看完就懂的 Spring IoC 实现过程

古时的风筝第 67 篇原创文章
Spring IoC,全称 Inversion of Control - 控制反转,还有一种叫法叫做 DI( Dependency Injection)-依赖注入。也可以说控制反转是最终目的,依赖注入是实现这个目的的具体方法。
什么叫控制反转
为什么叫做控制反转呢。
在传统的模式下,我想要使用另外一个非静态对象的时候会怎么做呢,答案就是 new 一个实例出来。
举个例子,假设有一个 Logger 类,用来输出日志的。定义如下:
public class Logger {
public void log(String text){
System.out.println("log:" + text);
}
}
那现在我要调用这个 log 方法,会怎么做呢。
Logger logger = new Logger();
logger.log("日志内容");
对不对,以上就是一个传统的调用模式。何时 new 这个对象实例是由调用方来控制,或者说由我们开发者自己控制,什么时候用就什么时候 new 一个出来。
而当我们用了 Spring IoC 之后,事情就变得不一样了。简单来看,结果就是开发者不需要关心 new 对象的操作了。还是那个 Logger 类,我们在引入 Spring IoC 之后会如何使用它呢?
public class UserController {
@Autowired
private Logger logger;
public void log(){
logger.log("please write a log");
}
}
开发者不创建对象,但是要保证对象被正常使用,不可能没有 new 这个动作,这说不通。既然如此,肯定是谁帮我们做了这个操作,那就是 Spring 框架做了,准确的说是 Spring IoC Container 帮我们做了。这样一来,控制权由开发者转变成了第三方框架,这就叫做控制反转。
什么叫依赖注入
依赖注入的主谓宾补充完整,就是将调用者所依赖的类实例对象注入到调用者类。拿前面的那个例子来说,UserController 类就是调用者,它想要调用 Logger 实例化对象出来的 log 方法,logger 作为一个实例化(也就是 new 出来的)对象,就是 UserController 的依赖对象,我们在代码中没有主动使用 new 关键字,那是因为 Spring IoC Container 帮我们做了,这个对于开发者来说透明的操作就叫做注入。
注入的方式有三种:构造方法的注入、setter 的注入和注解注入,前两种方式基本上现在很少有人用了,开发中更多的是采用注解方式,尤其是 Spring Boot 越来越普遍的今天。我们在使用 Spring 框架开发时,一般都用 @Autowired ,当然有时也可以用 @Resource
@Autowired
private IUserService userService;
@Autowired
private Logger logger;
Spring IoC Container
前面说了注入的动作其实是 Spring IoC Container 帮我们做的,那么 Spring IoC Container 究竟是什么呢?

本次要讨论的就是上图中的 Core Container 部分,包括 Beans、Core、Context、SpEL 四个部分。
