Java NIO基础,比对BIO的优势
为了更好的演示BIO与NIO之间的区别,我们先用一个服务器示例来了解一个BIO实现网络通行的过程。
1. 单线程下的BIO服务器
服务端
public class BioServer {
public static void main(String[] args) throws IOException {
byte[] bs = new byte[1024];
// 创建一个新的ServerSocket,绑定一个InetSocketAddress,监听8000端口上的连接请求
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(8000));
// accept专门负责通信
while(true) {
System.out.println("等待连接---");
// =====①:accept()函数的执行
Socket accept = serverSocket.accept(); // 这里会阻塞以释放CPU资源
System.out.println("连接成功---");
System.out.println("等待数据传输---");
// =====②:getInputStrea()函数获取客户端传送的输入流
int read = accept.getInputStream().read(bs); // 这里也可能阻塞
System.out.println("数据传输成功---" + read);
String content = new String(bs);
System.out.println(content);
}
}
}
复制代码
客户端
public class Client {
public static void main(String[] args) throws IOException {
// 建立一个socket去连接服务端
Socket socket = new Socket();
socket.connect(new InetSocketAddress("127.0.0.1", 8000));
Scanner scanner = new Scanner(System.in);
while (true) {
// =====③:getOutputStream()函数中写入的是从控制台输入的字符
String next = scanner.next();
socket.getOutputStream().write(next.getBytes());
}
// socket.close();
}
}
复制代码
缺陷分析
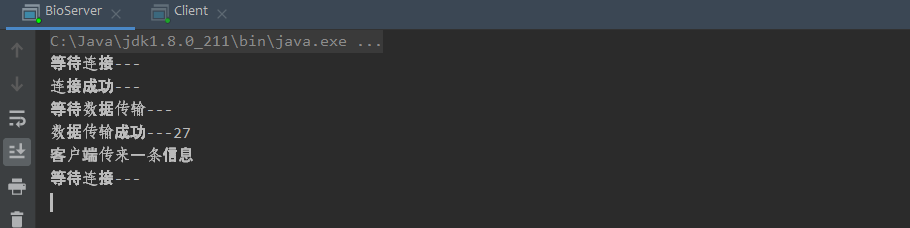
首先我们先开启服务端,开启后的控制台输出如下,程序会在运行到①的地方停下来阻塞掉,等待客户端连接上来。如果没有客户端连接的话,这个线程将会一直停在这里。

那么我们现在先开启客户端,然后不在控制台输入数据,如下图所示,服务端程序会一直卡在②的地方停下来,因为客户端卡在了③的位置,你一直没有在控制台输入字符,客户端的没有输出流,那么服务端没办法接收到客户端发送过来的数据,从而阻塞在②的位置。

假设现在客户端传来一条信息,那么客户端程序就可以接受到这条数据,阻塞在②处的线程就会从新运行下去。
从这里我们很容易想到这种模式的服务器的缺陷,首先,它一次只能接收一个接收一个客户端的请求,要是有多个,没办法,在处理完前面的连接前,它是没办法往下执行的,那么如果前面连接一直不传送消息过来,就像我们刚刚将程序阻塞在③处一样,那么服务端就无法往下运行了,面对这种问题,我们想到用多线程来解决,一个请求对应一个线程,那么就没有线程在③阻塞的问题了。
2. 多线程下的BIO服务器
客户端
public static void main(String[] args) throws IOException {
byte[] bs = new byte[1024];
