Spring Data Jpa 入门学习
本文主要讲解 springData Jpa 入门相关知识, 了解JPA规范与Jpa的实现,搭建springboot+dpringdata jpa环境实现基础增删改操作,适合新手学习,老鸟绕道~
1. ORM 概论
ORM(Object-Relational Mapping)顾名思义就是表示对象关系映射。在面向对象的软件开发中,我们肯定是需要和数据库进行交互的,那么这里就存在一个问题如何将数据库中的表与我们代码中的对象映射起来尼,我们只要有一套程序能够做到 建立对象与数据库的关联 ,操作对象就可以直接操作数据库数据,就可以说这套程序 实现了ORM对象关系映射
简单的说:ORM就是建立实体类和数据库表之间的关系,从而达到操作实体类就相当于操作数据库表的目的。
目前市面上主流的ORM框架有Hibernate、Mybatis、Spring Data Jpa等,
Mybatis
2. JPA
-
JPA的全称是Java Persistence API, 即Java持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。 -
JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
2.1 JPA优势
- 标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问 API ,这保证了基于 JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
- 容器级特性的支持
JPA 框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
- 简单方便
JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用
javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成 - 查询能力
JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是
Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING等通常只有SQL才能够提供的高级查询特性,甚至还能够支持子查询。 - 高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
2.2 JPA与hibernate的关系
- JPA规范本质上就是一种ORM规范,注意不是ORM框架——因为JPA并未提供ORM实现,它只是制订了一些规范,提供了一些编程的API接口,但具体实现则由服务厂商来提供实现。
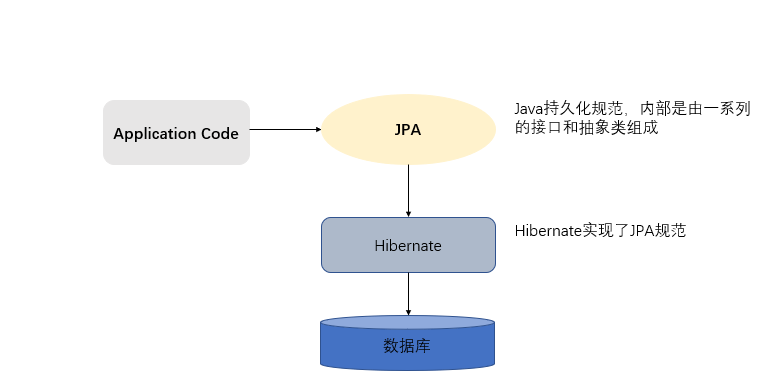
- JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。JPA怎么取代Hibernate呢?JDBC规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
3. Spring Data JPA
Spring Data JPA 是 Spring 基于 ORM 框架、 JPA 规范的基础上封装的一套 JPA 应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
-
Spring Data JPA让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现, 在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦
3.1 JPA 、Hibernate 与Spring Data Jpa
-
JPA是一套规范,内部是有接口和抽象类组成的。 -
hibernate是一套成熟的ORM框架,而且Hibernate实现了JPA规范,所以也可以称hibernate为JPA的一种实现方式,我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程) -
Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
3.2 五分钟快速上手 Spring Data Jpa
3.2.1 构建开发环境
-
- 构建
springboot脚手架构建初始环境,我们不要web模块,只需要spring data jpa、mysql即可
- 构建


-
- 等待构建完成,
spingboot的强大在这里体现了,为我们快速构建了开箱即用的环境,我们在application.yml文件中添加我们需要的配置信息
- 等待构建完成,
spring:
datasource:
url: jdbc:mysql:///db?serverTimezone=GMT
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update # 数据库没有表时自动构建,
database: mysql # 指定数据库类型
generate-ddl: true # 自动生成
show-sql: true # 现实sql到控制台
database-platform: org.hibernate.dialect.MySQL8Dialect # 数据库方言 DataBbase枚举内获取
3.2.2 进行增删改开发
-
- 创建映射实体类
DeptEntity, 这里用来lombok插件省去了get/set方法,对于@Column注解是可以放在get方法上的
- 创建映射实体类
@Entity
@Table(name = "dept", schema = "db", catalog = "")
@ToString
@Data
public class DeptEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "DEPTNO", nullable = false)
