Java 基础数据结构分析
java -version java version "13.0.2" 2020-01-14 Java(TM) SE Runtime Environment (build 13.0.2+8) Java HotSpot(TM) 64-Bit Server VM (build 13.0.2+8, mixed mode, sharing)
Array
数组能够做到 快速随机访问 元素,这是因为当我们创建一个数组时:
var array = new Person[3]; array[0] = new Person(); 复制代码
java 首先把这个数组的引用存入栈中,然后到堆空间开辟一片 连续 的地址空间,并将数组引用指向堆地址空间。
当我们访问指定的数组元素时,则只需要根据 array 的引用地址 + 下标地址, 就能快速定位元素了。
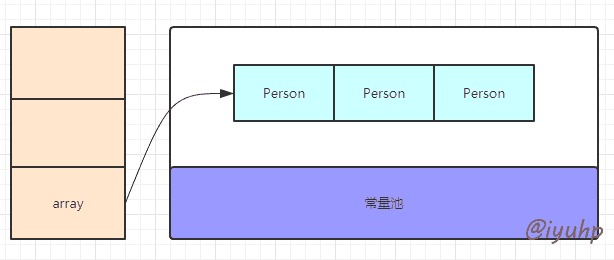
需要注意的是,数组需要连续空间的特性,让数组扩容难以实现,所以各种语言实现的数组, 数组的大小都是固定的 。
数组有 length 属性,这个属性记录的是数组的大小,而不是元素的个数。
List
java 中 list 常用的有 ArrayList 和 LinkedList。
ArrayList
底层基于数组 Object[] 实现,继承数组的优势,可快速随机访问元素,对于增删操作,则最坏需要 O(n) 。
我们知道 array 不能扩容,但是 ArrayList 明显可以,所以我们去看看,ArrayList ,是怎样扩容的。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData; // non-private to simplify nested class access
private int size;
protected transient int modCount = 0;
}
复制代码
- DEFAULT_CAPACITYP : 默认的容量大小
- elementData : 用来记录元素的数组,当我们初始化时,如果未指定容量,则用默认值初始化该数组,但是注意,此时 size 的值是零
- size : 记录列表中的元素个数,与数组的容量大小无关
- modCount : 该属性继承自 AbstractList 。所有会修改 list 大小的操作,该值都会增加。当我们通过 iterator 遍历时, 如果该值发生了改变(被另一个线程增加/删除了元素),就会抛出
ConcurrentModificationException
ArrayList 实现了 List / RandomAccess / Cloneable / Serializable 四个标记接口,标记接口 RandomAccess 在排序时会用到,用来选择迭代方式(for or iterator) 。
通过源码能看到, 当我们执行 add 操作时:
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
复制代码
ArrayList 首先会比较数组长度和元素大小,如果相等,则执行 grow() 方法,进行扩容,扩容完成后,再把元素加到 elementData 数组元素中。注意,此时的 elementData ,事实上,已经不是它了,它已经变成可扩容后的它。
现在看看 grow 方法的实现:
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
复制代码
实现的也很清晰,把原始元素大小,需要的最小扩容量( 左移一位 ),和期待的扩容量,做比较,最终得到一个新的容量大小。
之后通过 Arrays.copy 方法,将老数组的元素拷贝到新元素。
具体比较方式不贴了,简单描述下:
OutOfMemoryError
正常情况下,一次扩容的容量,会增加源数组大小的二分之一(即上面左移一位的操作)
LinkedList
底层基于 双向链表 实现,对于增删,效率极高。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
protected transient int modCount = 0;
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
复制代码
可以看到, LinkedList 实现了 List,Deque,Cloneable 和 Serializable 接口。Deque 即我们所说的双端队列。在 util 包下,还有 ArrayDeque 的实现。
Node 的结构中,主要有 prev , next 和 item ,分别指向上一个节点,下一个节点,item 保存当前节点数据。