// 创建一个新的ServerSocket,绑定一个InetSocketAddress,监听8000端口上的连接请求
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(8000));
// accept专门负责通信
while(true) {
System.out.println("等待连接---");
// =====①:accept()函数的执行
Socket socket = serverSocket.accept(); // 这里会阻塞以释放CPU资源
System.out.println("连接成功---");
// =====④:新建一个线程来处理这个客户端连接
Thread thread = new Thread(new ExecuteSocket(socket));
thread.start();
}
}
static class ExecuteSocket implements Runnable {
byte[] bs = new byte[1024];
Socket socket;
// 处理每个客户端连接——读写
public ExecuteSocket(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
// =====⑤:这里还是有阻塞的,不过是在线程里阻塞,不影响主线程
socket.getInputStream().read(bs);
} catch (IOException e) {
e.printStackTrace();
}
String content = new String(bs);
System.out.println(content);
}
}
}
复制代码
问题分析
客户端还是用刚才的客户端,没什么影响毕竟。
那么现在我们就可以开启客户端和服务端了,我们尝试下开启两个客户端,服务端的控制台输出如下:
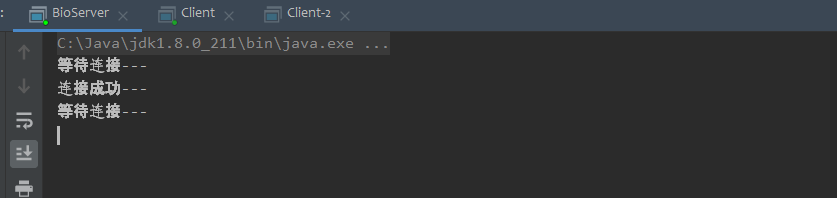
我们可以发现现在服务端的main线程并没有阻塞,而是可以继续往下执行,因为在④处它开启了一个子线程去处理这个连接的请求了,所以哪怕是客户端不发送数据,阻塞也是在子线程中的⑤处发生的,这样对服务端处理下一个请求并没有太大的影响。
问题到这里看似好像解决了,但是让我们考虑一下这种方案的影响,当我们要管理多个并发客户端时,我们需要为每个新的客户端Socket创建一个新的Thread,如下图所示:
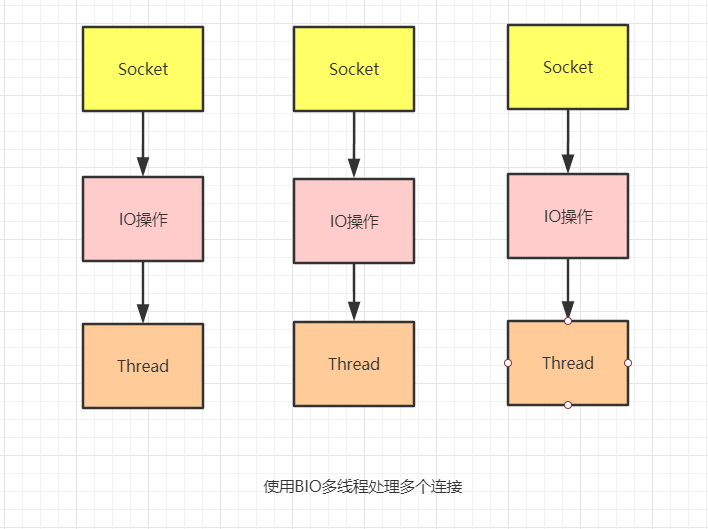
所以这种模型也有很多的吐槽点,首先,在任何时候都有可能有 大量的线程处于休眠状态 ,只是等待输入或者输出数据就绪,这对于我们的系统来说就是一种巨大的资源浪费;然后,我们需要 为每个线程都分配内存 ,其默认值大小区间为64kb到1M。而且,我们还要考虑到,哪怕虚拟机本身是可以支持大量线程,但是远在达到该极限之前, 上下文切换所带来的开销 就会给我们的系统带来巨大的资源消耗。
二、NIO的原理/实现一个NIO服务器
1. 用伪代码解释NIO
首先我们来了解一下NIO的原理。假设现在Java开发了两个API,一个叫 Socket.setNoBlock(boolean) ,可以让socket所在线程在没有得到客户端发送过来的数据时也不会阻塞,而是继续进行。另外一个叫 ServerSocket.setNoBlock(boolean) ,可以让ServerSocket所在线程在没有得到客户端连接时也不会阻塞而往下运行。下面我们用伪代码来分析一波:
public class BioServer {
public static void main(String[] args) throws IOException {
List<Socket> socketList = null; // 用以存放连接服务端的socket
byte[] bs = new byte[1024];
ServerSocket serverSocket = new ServerSocket();
