Stream—一个早产的婴儿
当你会关注这篇文章时,那么意味着你对 Stream 或多或少有些了解,甚至你在许多业务中有所应用。正如你所知,业界对 Stream 、 lambda 褒贬不一,有人认为它是银弹,也有人认为其降低了代码的可读性。事实上,很多东西我们应该辩证的去看待,一方面 Stream 相关的api的确提供了诸多的便利,如果你愿意花时间去理解和使用的话;然而另一方面,它像一个早产的婴儿,当你去阅读它源码时,你会觉得差异,像是一个临时拼凑而成的模块。
在前面的 Java函数式编程的前生今世 篇章中,我们已经了解了 lambda 表达式的原理,以及常见的四大函数式接口。
我们可以先看一个 Stream 的demo:
Stream.of(1, 2, 3)
.filter(num -> num > 2)
.forEach(System.out::println);
语义比较清晰,从一个 array 中获取数值大于2的,最后给打印出来。
源头
在调用 Stream 的 API 之前,我们都需要先创建一个 Steam 流, Stream 流的创建方式有很多种,比如上述 demo 中的 Stream.of ,其使用的是 StreamSupport 这个类提供的方法;还有在集合类中在 1.8 之后预留了 stream 的获取方法等。
//StreamSupport
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
//Collection
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
这里可以稍微留意一下,有一个 parallel 参数,为我们后文去执行作准备。
不知道看到这里你是否也会有同样的疑惑:为什么 Stream 明明是一个接口,要在里面做 static 的实现?
这与以往的 JDK 代码有较大的出入,一般静态功能都会提供一个 xxxs 来处理,比如 Path 与 Paths , File 与 Files 等。而且更令人诧异的是,在 1.8 之后,这种静态方法在 List 、 Collection 中比比皆是。
坦率地讲,这并非一种好的设计,严格来讲,接口只是声明,不应该承载具体实现,虽然从语法而言提供了这种能力。而像也像是为过去设计的妥协。
我们回到 Stream ,前面两种方法都提到了,会返回一个 Stream 流。
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
最开始当我看到 StreamSupport 这个类时,我第一感觉是类似于 LockSupport ,用于「辅助」,而非「创建」。然而事与愿违的是,它更多的做的是「创建」。其实熟悉 JDK 源码的人应该比较清楚,这种「创建」的事情,一般是在 xxs (比如 Paths )这种类中处理。
当然,这个仅是个人主观的臆断,也许他们内部并没有这种「约定俗成」的东西。
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
ReferencePipeline.Head 是所有流处理的源头, ReferencePipeline 继承自 AbstractPipeline 。 Spliterator 用于对数据迭代并加工,其中有一个较为关键的方法 forEachRemaining ,我们后面也会提到。
//创建头节点
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
头节点,包括后面流水线的节点都继承自这个 AbstractPipeline ,你会发现这里的结构是一个双向链表,通过 previousStage 和 nextStage 来分别用于指向前一个和后一个节点。
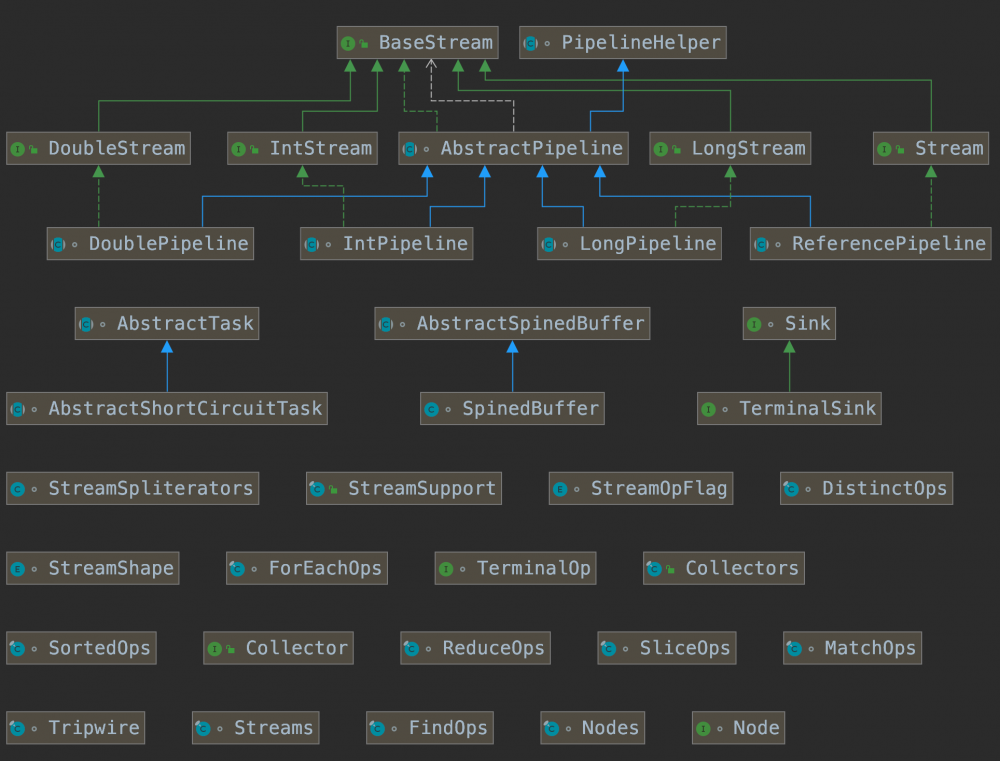
流水线
在 Stream 体系中,操作被划分成了两种,一种流操作,他所做的事情是对数据的加工,而在流操作内部,又被划分成了两种,一种是有状态的流( StatefulOp ),一种是无状态的流( StatelessOp ),二者的区别在于, 数据是否会随着操作中的变化而变化 ,举个例子, filter 是无状态的,你要过滤什么就是什么,而 sort 是有状态的,如果你在数据层增加了数据或修改了数据,那么最后的结果有可能不同;另外一种是终止操作( TerminalOp ),他意味着开始对流进行执行操作,如果代码中仅有流操作,那么这个流是不会开始执行的。
A stateful lambda expression is one whose result depends on any state that might change during the execution of a pipeline. On the other hand, a stateless lambda expression is one whose result does not depend on any state that might change during the execution of a pipeline.
在 Stream 中,流操作有很多种,比如常见的 filter 、 map 、 mapToInt 等,都会在方法中返回一个新建的流操作对象,而这个对象也继承了 AbstractPipeline 。
