人人都想学架构(五)
在 《人人都想学架构(四)》 讲了分布式理论的CAP原理,接下去描述第八节,讲的是存储高可用性。它的本质就是冗余,复杂性主要是应对复制带来的延迟和一致性问题,在学习相关中间件的时候,考虑几个问题:
-
数据如何复制
-
各个节点的职责是什么
-
如何应对复制延迟
-
如何应对复制中断
数据集中集群
什么是集中集群呢,它们称为集群的原因是有一大堆机器组合在一块,而集中表示每一个实例的数据都是完整的,其他机器数据只是它的复制结果。比如MySQL就是一个典型的集中式存储系统,集中集群会遇到单机存储空间的限制(比如我们),虽然可以采取分库这样的扩展,但分完后的实例和其他实例本质上还是分离的,并不存在关系。
MySQL集群可以分为主备和主从,备代表备份,不用做线上服务,而从可以提供查询服务,但本质上差不多,都是主库和备库(从库)之间同步数据,所以考虑的时候可以认为是一致的。
既然是复制原理,就会遇到同步延迟、同步中断、主库单点的问题,如何解决呢?
首先要避免延迟,因为一旦有延迟就会影响应用,而且主从倒挂的时候还会出现数据不一致的问题。
其次考虑从库之间的负载均衡问题,这个相对好解决,比如发现从库不能复制数据了、延迟了,就可以摘除,比如DNS就可以,或者SLB(具体还没试验过)。
最复杂的是主从倒挂的问题,比如主库出现故障,如何快速将一台从库提为主库。面临的核心问题:
-
如何传递状态,就是主从之间如何知道对方是否存活。
-
状态如何检测,比如MySQL进程不存在了、响应很慢,这个很有讲究,将来可参考一些通用的思路。
一旦有状态检测,就要做出决策:
-
什么情况下主从倒挂?
可以自定义,比如主库响应非常慢,而且持续一段时间了,才进行倒挂。
-
倒挂是需要人工干预还是自动
-
数据是否有冲突,这个可能是最麻烦的。
如果是主备,检测相对简单,如果是主从,可能就要通过第三方仲裁了,ZK可能就是最常用的解决方案。
对于数据库来说,自动化解决了主从倒挂的问题是最重要的,相比云数据库,自建数据库在这方面要花更多的心思,希望将来实践下。
数据分散集群
这才是真正的集群,就是集群中每台机器都存储一部分数据,可以称为分片,然后每份数据又有复制集做冗余,复杂点在于如何将数据分配到不同的机器上,主要考虑以下几个问题:
-
均衡性(数据分区要基本平衡)
-
容错性,原来分配给故障服务器的数据分区分配给其他服务器
-
可伸缩性,容量不够扩充新的服务器后,能够自动将部分数据分区迁移到新的服务器
对于分散集群来说,核心也会用到ZK这样的软件(分布式一致性算法),在学习ELK、MongoDB的时候,需要深入思考它们如何做到以上几点的,这才是真正的价值。
分布式一致性算法
这是大学问,自己也搞不懂,简单记录下。分布式一致性算法是为了保证一份数据在多个节点的一致性,是为了满足CP要求。