// =====①:这个地方是伪代码,现在假设方法执行后serverSocket在没有客户端连接的情况下也会继续执行
serverSocket.setNoBlock(true);
serverSocket.bind(new InetSocketAddress(8000));
while(true) {
System.out.println("等待连接---");
Socket socket = serverSocket.accept(); // 现在这里不会阻塞以释放CPU资源
if (socket == null) { // 没客户端连接过来
// =====:②找到以前连接服务端的socket,看它们有没有发给我数据
for (Socket socket1 : socketList) {
int read = socket.getInputStream().read(bs);
if (read != 0) { // 这个socket有数据传过来
// 这里处理你的业务逻辑
}
}
} else { // 有客户端连接过来
// =====:③这个地方是伪代码,现在假设方法设置后socket不会阻塞
socket.setNoBlock(true);
// =====:④将这个socket添加到socketList中
socketList.add(socket);
for (Socket socket1 : socketList) { // 遍历socketList,看看哪个socket给服务端发送数据
int read = socket.getInputStream().read(bs);
if (read != 0) { // 这个socket有数据传过来
// 这里处理你的业务逻辑
}
}
}
}
}
}
复制代码
这里我们声明了一个socketList,用以存放连接到服务端的socket。现在我们在①处设置了让这个serverSocket在本次循环就算没有客户端连接上来也不会阻塞,而是继续执行下去。执行下去之后判断分两叉,一叉是没有客户端连接过来的情况,那么就在②拿出socketList,看看之前连接的socket里面有没有哪个给我发数据,有的话就来处理一下。另外一叉就是在有客户端连接上来的情况了,首先我们在③处将socket也设置为非阻塞的,然后将这个socket添加到SocketList当中,然后继续拿出socket,看看有没有哪个socket给我发数据,有就处理一下。
现在到这里,NIO的思路基本理清了,下面我们用代码来实现一个简单的服务端。
2. 用NIO实现一个简单服务端
这里我们还是利用List来缓存Socket,之后再轮询是否有传输的数据。
public class NioServer {
public static void main(String[] args) {
List<SocketChannel> list = new ArrayList<>();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8001));
ssc.configureBlocking(false); // 在这里设置为非阻塞
while (true) {
SocketChannel socketChannel = ssc.accept();
if (socketChannel == null) {
Thread.sleep(1000);
System.out.println("没有客户端连接上来");
for (SocketChannel channel : list) {
int k = channel.read(byteBuffer);
System.out.println(k + "===== no connection =====");
if (k != 0) { // 有连接发来数据
byteBuffer.flip();
System.out.println(new String(byteBuffer.array()));
