如何使用Jsoup爬取网页内容
前言:
这是一篇迟到很久的文章了,人真的是越来越懒,前一阵用jsoup实现了一个功能,个人觉得和selenium的webdriver原理类似,所以今天正好有时间,就又来更新分享了。
实现场景:
爬取博客园 https://www.cnblogs.com/longronglang ,文章列表中标题、链接、发布时间及阅读量
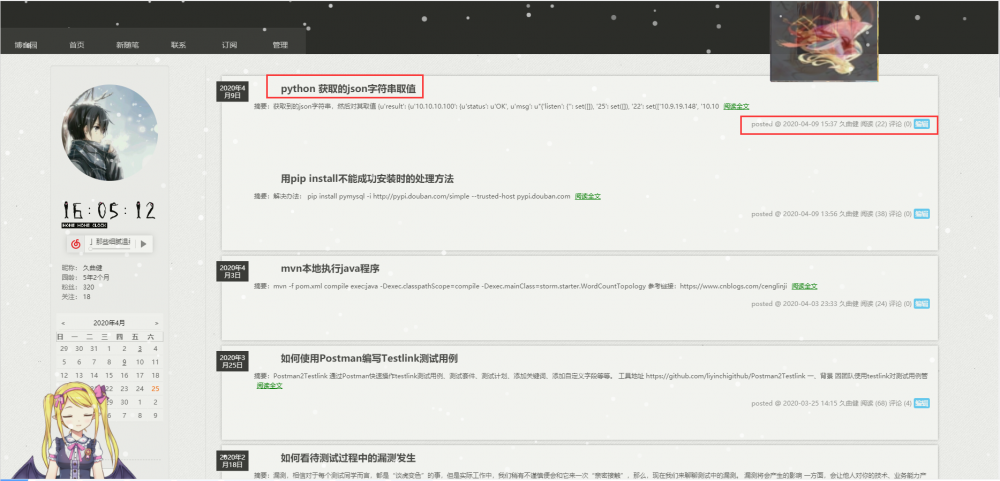
思路:
1、引入jar包
2、通过httpclient,设置参数,代理,建立连接,获取HTML文档(响应信息)
3、将获取的响应信息,转换成HTML文档为Document对象
4、使用jQuery定位方式,这块就和web自动化一样了定位获取文本及相关属性
相关详细使用参考官网: https://jsoup.org/
实现:
1、引入依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
2、通过httpclient,设置参数,代理,建立连接,获取HTML文档(响应信息)
String requestUrl = "https://www.cnblogs.com/longronglang/";
HttpClient client = new HttpClient();
HttpClientParams clientParams = client.getParams();
clientParams.setContentCharset("UTF-8");
GetMethod method = new GetMethod(requestUrl);
String response =method.getResponseBodyAsString();
3、将获取的响应信息,转换成HTML文档为Document对象
Document document = Jsoup.parse(response);
4、使用jQuery定位方式,这块就和web自动化一样了定位获取文本及相关属性
这里可以仔细看下,也可以说是核心思路了,如下图:
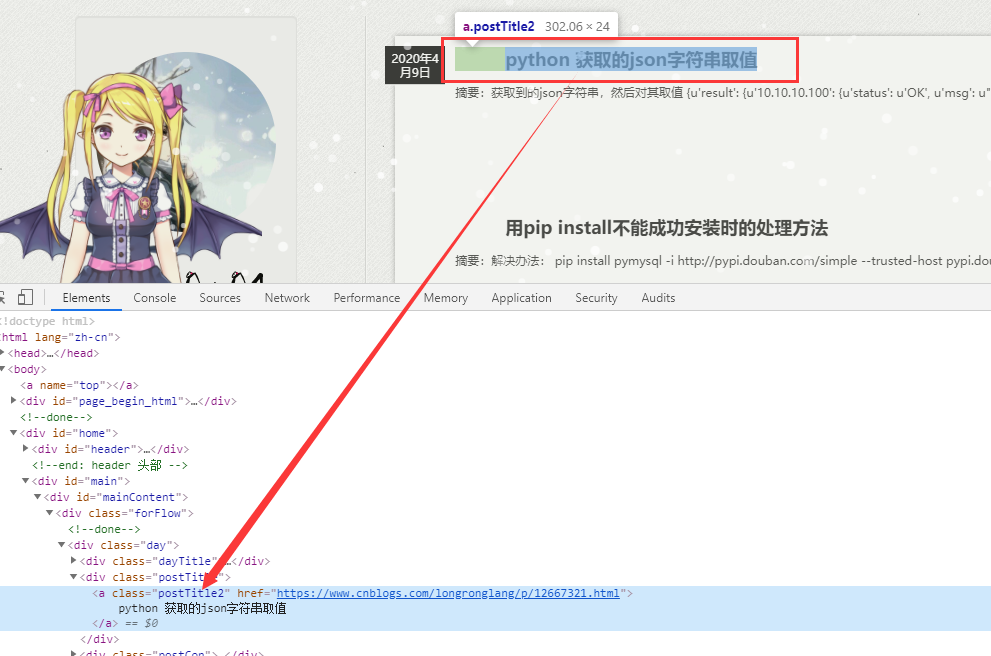
从图中可以看到,文章标题在在a标签中,也就是通过class属性为postTitle2进行绑定,那么我们的dom对象就定位到这里即可,那么我想获取文章标题这个dom对象,可以写成如下代码:
Elements postItems = document.getElementsByClass("postTitle2");
同理,获取发布时间及阅读量,也可以写成如下代码:
Elements readcontexts = document.getElementsByClass("postDesc");
最后我们来段整合的代码如下:
