hashmap源码-hash算法
注意,本系列文章都是基于 jdk 1.8
这是 hashmap 源码系列文章的第一篇,主要带大家初步了解 hashmap 几个重要的知识点,在后续的文章中会深入讲解框架中各个部分的实现细节。
内容主要涉及:
- 基础结构
- hashmap 初始化
- hash 算法
- 扰动函数
基础结构
hashmap 的基础结构涉及几部分:
- 数组
- 链表
- 红黑树
正常情况下 hashmap 元素存取的时间复杂度都为 O(1),如何做到的呢?这就要得益于它的散列机制,以元素的 key(hashcode值)为基础,通过散列函数,能够映射到表中某个具体索引位置,散列函数的实现即为 hash 算法。
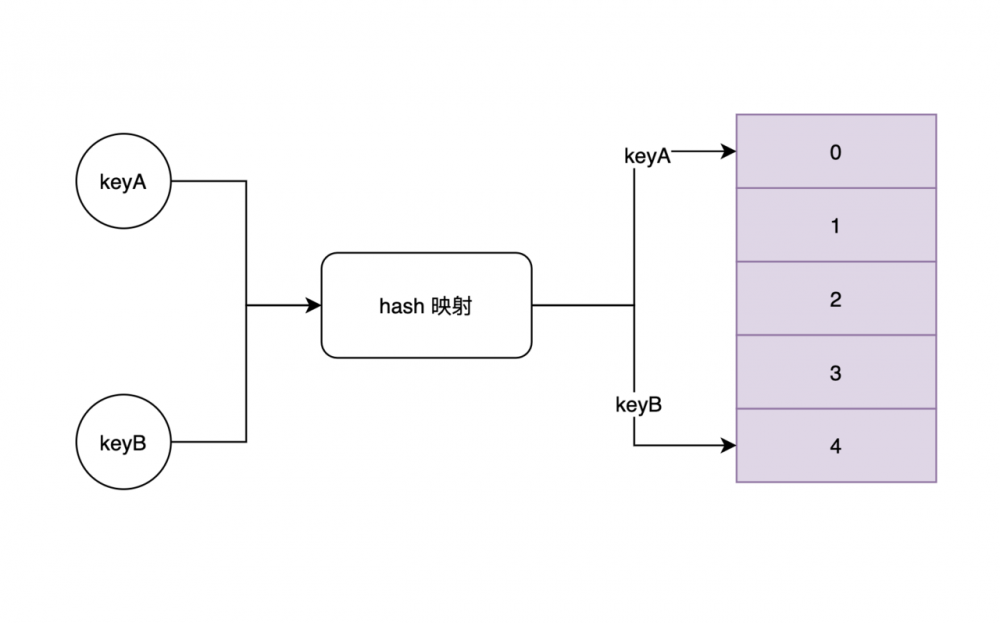
那有没有可能两个元素映射到了同一个索引位置呢?是存在这种情况的,称为 hash 冲突。发生冲突的元素会在同一个索引位置衍生出链表。
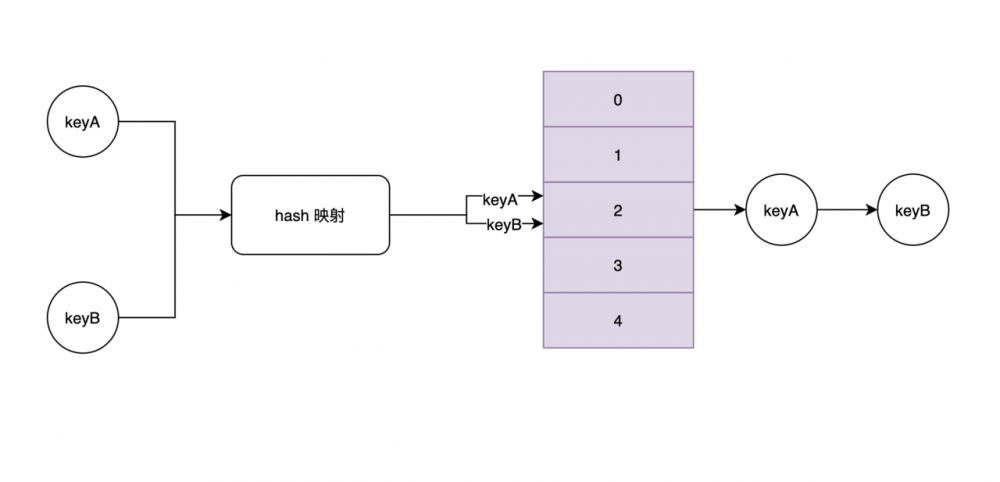
当大量元素存在 hash 冲突时,hashmap 的存取时间复杂度将会演变成 O(n),需要遍历链表。为了提升效率,jdk 1.8 在链表长度达到设定的阈值之后,会将链表转变成红黑树,遍历的时间复杂度变为 O(logn)。

初始化过程
先看到 hashmap 中几个重要的成员变量。
// hashmap 中一个最小的数据存储单元为 Node,被形象的称为哈希桶
// table 则是哈希桶数组,作为容器底层的基础实现
transient Node<K,V>[] table;
// 哈希桶当前能够存储的元素阈值,后面讲到的扩容就是基于这个数值
int threshold;
// 负载因子,threshold = table.capacity * loadFactor,hashmap 不是等数组存满了才进行扩容
final float loadFactor;
复制代码
// 初始化时,默认的哈希桶数组容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
复制代码
下面看到一段代码,初始化容量指定为 10,然后通过反射机制拿到 threshold 成员变量,大家猜一下它的数值的是多少,正常情况下通过计算 threshold = 10 * 0.75 = 7,如果真这么想就 too young too simple 了。
public static void main(String[] args) throws Exception {
HashMap<String, String> hashMap = new HashMap(10);
Field thresholdField = HashMap.class.getDeclaredField("threshold");
Field tableField = HashMap.class.getDeclaredField("table");
thresholdField.setAccessible(true);
tableField.setAccessible(true);
int threshold = (int)thresholdField.get(hashMap);
System.out.println("初始化后 threshold 值:" + threshold);
}
复制代码
看一下结果,你想到了吗?