private int deptno;
// name : 数据库中的列名 nullable : 是否为空 length:长度
@Column(name = "DNAME", nullable = true, length = 14)
private String dname;
@Column(name = "LOC", nullable = true, length = 13)
private String loc;
@Column(name = "flag", nullable = true)
private Integer flag;
@Column(name = "type", nullable = true, length = 20)
private String type;
}
-
- 编写完实体后,然后添加相应的
Dao层接口,需要继承JPA的接口JpaRepository, 代码如下:
- 编写完实体后,然后添加相应的
public interface DeptRepository extends JpaRepository<DeptEntity,Integer> {
}
我们的 dao 层是一个接口,没有具体的实现,在继承的接口中已经定义了一些常用的方法供我们使用,后面详细介绍
-
- 编写测试类方法进行验证
@SpringBootTest
public class SpringJpaTest {
@Autowired
private DeptRepository deptRepository;
@Test
public void jpaTest(){
List<DeptEntity> list = deptRepository.findAll();
System.out.println(list);
}
}
-
- 看到打印出查询结果
Hibernate: select deptentity0_.deptno as deptno1_0_, deptentity0_.dname as dname2_0_, deptentity0_.flag as flag3_0_, deptentity0_.loc as loc4_0_, deptentity0_.type as type5_0_ from dept deptentity0_ [DeptEntity(deptno=10, dname=张三, loc=NEW YORK, flag=10, type=真实类型), DeptEntity(deptno=20, dname=RESEARCH, loc=DALLAS, flag=20, type=11), DeptEntity(deptno=50, dname=zonghebu, loc=CHICAGO, flag=null, type=null), DeptEntity(deptno=60, dname=??, loc=123, flag=null, type=22), DeptEntity(deptno=61, dname=??, loc=123, flag=null, type=null), DeptEntity(deptno=62, dname=??, loc=123, flag=null, type=null), DeptEntity(deptno=72, dname=??, loc=123, flag=null, type=null)]
同时可以看到sql的语句,这是 Hibernate 帮我们生成的,总的来说 Spring Data Jpa 的实现是依赖了 Hibernate 对 Jpa 规范的实现,
-
- 相应的添加与查询排序方法的测试全部如下:
@Test
public void query(){
Sort deptno = Sort.by(Sort.Direction.DESC,"deptno");
List<DeptEntity> all = deptRepository.findAll(deptno);
System.out.println(all);
}
@Test
public void insert(){
DeptEntity entity = new DeptEntity();
entity.setDname("质量控制部门");
entity.setFlag(1);
entity.setType("test");
//保存同时将保存结果返回
DeptEntity save = deptRepository.save(entity);
System.out.println(save);
}
增加方法打印:
Hibernate: insert into dept (dname, flag, loc, type) values (?, ?, ?, ?)
其他方法不再赘述都基本相似,这些方法都是继承自 JpaRepository 接口中
3.3 复杂查询的实现
3.3.1 接口已定义的方法
在父接口中定义了一套常用的查询, 相对比较简单,如下:
Optional<T> findById(ID id); Iterable<T> findAllById(Iterable<ID> ids); List<T> findAll(Sort sort); List<T> findAllById(Iterable<ID> ids);
3.3.2 jpql的查询方式
- jpql : jpa query language (jpq查询语言)
- 特点:
语法或关键字和sql语句类似
查询的是类和类中的属性
- 需要将JPQL语句配置到接口方法上
1.特有的查询:需要在dao接口上配置方法
2.在新添加的方法上,使用注解的形式配置jpql查询语句
3.注解 : @Query
- 代码实现如下:
在dao接口中自定义方法并添加注解
/**
* 通过 deptno查询
* 使用@Query注解来编写jpql 语句 是面向对象的操作
* sql: select * from dept where deptno = ?