//filter操作
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
//这里的this就是前面提到的流的源头
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
//StatelessOp类
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
/**
* Construct a new Stream by appending a stateless intermediate
* operation to an existing stream.
*
* @param upstream The upstream pipeline stage
* @param inputShape The stream shape for the upstream pipeline stage
* @param opFlags Operation flags for the new stage
*/
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
@Override
final boolean opIsStateful() {
return false;
}
}
//StatelessOp最终也继承自AbstractPipeline
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
StatelessOp 对象在创建时,会注入一个参数 this ,而这个 this 即我们前面提到的流的源头。在 AbstractPipeline 的另外一个构造方法中,完成了双向链表的指定以及深度的自增。
这里有一个方法 opIsStateful ,用于判定前面提到的是否是有状态的。
终止符
所有的流操作的执行,都取决于最终的终止操作( TerminalOp ),如果流中没有这个操作,那么前面提到的操作流都无法执行。
而所有的终止操作都实现了 TerminalOp 这个接口,包括向我们常见的 foreach 、 reduce 、 find 等。我们还是以前面例子中提到的 foreach 来演示我们的原理。
//Stream
void forEach(Consumer<? super T> action);
//ReferencePipeline中的forEach实现
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
在 Stream 的 forEach 方法中,有一个参数 Consumer ,是一个函数式接口,我们在前面的文章中有所涉及,有兴趣的可以自行查阅其原理。
//ForEachOps
static final class OfRef<T> extends ForEachOp<T> {
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
consumer.accept(t);
}
}
在 ForEachOps 有一个 ForEachOp 类用于生成操作类,同时, ForEachOp 还实现了 TerminalSink ,后面会提到。不过,还有另外一个 OfRef 来继承自 ForEachOp 作为调用入口去使用,不过至今我还没明白这里为何单独需要在 ForEachOp 下面再嵌套一层,有了解的可以告知我一下。
//AbstractPipeline
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
//用于判定是并行还是串行
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}
这里会根据最开始的源头注入的 parallel 来判定,在前面也有所提及。这里有一个方法 sourceSpliterator 用于协助我们去获取数据源分割器,其实在前面有所提及,在创建流的时候,就已经有自动创建一个 spliterator ,如果是串行流,那么会直接使用源头流的分割器,如果是并行流,而且其中有有状态的操作,那么会使用这个状态流实现的方法去返回。
//AbstractPipeline
@SuppressWarnings("unchecked")
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// Get the source spliterator of the pipeline
Spliterator<?> spliterator = null;
//最开始的源头流的分割器
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
//如果是并行流并且有有状态的操作流
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
spliterator = p.opEvaluateParallelLazy(u, spliterator);
// Inject or clear SIZED on the source pipeline stage