因为每个节点都需要保存上下两个节点的信息,所以必然比 ArrayList 要消耗更多的空间
Map
这里以 HashMap 为主。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
int threshold;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
transient Node<K,V>[] table;
}
复制代码
HashMap 几个重要的参数:
- TREEIFY_THRESHOLD : 树化阈值, 即当 map 中的链表长度大于该值时, 会将链表转为 红黑树 [1]
- UNTREEIFY_THRESHOLD : 当红黑树 size 小于该值时,重新转为链表
- DEFAULT_INITIAL_CAPACITY : hashmap 初始化的容量大小
- table : 即 hash 表,hashmap 做 hash 时,最终散列到这张表上,长度适中为 2 n
- DEFAULT_LOAD_FACTOR :常说的 装载因子 。hashmap 判断是否需要 resize 时,会根据
threshold判断,而threshold则是根据 装载因子 * table.length 算出来的
我们 new HashMap<Object, Object>(9) 时, HashMap 就会去初始化 loadFactor 和 threshold [2]
HashMap 大概就长这个样子:
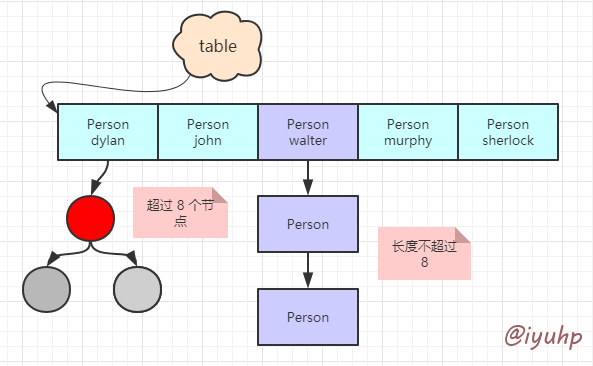
HashMap 的扩容
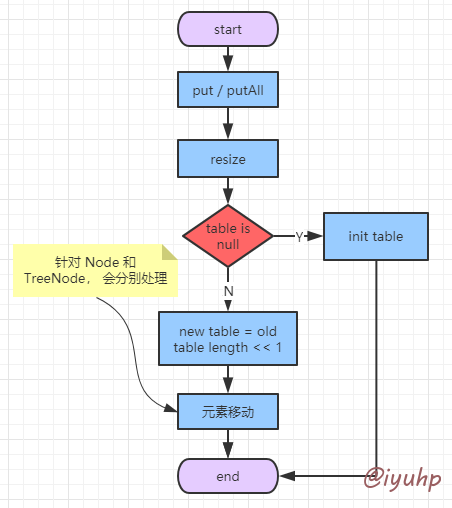
当我们执行 put 操作时, HashMap 会先将元素添加到 Map 中,然后查看 size(即 Map 中的元素个数) 是否大于 threshold (阈值, 即上面根据 loadFactory * capacity 即 table.length 算出来的) ,如果大于,就进行扩容,即 resize() 方法。
if (++size > threshold)
resize();
复制代码
resize [3] 时, 首先判断 table 是否初始化,没有则先初始化 table ,然后根据 old table 以及初始化时的 loadFactor ,threshold 参数,计算新的 threshold ,以及需要扩容的大小,一般为 old table length 的 两倍 。
介绍数组时,我们已经说过,数组无法扩容,而 HashMap 是用数组来维护 hash 表的,所以需要新建一个数组,这个数组的长度就是之前数组的 两倍 。
之后会进行 元素移动 ,为什么说创建 HashMap 时,要先规划好大小,因为扩容这个操作是很消耗性能的,在一个 double for 循环中(for + while) 。
元素移动完毕后,扩容结束。
Queue
队列,FIFO, first in first out, 先进先出。
java 中 Queue 实现 Collection 接口。具体的实现有
Deque deque = new LinkedList();
队列常用方法:
-
add :添加节点,加入队列尾部, tail
-
remove :删除头节点, head
-
peek :获取 head 节点,但是不删除 , 偷取元素
-
poll :获取 head 节点,并删除
-
offer :立即插入节点到 tail , 对于定长队列,有空间且插入成功则返回 true , 若插入失败,则返回 false 。add 会抛出异常。
-
push : Deque 接口所有,插入元素到 head 。
-
take : BlockingQueue 接口所有 ,获取并删除 head 节点。 如果当前 queue 没有元素,则会阻塞 。
Stack
栈, FILO , first in last out ,先进后出。
- peek : 获取 head ,但不会删除,偷取元素
- pop : 获取 head , 同时删除, 弹出元素
- push : 压入栈
注释
[1]
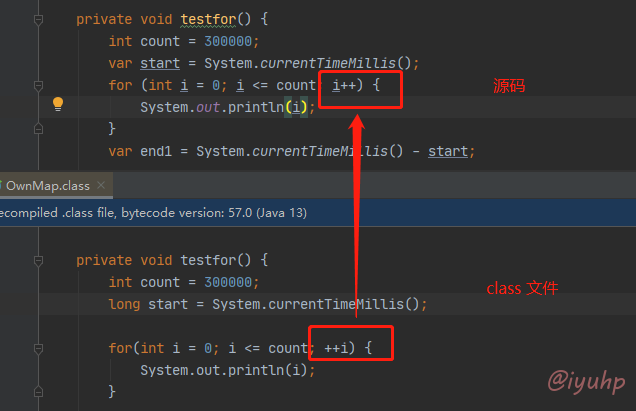
看 HashMap 源码的时候,发现在 resize 时,对 for i 循环的时候,都是用 for(;;++1) 的写法:
for (int j = 0; j < oldCap; ++j) { ... }
复制代码
平时不都是 fro(;;i++) 的吗?然后想了下, i++ 会产生一个中间变量,用于暂时寄存自增前的变量,这一步会消耗一定的性能。