Container 负责实例化,配置和组装Bean,并将其注入到依赖调用者类中。Container 是管理 Spring 项目中 Bean 整个生命周期的管理者,包括 Bean 的创建、注册、存储、获取、销毁等等。
先从一个基础款的例子说起。前面例子中的 @Bean 是用注解的方式实现的,这个稍后再说。既然是基础款,那就逃不掉 xml 的,虽然现在都用 Spring Boot 了,但通过原始的 xml 方式能更加清晰的观察依赖注入的过程,要知道,最早还没有 Spring Boot 的时候,xml 可以说是 Spring 项目的纽带,配置信息都大多数都来自 xml 配置文件。
首先添加一个 xml 格式的 bean 声明文件,假设名称为 application.xml,如果你之前用过 Spring MVC ,那大多数情况下对这种定义会非常熟悉。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:bean="http://www.springframework.org/schema/c"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="logger" class="org.kite.spring.bean.Logger" />
</beans>
通过 <bean> 元素来声明一个 Bean 对象,并指定 id 和 class,这是 xml 方式声明 bean 对象的标准方式,如果你自从接触 Java 就用 Spring Boot 了,那其实这种方式还是有必要了解一下的。
之后通过通过一个控制台程序来测试一下,调用 Logger 类的 log 方法。
public class IocTest {
public static void main(String[] args){
ApplicationContext ac = new ClassPathXmlApplicationContext("application.xml");
Logger logger = (Logger) ac.getBean("logger");
logger.log("hello log");
}
}
ApplicationContext 是实现容器的接口类, 其中 ClassPathXmlApplicationContext 就是一个 Container 的具体实现,类似的还有 FileSystemXmlApplicationContext ,这两个是都是解析 xml 格式配置的容器。我们来看一下 ClassPathXmlApplicationContext 的继承关系图。
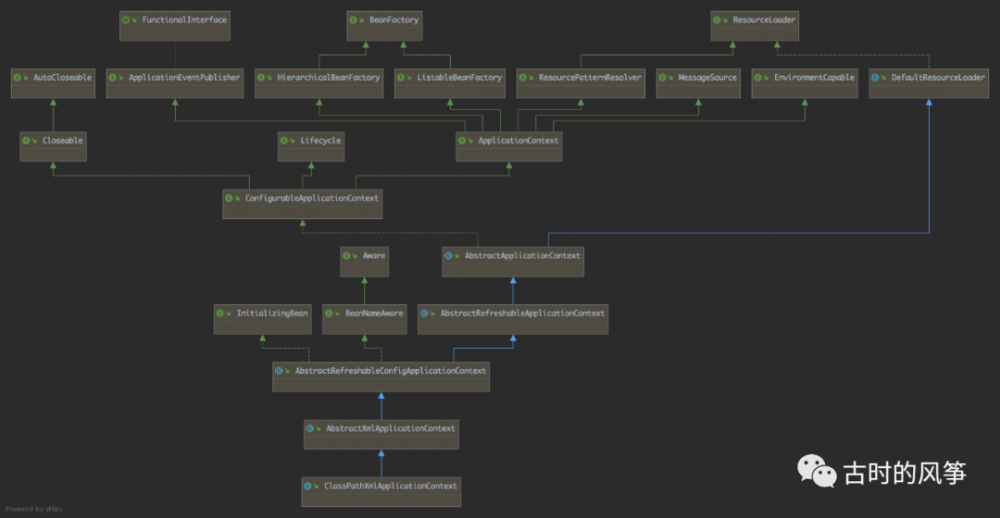
有没有看起来很复杂的意思,光是到 ApplicationContext 这一层就经过了好几层。
这是我们在控制台中主动调用 ClassPathXmlApplicationContext ,一般在我们的项目中是不需要关心 ApplicationContext 的,比如我们使用的 Spring Boot 的项目,只需要下面几行就可以了。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
