java & 0xff
最近在tcp的基础上写一个自定义的协议,处理拆包粘包的时候发现一个情况
数据是以字节流的形式在tcp中传输,所以,大于一个字节的数据类型,都要转为byte[] 的形式
以int类型举例,在java中一个int类型的数据占4个字节,也就是需要new byte[4]
int a = 9071;
byte[] bytes = new byte[4];
bytes[0] = (byte) (a >> 24 ); // 拿到最高位的8位
bytes[1] = (byte) (a >> 16 );
bytes[2] = (byte) (a >> 8 );
bytes[3] = (byte) (a);
java中的数据类型都是有符号类型,也就是说区分正负的
一个字节=8bit,也就是说一个 byte 可以存放8个 0 或者 1
1 的二进制原码是 0 000 000 1
-1 的二进制原码是 1 000 000 1,补码是 1111 1111
二进制的最高位为符号位,所以byte 的取值范围为-128~127,(-2^7~2^7-1)
在 Java 中,是采用补码来表示数据的。
正数的补码和原码相同,负数的补码是在原码的基础上各位取反然后加 1。
譬如:int a = -29 的二进制表示为11111111111111111111111111100011
int 32字节,先取a的的绝对值求原码,29 的原码为00011101
不足4字节,高位补24个0
00000000000000000000000000011101
再求反码
11111111111111111111111111100010
+1
于是得到了-29的二级制补码
11111111111111111111111111100011
通过上面的代码看,int 在tcp传输的时候要转换为byte[], int a = -29; 一共4个字节32位,于是byte[4] 每一个小标存储一个字节也就是8位,写到这里我们发现还是用不上&0xff,不要着急,接下来就用上了
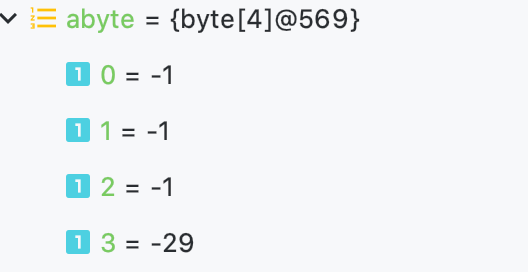
于是,我们发现int 29 被装进 byte[] 的时候,成了这个样子:
下标0表示的是前8位,
下标1表示的是8-16位,
下标2表示的是16-24位,
下标3表示的是24-32位
也很容易理解,因为-1的补码就是 11111111 ,所以这4个byte的二进制组合起来就是int -29 的二进制
你把数据拆开了还要把它组合起来啊,也就是byte[] 转 int
分解问题就是单个byte 转 int
byte 八个字节,int 32个字节,byte为负数的时候,需要把高24位的全部置为0.保持低八位的一致性,不然得到的int就成了另一个数字
0xff 是16进制,也就是255 二进制也就是 1111 1111
补到32位也就是 这里是24个0 这里是八个1
一个负数的byte & 0xff的时候,高24位就成了0,保证了一致性
然而正数的补码还是它自己,不受影响,虽然只有负数的时候才需要 &0xff,但不至于再判断一次去吧?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

