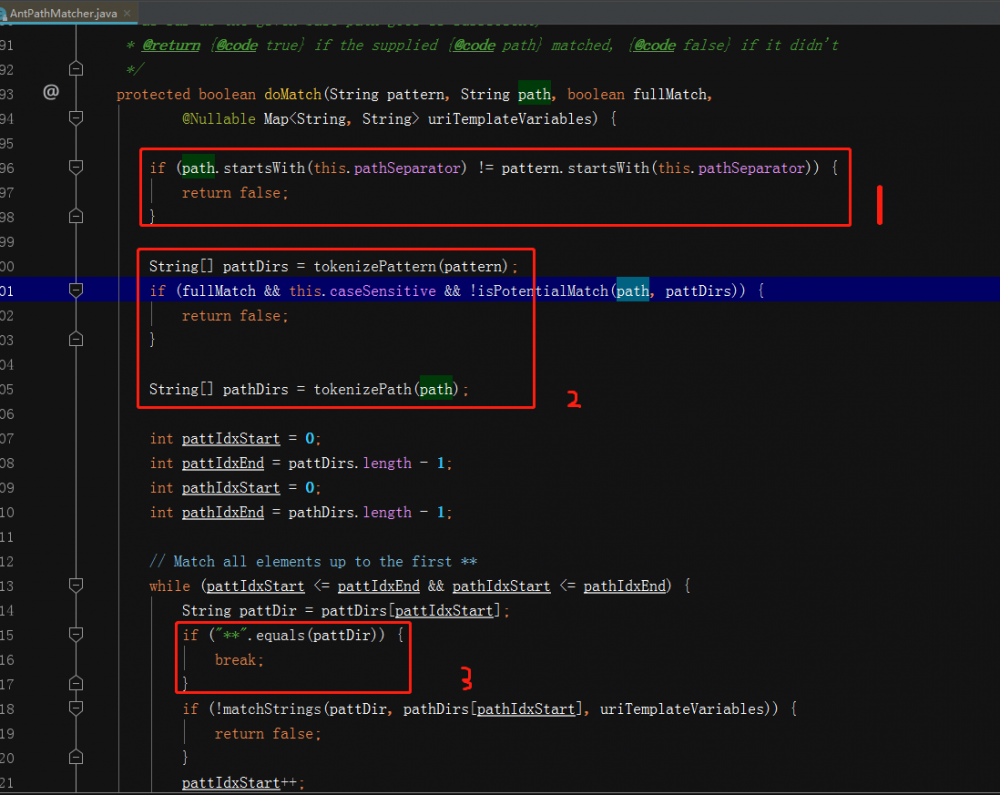
1 .首先判断pattern和path的首字符是否同时为设置的分隔符,结果不一致则直接返回false,不进行下边的操作; 2 . 分别对pattern和path进行分词,形成各自的字符串数组,其中分词的主要代码如下: 复制代码
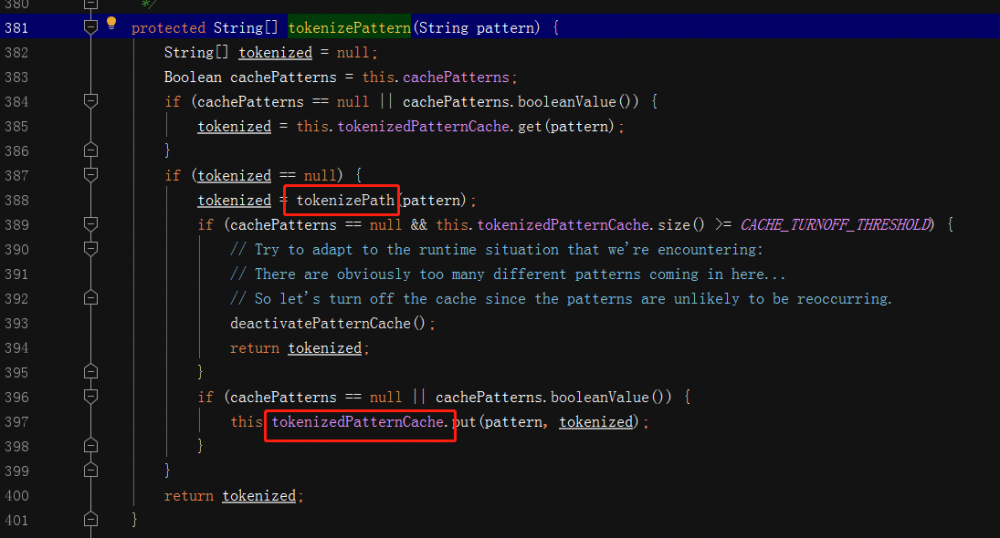
对pattern和path进行分词的逻辑是一样的,只是pattern做下缓存的处理; key为pattern,value为分次之后的字符串数组,每次先到cache获取,没有的话则计算,然后放入到cache里边,这样在做频繁的url mapping的时候,由于规则是有限的,可以很大程度减少计算; 当超过缓存的最大值,会进行缓存清除; 复制代码
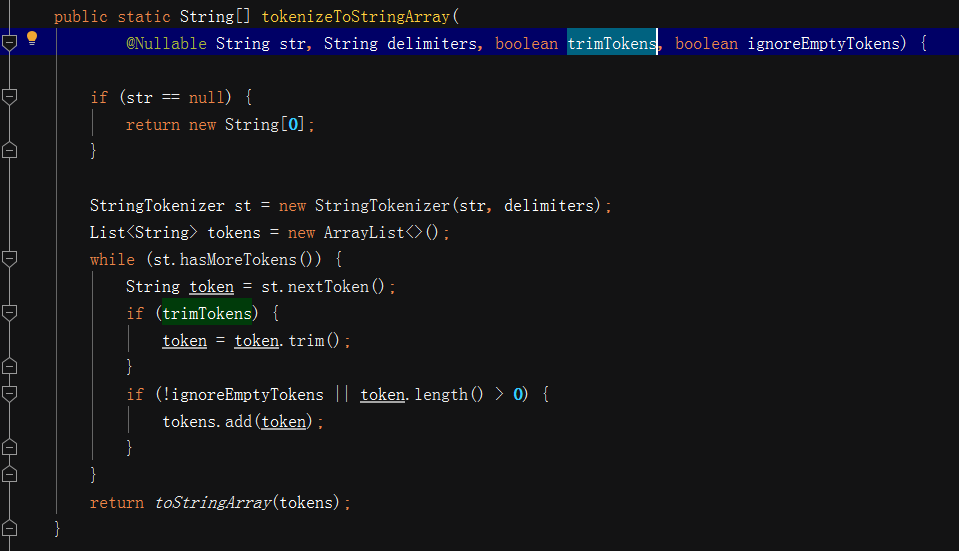