但是,这几行并不代表 Spring Boot 就不做依赖注入了,同样的,内部也会实现 ApplicationContext ,具体的实现叫做 AnnotationConfigServletWebServerApplicationContext ,下面看一下这个实现类的继承关系图,那更是复杂的很,先不用在乎细节,了解一下就可以了。
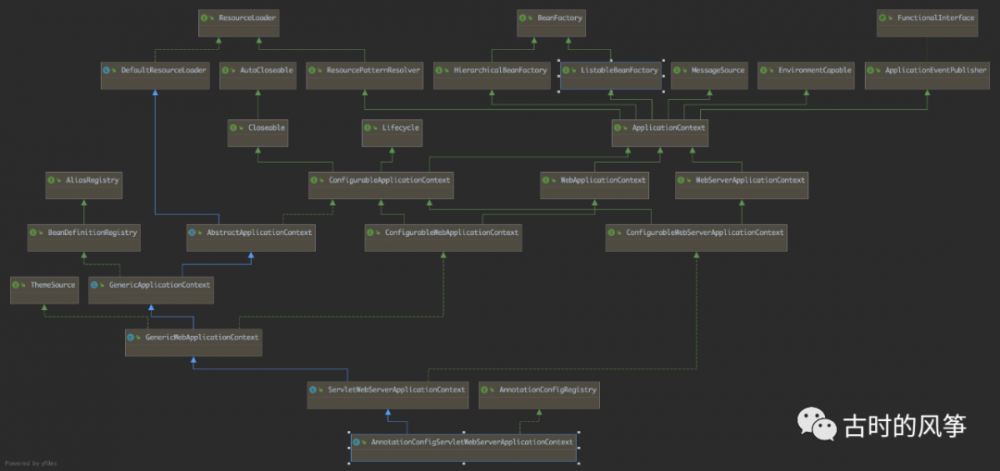
注入过程分析
继续把上面那段基础款代码拿过来,我们的分析就从它开始。
public class IocTest {
public static void main(String[] args){
ApplicationContext ac = new ClassPathXmlApplicationContext("application.xml");
Logger logger = (Logger) ac.getBean("logger");
logger.log("hello log");
}
}
注入过程有好多文章都进行过源码分析,这里就不重点介绍源码了。
简单介绍一下,我们如果只分析 ClassPathXmlApplicationContext 这种简单的容器的话,其实整个注入过程的源码很容易读,不得不说,Spring 的源码写的非常整洁。我们从 ClassPathXmlApplicationContext 的构造函数进去,一步步找到 refresh() 方法,然后顺着读下去就能理解 Spring IoC 最基础的过程。以下代码是 refresh 方法的核心方法:
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {}
destroyBeans();
cancelRefresh(ex);
throw ex;
}
finally {
resetCommonCaches();
}
}
}
注释都写的非常清楚,其中核心注入过程其实就在这一行:
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
我把这个核心部分的逻辑调用画了一个泳道图,这个图只列了核心方法,但是已经能够清楚的表示这个过程了。( 获取矢量格式的可以在公众号回复「矢量图」获取 )
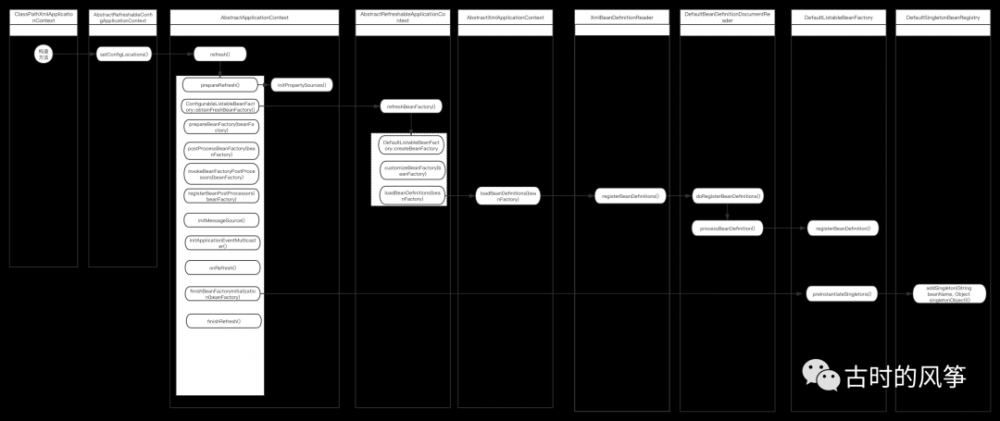
题外话:关于源码阅读大部分人都不太能读进去源码,包括我自己,别说这种特别庞大的开源框架,就算是自己新接手的项目也看不进去多少。读源码最关键的就是细节,这儿说的细节不是让你抠细节,恰恰相反,千万不能太抠细节了,谁也不能把一个框架的所有源码一行不落的全摸透,找关键的逻辑关系就可以了,不然的话,很有可能你就被一个细节搞到头疼、懊恼,然后就放弃阅读了。
有的同学一看图或者源码会发现,怎么涉及到这么多的类啊,这调用链可真够长的。没关系,你就把它们当做一个整体就可以了(理解成发生在一个类中的调用),通过前面的类关系图就看出来了,继承关系很复杂,各种继承、实现,所以到最后调用链变得很繁杂。
简单概括
那么简单来概括一下注入的核心其实就是解析 xml 文件的内容,找到
而至于使用注解方式的 bean,比如使用 @Bean 、 @Service 、 @Component 等注解的,只是解析这一步不一样而已,剩下的操作基本都一致。