}
}
} else {
socketChannel.configureBlocking(false);
list.add(socketChannel);
// 得到套接字,循环所有的套接字,通过套接字获取数据
for (SocketChannel channel : list) {
int k = channel.read(byteBuffer);
System.out.println(k + "===== connection =====");
if (k != 0) {
byteBuffer.flip();
System.out.println(new String(byteBuffer.array()));
}
}
}
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
复制代码
OK,现在将上面的代码运行起来,再运行两个客户端代码,向8001端口发送数据,运行结果如下:
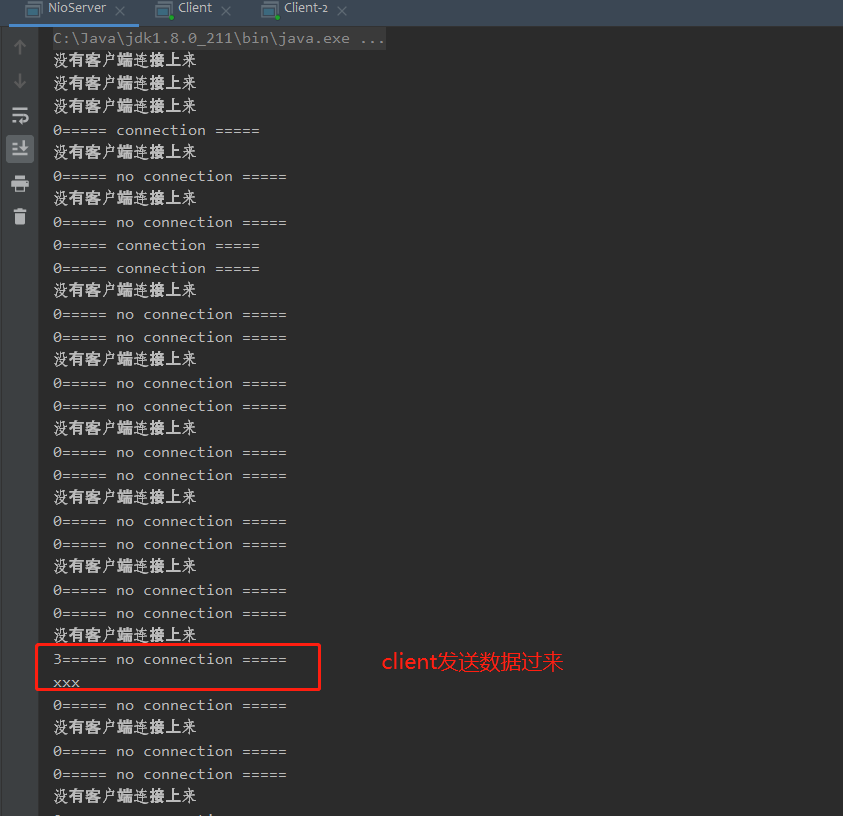
这种非阻塞实现可以让服务端节省下许多资源。但是这样的实现还是有弊端:
我们在这里采用了轮询的方式来接收消息,每次都会轮询所有的连接,查看哪个套接字中有准备好的消息。在连接到服务端的连接还少的时候,这种方式是没有问题的,但是如果现在有100w个连接,此时再使用轮询的话,效率就变得十分低下。而且很大一部分的连接基本都不发消息的,在100w个连接中可能只有10w个连接会有消息,但是每次连接程序后我们都得去轮询,这是很不适合的。
3. 用NIO加强服务端
首先我们要知道一个class java.nio.channels.Selector ,它是实现Java的非阻塞I/O的关键。什么是Selector,这里举例做解释:
在一个养鸡场,有这么一个人,每天的工作就是不停检查几个特殊的鸡笼,如果有鸡进来,有鸡出去,有鸡生蛋,有鸡生病等等,就把相应的情况记录下来,如果鸡场的负责人想知道情况,只需要询问那个人即可。
在这里,这个人就相当Selector,每个鸡笼相当于一个SocketChannel,每个线程通过一个Selector可以管理多个SocketChannel。
为了实现Selector管理多个SocketChannel,必须将具体的SocketChannel对象注册到Selector,并声明需要监听的事件(这样Selector才知道需要记录什么数据),一共有4种事件:
SelectionKey.OP_CONNECT(8) SelectionKey.OP_ACCEPT(16) SelectionKey.OP_READ(1) SelectionKey.OP_WRITE(4)
这个很好理解,每次请求到达服务器,都是从connect开始,connect成功后,服务端开始准备accept,准备就绪,开始读数据,并处理,最后写回数据返回。
所以,当SocketChannel有对应的事件发生时,Selector都可以观察到,并进行相应的处理。
public class NioServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress(8001));
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int n = selector.select();
if (n == 0) continue; // 如果没有连接发来数据,跳过此次循环
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
if (key.isAcceptable()) {
SocketChannel socketChannel = ((ServerSocketChannel) key.channel()).accept();
socketChannel.configureBlocking(false);
// 将选择器注册到客户端信道
// 并指定该信道key值的属性为OP_READ,