注:str代表要进行分词的字符串,delimiters是进行分词的分隔符,trimTokens表示是否对每一个分词进行首尾去空字符串,ignoreEmptyTokens代表分割之后是否保留空字符串(该处是true) 复制代码
下边接着看doMatch的中间部分代码(也就是说当break或者运行完毕while循环的时候,在退出之前会接着执行下边的代码)
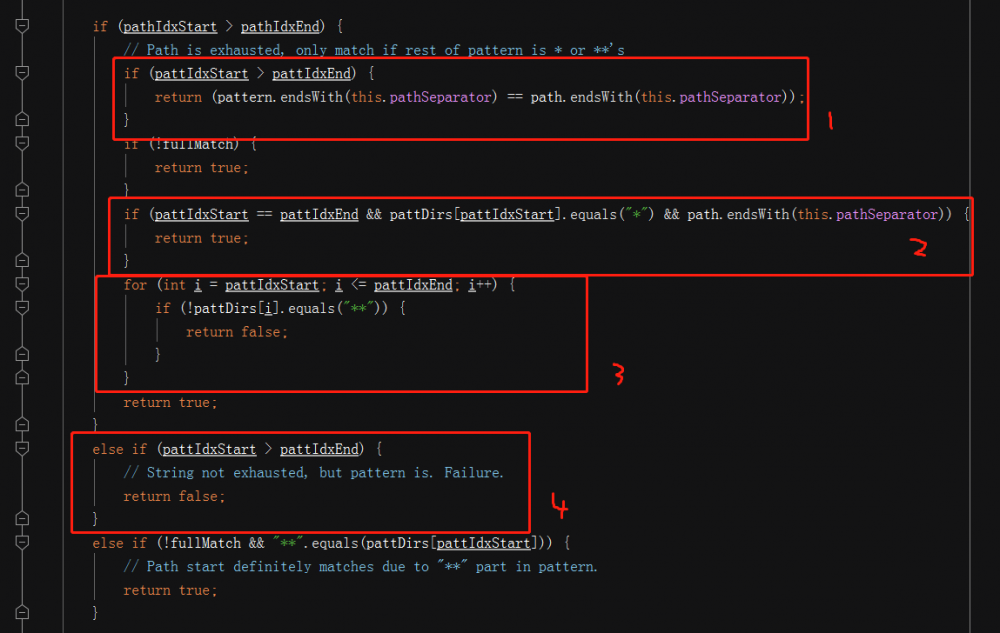
1 .如果path分词数组正常执行完毕,则pathIdxStart是会比pathIdxEnd大1的,这个时候,如果pattern的字符串数组也正常耗尽,则来判断pattern和path的最后一个字符是否同步,按结果返回; 2 .如果上边的循环只执行了一次,则这时候pattIdxStart则和pattIdxEnd相等,同时pattern的最后一个字符是*且path最后是一个分隔符,则直接返回true; 3 . 如果pattern的最后一个字符串是**则path不需要判断直接返回true; 4.这一步代表,pattern已经耗尽但是path还没耗尽,这时候肯定不匹配,直接返回false 复制代码