当然,平时我们写代码,最后编译的时候,编译器会把这部分优化成 ++i
[2]
HashMap 初始化时(带 capacity 参数),我们跟踪下代码,就会发现,最终调用:
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// Integer.numberOfLeadingZeros
public static int numberOfLeadingZeros(int i) {
if (i <= 0)
return i == 0 ? 32 : 0;
int n = 31;
if (i >= 1 << 16) { n -= 16; i >>>= 16; }
if (i >= 1 << 8) { n -= 8; i >>>= 8; }
if (i >= 1 << 4) { n -= 4; i >>>= 4; }
if (i >= 1 << 2) { n -= 2; i >>>= 2; }
return n - (i >>> 1);
}
复制代码
这个方法在干嘛呢?
我们知道, java 是通过 补码 计数的。
原码: 原码很好理解,就是一个数的二进制表示, 对于一个四位数,则 2 的原码为 0010, -2 为 1010
反码: 对于正数而言,其原码 = 反码, 对于负数而言,则只需要将其原码除符号位以外的数取反即可。同样对于四位数,2 为 0010 , -2 为 1101
补码: 对于正数而言, 其原码 = 补码,对于负数而言,则是将其反码 + 1 。 还是对于四位数, 2 为 0010 , -2 则为 1110
溢出: java 中,我们偶尔会碰到溢出 。我们知道, java 的基本数据类型中, 如 byte ,长度是一个字节,也就是 8 位,范围是 -128 ~ 127 。 1111 1111 = 255 啊! 为什么最大是 127 呢? 因为他们都是有符号数据类型(最高位 0 表示正数, 1 表示负数),最高位是符号位, 所以 1111 1111 事实上应该是 -1
当我们计算两个 byte 类型的 如 127 + 127 时,输出了 -2 。因为 0111 1111 + 0111 1111 = 1111 1110 , 对于 byte 类型,最高位符号位变成了 1 。这个二进制补码还原成十进制,就是 -2 。
关于补码的更多介绍,可参考 这里
现在回到代码。
numberOfLeadingZeros 这个方法,java init 是一个 32 位数,我们假设 i > 1<< 16 , 这表明 i 的高 16 位中,至少有一个 1 , 所以将 n (从左往右,连续的 0 的个数) - 16 ,即低 16 位可以不考虑了。
然后将 i 无符号右移(感觉这里 >> 和 >>> 都一样,因为负数已经在第一步就 return 掉了) 16 位 , 继续判断,直到最后。假设 i = 0011 , 则最后变成 : 31 - (0011 >>> 1) = 31 - 0001 = 30 。
取得这个数后,对 -1 做无符号右移, -1 是 ffff ffff , 右移 n 位后, 再加上 1,可保证得到一个 cap 向上的 2 的次幂。
至于为什么 HashMap 的 capacity 一定要是 2 次幂, 这就要说到它的 hash 算法了:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
可以看到, 这里将 key 的 hashcode 低 32 位和高 32 位做亦或运算 。
if ((p = tab[i = (n - 1) & hash]) == null) {
tab[i] = newNode(hash, key, value, null);
}
复制代码
放 node 时, index 是根据 (n-1) & hash 来运算的。
因为 n 是一个 2 次幂 ,所以 n-1 是一个全 f 的数, 对 hash 做与运算,即拿到 hash 的低位。
如, HashMap capacity = 8 ,即 n = 8 ,则 n-1 = 0000 0111 假设 key 的 hash 为 0111 0010 , 则 (n-1) & hash = 0000 0010 = 2,会被放入 tab[2] 中。
这样有什么问题呢? 即每次都只有 key 的低位参与了运算,会导致较大概率的 hash 碰撞。
所以 HashMap 的 hash 算法,将其 hash 的低 16 位和高 16 位做了亦或,保证数据的更大的随机性,从而减小 hash 碰撞的可能性。
同时,全程的位操作,也给计算带来了性能上的优势。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