// 同时为该信道指定关联的附件
socketChannel.register(key.selector(), SelectionKey.OP_READ, ByteBuffer.allocate(1024));
}
if (key.isReadable()) {
// handle Read
}
if (key.isWritable() && key.isValid()) {
// handle Write
}
if (key.isConnectable()) {
System.out.println("isConnectable = true");
}
iterator.remove();
}
}
}
}
复制代码
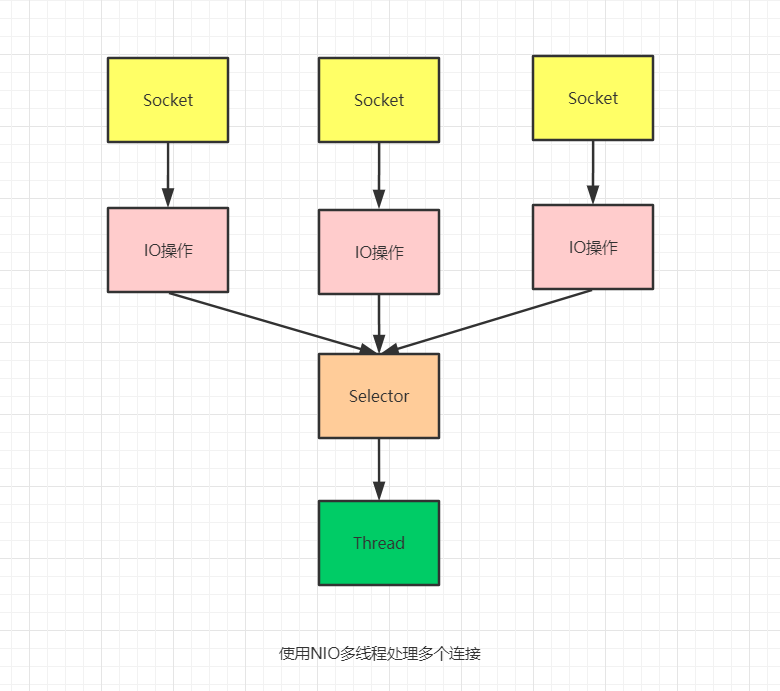
从这里我们看出,虽然之前我们用NIO做了多个客户端轮询,但是在真正在NIO实现时,我们并不会去这么做,而是使用 Selector ,将轮询的逻辑交由 Selector 处理,而 Selector 最终会调用到系统函数select()/epoll()。
三、select/epoll比对直接轮询
1. select底层逻辑
假设有多个连接同时连接服务器,那么根据上下文的设计,程序将会遍历这多个连接,轮询每个连接以获取各自数据的准备情况,那么这和我们自己写的程序有什么区别呢?
首先,我们自己写的Java程序本质也是在轮询每个Socket的时候去调用系统函数,那么轮询一个调用一次,会造成不必要的上下文切换开销。
而select会将请求从用户态空间 全量复制 一份到内核态空间,在内核空间来判断每个请求是否准备好数据,完全避免频繁的上下文切换。所以效率是比我们直接在应用层轮询要高的。
如果select没有查询到到有数据的请求,那么将会一直阻塞(是的,select是一个阻塞函数)。如果有一个或者多个请求已经准备好数据了,那么select将会先将有数据的文件描述符置位,然后select返回。返回后通过遍历查看哪个请求有数据。
select的缺点:
- 底层存储依赖bitmap,处理的请求是有上限的,为1024。
- 文件描述符是会置位的,所以如果当被置位的文件描述符需要重新使用时,是需要重新赋空值的。
- fd(文件描述符)从用户态拷贝到内核态仍然有一笔开销。
- select返回后还要再次遍历,来获知是哪一个请求有数据。
2. poll函数逻辑
poll的工作原理和select很像,先看一段poll内部使用的一个结构体
struct pollfd{
int fd;
short events;
short revents;
}
复制代码
poll同样会将所有的请求拷贝到内核态,和select一样,poll同样是一个阻塞函数,当一个或多个请求有数据的时候,也同样会进行置位,但是它置位的是结构体pollfd中的events或者revents置位,而不是对fd本身进行置位,所以在下一次使用的时候不需要再进行重新赋空值的操作。poll内部存储不依赖bitmap,而是使用pollfd数组的这样一个数据结构,数组的大小肯定是大于1024的。解决了select 1、2两点的缺点。
3. epoll
epoll是最新的一种多路IO复用的函数。这里只说说它的特点。 epoll和上述两个函数最大的不同是,它的fd是共享在用户态和内核态之间的,所以可以不必进行从用户态到内核态的一个拷贝,这样可以节约系统资源;另外,在select和poll中,如果某个请求的数据已经准备好,它们会将所有的请求都返回,供程序去遍历查看哪个请求存在数据,但是epoll只会返回存在数据的请求,这是因为epoll在发现某个请求存在数据时,首先会进行一个重排操作,将所有有数据的fd放到最前面的位置,然后返回(返回值为存在数据请求的个数N),那么我们的上层程序就可以不必将所有请求都轮询,而是直接遍历epoll返回的前N个请求,这些请求都是有数据的请求。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