所以说,我们只要把这里面的几个核心问题搞清楚就可以了。
BeanFactory 和 ApplicationContext 的关系
上面的那行核心代码,最后返回的是一个 ConfigurableListableBeanFactory 对象,而且后面多个方法都用这个返回的 beanFactory 做为参数。
BeanFactory 是一个接口, ApplicationContext 也是一个接口,而且, BeanFactory 是 ApplicationContext 的父接口,有说 BeanFactory 才是 Spring IoC 的容器。其实早期的时候只有 BeanFactory ,那时候它确实是 Spring IoC 容器,后来由于版本升级扩展更多功能,所以加入了 ApplicationContext 。它们俩最大的区别在于, ApplicationContext 初始化时就实例化所有 Bean,而 BeanFactory 用到时再实例化所用 Bean,所以早期版本的 Spring 默认是采用懒加载的方式,而新版本默认是在初始化时就实例化所有 Bean,所以 Spring 的启动过程不是那么快,这是其中的一个原因。
实例的 bean 保存在哪儿
上面概括里提到保存到一个公共空间,那这个公共空间在哪儿呢?其实是一个 Map,而且是一个 ConcurrentHashMap ,为了保证并发安全。它的声明如下,在 DefaultListableBeanFactory 中。
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256)
其中 beanName 作为 key,也就是例子中的 logger,value 是 BeanDefinition 类型,BeanDefinition 用来描述一个 Bean 的定义,我们在 xml 文件中定义的
向 beanDefinitionMap 中添加元素,叫做 Bean 的注册,只有被注册过的 Bean 才能被使用。
还不只有 beanDefinitionMap
另外,还有一个 Map 叫做 singletonObjects,其声明如下:
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
在 refresh() 过程中,还会将 Bean 存到这里一份,这个存储过程发生在 finishBeanFactoryInitialization(beanFactory) 方法内,它的作用是将非 lazy-init 的 Bean 放到singletonObjects 中。
除了存我们定义的 Bean,还包括几个系统 Bean。
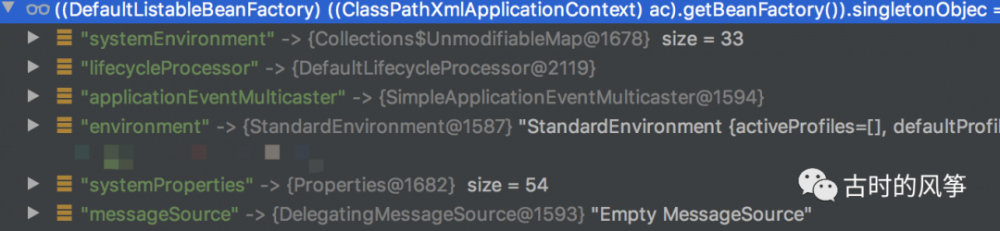
例如我们在代码中这样调用:
ApplicationContext ac = new ClassPathXmlApplicationContext("application.xml");
StandardEnvironment env = (StandardEnvironment) ac.getBean("environment");
使用已注册的 Bean