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpClientParams;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.junit.Test;
import java.io.IOException;
public class JsoupTest {
@Test
public void test() {
String requestUrl = "https://www.cnblogs.com/longronglang/";
HttpClient client = new HttpClient();
HttpClientParams clientParams = client.getParams();
clientParams.setContentCharset("UTF-8");
GetMethod method = new GetMethod(requestUrl);
String response = null;
int code = 0;
try {
code = client.executeMethod(method);
response = method.getResponseBodyAsString();
if (code == HttpStatus.SC_OK) {
Document document = Jsoup.parse(response);
Elements postItems = document.getElementsByClass("postTitle2");
Elements readcontexts = document.getElementsByClass("postDesc");
for (int i = 0; i < postItems.size(); i++) {
System.out.println("文章标题:" + postItems.get(i).text());
System.out.println("文章地址:" + postItems.get(i).attr("href"));
System.out.println("发布信息:" + readcontexts.get(i).text());
}
} else {
System.out.println("返回状态不是200,可能需要登录或者授权,亦或者重定向了!");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果如下:
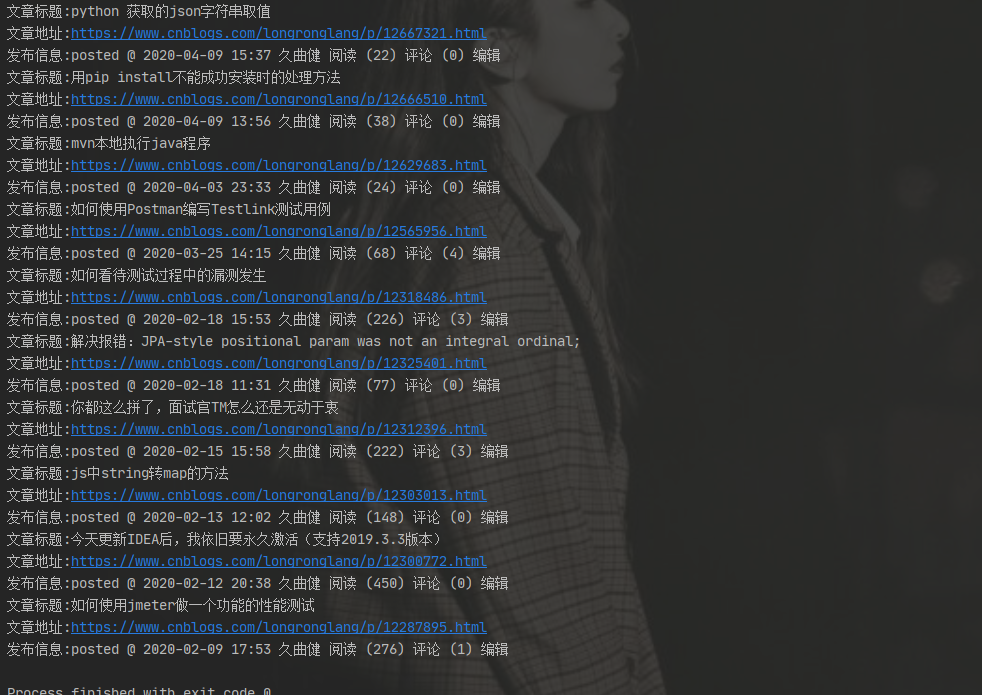
到此,一个爬虫搞完,这里只事抛砖引用,有兴趣的同学,请自行扩展。
如果感情一开始就是不对等的,那么索性就早点结束掉它,利人利己。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