接下来接着看,紧接着上边第二幅黑色背景图,如果第一次因为弹出来,看下边如何处理:
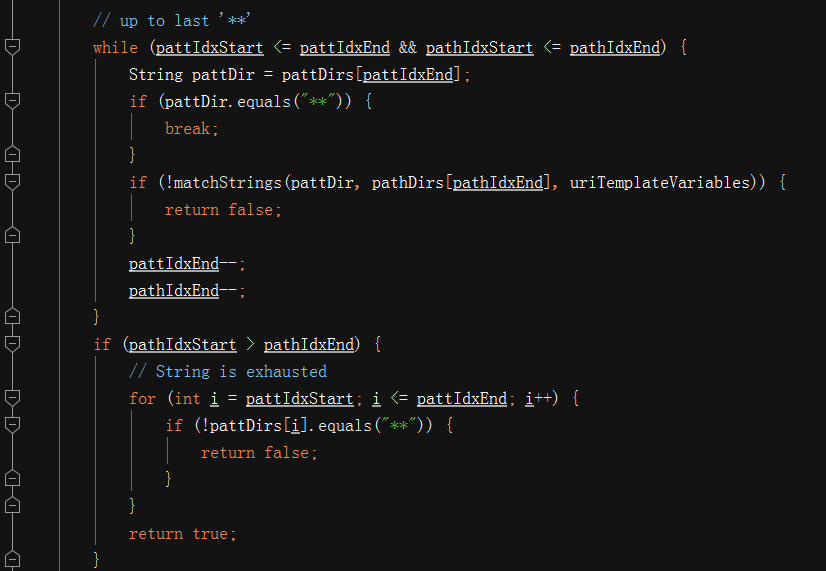
这个时候,开始从后往前遍历,如果再次弹出来不是因为遇到了**,是正常遍历完成,这个时候,pathIdxStart是大于pathIdxEnd,这个时候字符串已经耗尽,如果pattern还没有耗尽,并且最后并不是**,则直接返回false; 复制代码
如果中间再次出现,并且path并没有耗尽,则进行下边的步骤
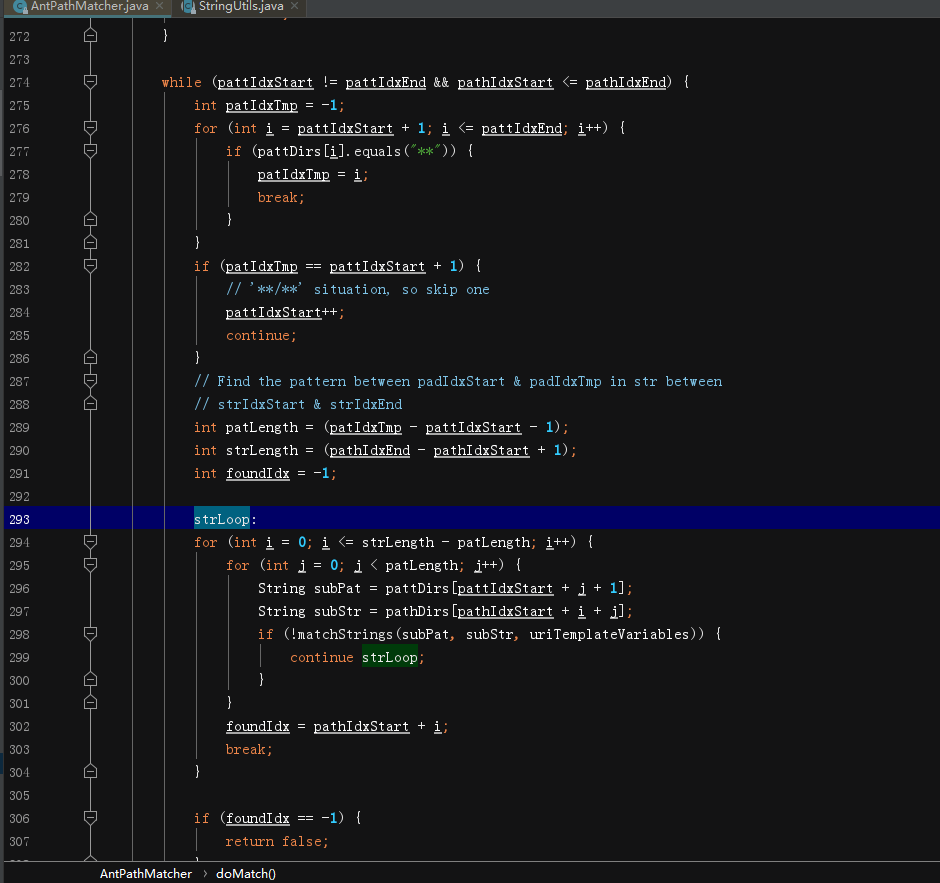
这一部分代码主要用来循环处理中间再次**的情况,直到完全处理完成,这里边用到了Java的标签语法:strLoop,符合条件则跳转到strLoop(类似goto); 复制代码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