初始化后 threshold 值:16 复制代码
初始化相关代码:
public HashMap(int initialCapacity) {
// initialCapacity 传进来的初始化容量,此时为 10
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
复制代码
重点看到 tableSizeFor(initialCapacity) 这个方法, 它会强行把初始化 cap 转成 2 的整次幂,至于为什么这么做,这就关系到下面要讲的 hash 算法了 ,先记住这个知识点。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
复制代码
那大家又有疑问了,为什么这边没有用到负载因子,再看到下面的代码
HashMap<String, String> hashMap = new HashMap(10);
Field thresholdField = HashMap.class.getDeclaredField("threshold");
Field tableField = HashMap.class.getDeclaredField("table");
thresholdField.setAccessible(true);
tableField.setAccessible(true);
int threshold = (int)thresholdField.get(hashMap);
System.out.println("初始化后 threshold 值:" + threshold);
hashMap.put("1", "a");
threshold = (int)thresholdField.get(hashMap);
System.out.println("添加元素后 threshold 值:" + threshold);
复制代码
运行结果:
初始化后 threshold 值:16 添加元素后 threshold 值:12 复制代码
其实 hashmap 使用的是一种类似于『懒加载』的机制,只有在首次进行元素添加操作时才会触发真正的初始化,这时候就重新计算了 threshold 的值。
hash算法
看到 hash() 方法,它基于 key 的 hashcode 值重新计算 hash值,可以看到 null 对应的 hash 值为 0。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
拿到这个 hash 值是不是可以直接映射成数组下标呢?还不行,如果直接使用 hash 值映射就要求数组容量非常庞大(hash 值为 32 为整型),因此需要和数组长度进行取模运算。
那 hashmap 是不是直接采用模运算呢,看到下面代码。
// n 为数组长度,i 为计算之后的数组索引 i = (n - 1) & hash 复制代码
上面提到,hashmap 初始化过程中会强行把数组容量转成 2 的整次幂,包括后面要讲到的扩容,都需保证数组长度为 2 的整次幂,这是一个非常取巧的操作。 因为当数组长度 n 为 2 的整次幂时,(n - 1) & hash 的效果等同于 hash % n,并且 & 操作底层硬件是直接支持的,比模运算的效率更高。
扰动函数
当然一个好的 hash算法,很大程度能够降低 hash 冲突的概率。再回到 hash 值的计算步骤,为什么要把 hashcode 右移 16 位再与原值进行异或运算?
// 扰动函数代码 (h = key.hashCode()) ^ (h >>> 16) 复制代码
先来看一下这个算法的效果,相当于将 hashcode 高低位进行了混合,使得低位的特征更加明显,同时也保留了高位的特征;
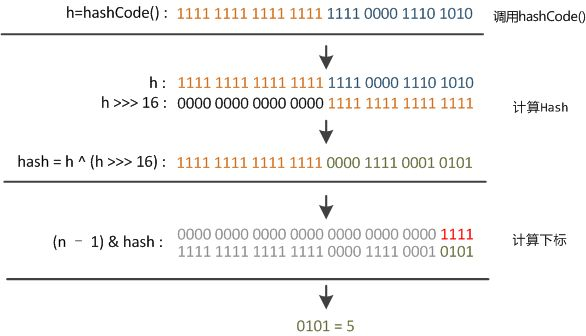
结合前面讲到的 hash 映射方式 i =(n - 1)& hash,(n - 1) 相当于低位掩码,如果 hash 值低位的特征足够明显,那么映射结果 i 发生冲突的概率就越小,这就是扰动函数的价值。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