在这个例子中,我们是通过 ApplicationContext 的 getBean() 方法显示的获取已注册的 Bean。前面说了我们定义的 Bean 除了放到 beanDefinitionMap,还在 singletonObjects 中存了一份,singletonObjects 中的就是一个缓存,当我们调用 getBean 方法的时候,会先到其中去获取。如果没找到(对于那些主动设置 lazy-init 的 Bean 来说),再去 beanDefinitionMap 获取,并且加入到 singletonObjects 中。
获取 Bean 的调用流程图如下( 公众号回复「矢量图」获取高清矢量图 )
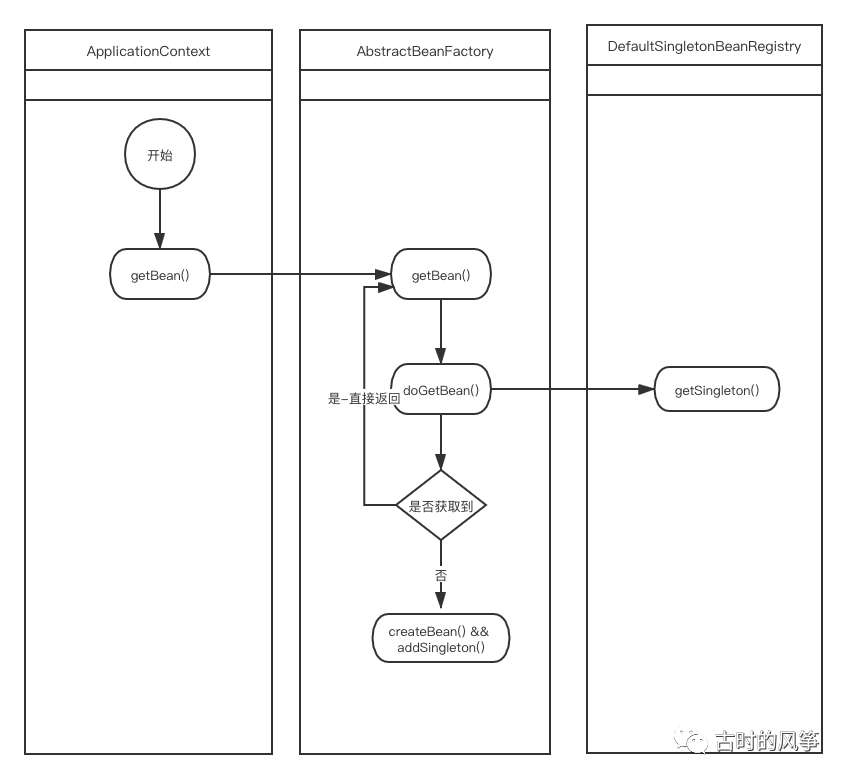
以下是 lazy-init 方式设置的 Bean 的例子。
<bean id="lazyBean" lazy-init="true" class="org.kite.spring.bean.lazyBean" />
如果不设置的话,默认都是在初始化的时候注册。
注解的方式
现在已经很少项目用 xml 这种配置方式了,基本上都是 Spring Boot,就算不用,也是在 Spring MVC 中用注解的方式注册、使用 Bean 了。其实整个过程都是类似的,只不过注册和获取的时候多了注解的参与。Srping 中 BeanFactory 和 ApplicationContext 都是接口,除此之外,还有很多的抽象类,使得我们可以灵活的定制属于自己的注册和调用流程,可以认为注解方式就是其中的一种定制。只要找到时机解析好对应的注解标示就可以了。
但是看 Spring Boot 的注册和调用过程没有 xml 方式的顺畅,这都是因为注解的特性决定的。注解用起来简单、方便,好处多多。但同时,注解会割裂传统的流程,传统流程都是一步一步主动调用,只要顺着代码往下看就可以了,而注解的方式会造成这个过程连不起来,所以读起来需要额外的一些方法。
Spring Boot 中的 IoC 过程,我们下次有机会再说。
获取本文高清泳道图请在公众号内回复「矢量图」
参考文档:
https://docs.spring.io/spring/docs
还可以读:
Spring 实现自定义 bean 的扩展
Spring AOP 和 动态代理技术
Spring Cloud 系列吐血总结
-----------------------
公众号:古时的风筝
一个斜杠程序员,一个纯粹的技术公众号,多写 Java 相关技术文章,不排除会写其他内容。
【最美人间四月天!】

正文到此结束
- 本文标签: web servlet 开发者 程序员 开发 http ioc HashMap java UI App 参数 core bean Spring cloud spring tab 配置 CTO list src Service springboot 源码 map 空间 value schema BeanDefinition Spring Boot 并发 classpath 安全 注释 key spring ioc message id 缓存 启动过程 cat 代码 XML 开源 Listeners AOP synchronized 测试 tar 管理 实例 总结 文章 IO 构造方法 定制 https IDE 解析 final 生命 cache ConcurrentHashMap
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