-
Paxos,复杂,难于理解,缺失细节,在工程上只能以它为基础,比如Google的chubby就是一个Paxos-like算法。
-
Raft:
是为了工程实践而设计的,强调可理解性,主要包含三个子问题(leader选举,日志复制,安全保证)
-
ZAB:
是ZK系统采用的分布式一致性算法,和raft类似。
分布式事务算法
某些业务场景需要事务来保证数据一致性,对于数据集群来说,数据分布在不同的节点上,这些节点只能通过消息进行通信,因此分布式事务实现起来只能依赖消息通知,但消息本身不可靠,给分布式事务带来了复杂度,一般需要一个“协调者”来处理事务。
它的核心目的是为了保证分散在多个节点上的数据统一提交或回滚。
https://juejin.im/post/5cab6ff95188251af951c82b 这篇文章写的很好,简单列举图加深自己的理解。
1:2PC
(1)Prepare:提交事务请求
参与执行事务操作(例如更新一个关系型数据库表中的记录),并将 Undo(回滚)和 Redo(重做)信息记录事务日志中。
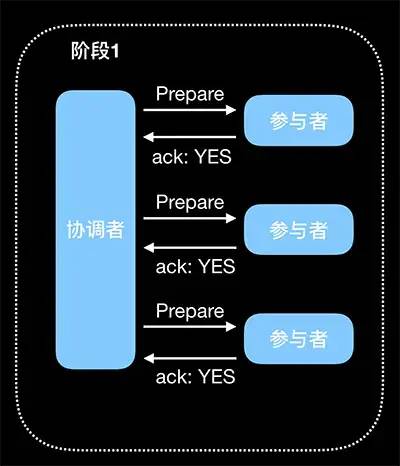
(2)Commit:执行事务提交
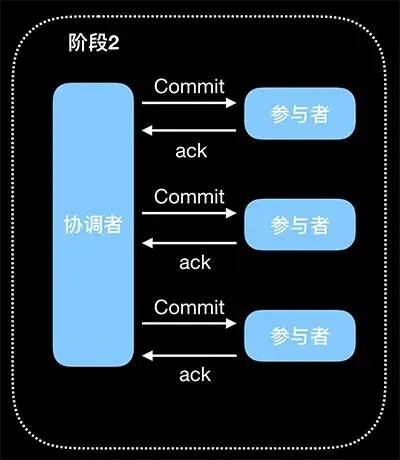
正常提交事务:
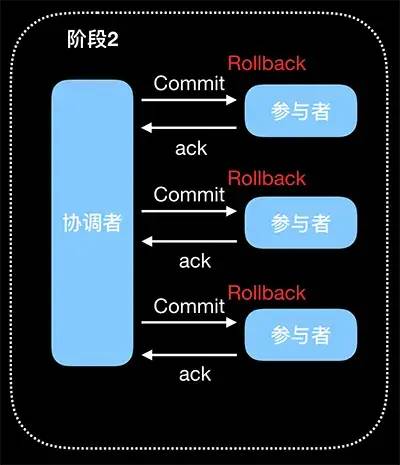
中断事务:
2PC 的问题:
-
同步阻塞
-
协调者有单点问题
-
数据不一致,比如某个参与者没有收到Commit/Rollback请求(而其他参与者收到了),就会一直阻塞,从而导致数据不一致。
2:3PC
3PC是在2PC的基础上,为了解决2PC的某些缺点而设计的,3PC分为三个阶段:CanCommit,PreCommit 和 doCommit。
(1)CanCommit
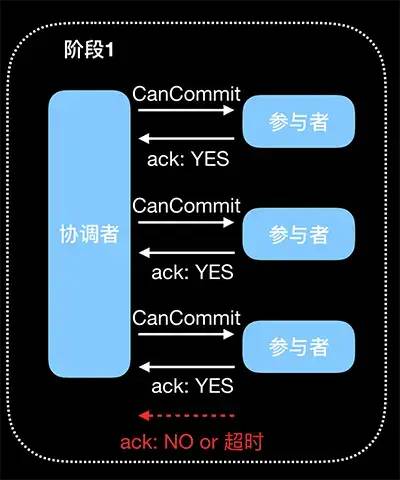
注意参与者没有执行事务。
(2)PreCommit
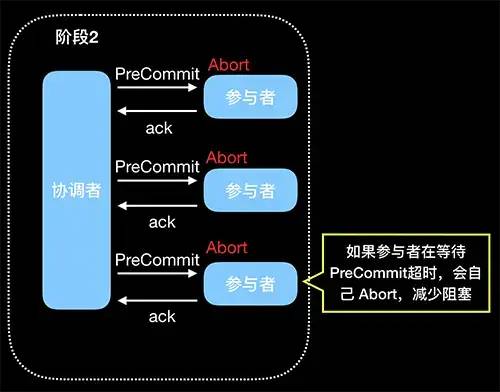
(3)doCommit
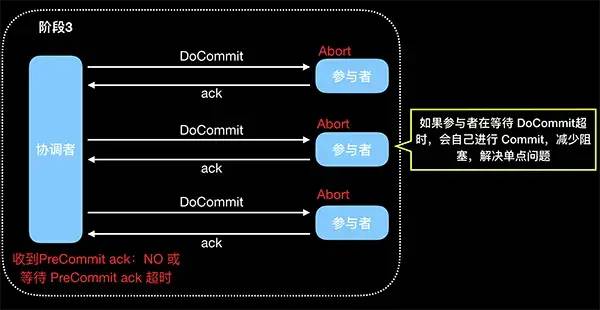
3PC 的改进和缺点:
-
降低了阻塞
-
解决单点故障问题
-
数据不一致问题仍然是存在的,比如第三阶段协调者发出了 abort 请求,然后有些参与者没有收到 abort,那么就会自动 commit,造成数据不一致
对比MySQL和MongoDB,理解他们的本质,可能就理解了分布式算法的精髓。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