* jpql: select * from DeptEntity where deptno = ?1
*
* 在jpql中占位符好指定索引,与参数列表对应,从1开始
* @param id
* @return
*/
@Query(value=" from DeptEntity where deptno = ?1")
DeptEntity queryDept(Integer id);
/**
* DML 操作, 需要加@Modifying 注解
* 在多个条件时要注意占位符下标的数字要和参数列表对应
* 需要注意,DML 语句需要事务配置,需要加 @Transactional 注解,一般在业务层,而不再数据层,
* @param name
* @param id
*/
@Query(value="update DeptEntity set dname=?1 where deptno=?2")
@Modifying
void updateName(String name,Integer id);
// JAVA
测试方法代码:
@Test
public void queryDept(){
DeptEntity entity = deptRepository.queryDept(10);
System.out.println(entity);
}
/**
* 这里需要加 @Transactional 注解来管理事务
*/
@Test
@Transactional
public void updateName(){
deptRepository.updateName("测试",10);
}
3.3.3 sql语句查询方式
- 特有的查询:需要在dao接口上配置方法
- 在新添加的方法上,使用注解的形式配置sql查询语句
- 注解 :
@Query
value :jpql语句 | sql语句 nativeQuery :false(使用jpql查询) | true(使用本地查询:sql查询) 是否使用本地查询
示例代码:
dao接口代码:
/**
* 需要添加 nativeQuery 参数来设置是都是sql查询, 默认是false ,是jpql查询
* @param num
* @return
*/
@Query(value="select * from dept where flag = ?",nativeQuery=true)
List<DeptEntity> queryList(Integer num);
测试代码:
@Test
public void nativeQuery(){
List<DeptEntity> list = deptRepository.queryList(10);
System.out.println(list);
}
3.3.4 方法名规则查询
- 是对jpql查询,更加深入一层的封装
- 我们只需要按照SpringDataJpa提供的方法名称规则定义方法,不需要再配置jpql语句,完成查询
-
规则:
-
findBy开头: 代表查询
对象中属性名称(首字母大写)
- 含义:根据属性名称进行查询
-
接口代码:
/**
* 方法名的约定:
* findBy : 查询
* 对象中的属性名(首字母大写) : 查询的条件
* Dname
* * 默认情况 : 使用 等于的方式查询
* 特殊的查询方式
*
* findAllByDname -- 根据名称查询
*
* 再springdataJpa的运行阶段
* 会根据方法名称进行解析 findBy from xxx(实体类)
* 属性名称 where dname =
*
* 1.findBy + 属性名称 (根据属性名称进行完成匹配的查询=)
* 2.findBy + 属性名称 + “查询方式(Like | isnull)”
* findAllByDnameLike
* 3.多条件查询
* findBy + 属性名 + “查询方式” + “多条件的连接符(and|or)” + 属性名 + “查询方式”
*/
List<DeptEntity> findAllByDname(String name);
List<DeptEntity> findAllByDnameAndAndFlag(String name,Integer num);
List<DeptEntity> findAllByDnameLike(String name);
测试代码省略
- 主要的一些规则对应如下:

3.4 getOne,findOne以及findById的区别
这三个方法乍一看都是一样的功能,都是通过主键返回一个实体,但是再实际使用中还是有区别的,尤其在一对一的关系中我们如果直接用 getOne 查询,会出现 下面错误:
org.hibernate. LazyInitializationException: could not initialize proxy - no Session
下面我们简单说一下这三个方法:
- getOne
getOne是懒加载,需要在 springboot 增加这个配置: spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true ,yml中也是一样配置。但这种方式不太友好,建议不要使用。
每次初始化一个实体的关联就会创建一个临时的 session 来加载,每个临时的 session 都会获取一个临时的数据库连接,开启一个新的事物。这就导致对底层连接池压力很大,而且事物日志也会被每次 flush .
设想一下:假如我们查询了一个分页 list 每次查出1000条,这个实体有三个 lazy 关联对象, 那么,恭喜你,你至少需要创建 3000 个临时 session+connection+transaction .
getOne 来自 JpaReposiroty 接口,对于传入的标识则返回一个实体的引用;且取决于该方法的实现,可能会出现 EntityNotFoundException ,并会拒绝一些无效的标识;
- findById
findById 来自 CrudRepository 接口,通过它的 id 返回一个实体;
findById返回一个Optional对象;
- findOne
findOne 来自 QueryByExampleExecutor 接口, 返回一个通过 Example 匹配的实体或者 null ;
findOne返回一个Optional对象,可以实现动态查询
本文由 AnonyStar 创作,可自由转载、引用,但需署名作者且注明文章出处
文章标题: Spring Data Jpa 入门学习
正文到此结束
- 本文标签: 自动生成 索引 tab 压力 数据 注释 插件 Connection ACE ORM session 测试 数据库 开发者 代码 组织 dataSource Word 本质 root find UI NFV list 企业 http 业务层 模型 GMT web tar 配置 API value 开发 DDL Action springboot 并发 update map 管理 Select 参数 entity Persistence id Proxy java https sql 大数据 解析 分页 src JPQL IO JDBC spring 质量 标题 NSA App mybatis example JPA executor 连接池 mysql db cat IDE 设计模式 软件 schema 文章
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