// based on the stage's spliterator
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED)
? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
在我们拿到分割器之后,我们会调用 terminalOp.evaluateSequential 方法去处理。需要说明的是,并行流我暂时没有深入研究,所以暂时不在此章的讨论范畴,后续有机会我会补充上去。
//ForEachOps
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
//这里的helper也就是前面在AbstractPipeline中注入的this
return helper.wrapAndCopyInto(this, spliterator).get();
}
//AbstractPipeline
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//遍历流链表,逐一执行前面的opWrapSink方法
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
在操作流中,一般会返回一个 StatelessOp 类,这里前面有所提及,中间有一个 opWrapSink 就是现在我们在调用的方法,而在这个方法中,又会继续返回一个类 Sink.ChainedReference ,这个类会在 downstream 记录我们传入的 sink ,也就是我们目前正在操作的 ForEachOp 。
//前面的filter
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
//继续返回一个类,记录terminalOp
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
sink 也是一个简单的单项链表,他的顺序与 Stream 相反,通过 downStream 一层层向前指定。在获取到最前面一层包装好的 sink 之后,我们继续看 copyInto 方法。
//AbstractPipeline
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
//这里的wrappedSink是最前面的流操作,也就是我们生成流之后的第一个操作,在此案例中也就是filter
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//调用分割器的遍历方法
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
//Spliterators
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
//将数据源遍历,执行sink中的accept方法
do { action.accept((T)a[i]); } while (++i < hi);
}
}
//filter accept方法被遍历执行
@Override
public void accept(P_OUT u) {
//这里的predicate也就是我们最开始通过lambda表达式创建的action
if (predicate.test(u))
//如果检测通过,那么执行downstream也就是ForEach.OfRef类的accept方法
downstream.accept(u);
}
//OfRef accept被调用
@Override
public void accept(T t) {
//这里的consumer也就是我们stream.foreach调用时注入的System.out::println
consumer.accept(t);
}
Spliterators 通过遍历所有数据源,执行 filter 的 accept 方法,如果校验通过,那么会执行 downstream 的 accept 方法,而这个 downstream 我们已经提及很多次,也就是我们这个例子中的 foreach , foreach 的 accept 被调用时,此时又有一个 consumer ,这里的 consumer 也就是我们最开始例子中的 System.out::println 。至此,整体流程就执行完毕了。
回到我们的标题,为什么说 stream 是一个“早产的婴儿”呢?在对 stream 整体源码有所大体阅读之后,你会发现很多类的命名、类的设计风格、以及结构的整理设计能力与之前的模块有较大的差异,有些命名明明可以更为规范,有些设计明明可以设计的更为优雅,甚至于,许多地方的设计还不够简练,这里就不一一举例了。当然,这一切都只是我个人的想法,也有可能是我的水平还没到达另外一个层次吧,或许几年之后再拜读时又会有不一样的感悟。
本文由nine 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Apr 23, 2020 at 11:00 pm
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

