对于JDBC的一些总结
JDBC
概述
在说明JDBC之前首先我们先要说明一下 持久化 概念。 在程序运行过程中我们会产生大量并保存内存,而有些数据是使用比较频繁的并且需要以后还会被使用。假如我们仅仅使用内存存储这些数据,那么程序一旦运行结束这些数据就会丢失,这在电商行业将变得非常恐怖。因此,在业内就出现了 Mysql、ORACLE等这些数据库可以将这些数据持久化在磁盘上并且能够保证在之后使用获取速度足够快。
那么在Java中怎么获取这些数据库中的数据呢? 这就出现JDBC技术, 它提供一系列的接口和类,可以让开发人员能够忽略各个数据库的差异,从而获取数据或者操作数据。
JDBC版本号
- 在Java6开始引入JDBC4.0, 而从JDBC4.0开始拥有一个新的特性- 无需通过Class.forName主动注册驱动就可以自动加载
- Java7开始则使用JDBC4.1
JDBC的API
- JDPC的api被存储在java.sql包。 所以, 请格外注意,若要使用JDBC请引入
java.sql里面的包
JDBC使用
获取数据库连接对象
获取Connection对象
若要获取数据库连接对象,需要经过一系列步骤
① 下载对应数据库的驱动jar包
在这里我们以mysql为例, 下载地址 https://static.runoob.com/dow...
② 注册驱动 ( 当然,JDBC4.0开始可以自动加载驱动,但是,还是建议手动注册以确保以前JDK版本的兼容性 )
Class.forName("com.mysql.cj.jdbc.Driver");
每个数据库的驱动注册都不一样,这里mysql是使用com.mysql.cj.jdbc.Driver。其余的数据库请查询相关文档
③ 通过 DriverManager 获取连接对象
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
我们可以看见获取连接对象的时候,连接字符串为 jdbc:mysql://127.0.0.1:3306/study , 这是JDBC连接MYSQL的固定格式, jdbc:mysql://数据库IP地址/数据库
Connection常用方法
① 获取 Statement 语句对象
Statement statement = conn.createStatement();
② 获取 PreparedStatement 语句对象
conn.prepareStatement("");
PreparedStatement语句对象相比较Statement语句对象而言, 也拥有那一系列操作SQL的方法。 但是, 它可以防止SQL注入,功能更加强大些。
③ 关闭连接
conn.close();
JDBC的DDL操作
当要进行DDL语句操作时, 首先要按照上面步骤获取Connection对象、获取Statement对象等等, 然后, 执行相应的SQL语句就可以啦。 具体可看下面代码实现
// 注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 获取Connection对象
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
// 获取Statement语句对象
Statement statement = conn.createStatement();
// 执行SQL语句, executeUpdate可以执行DML语句,也可以执行DDL语句
int row = statement.executeUpdate("CREATE TABLE `study`.`JDBC_DEMO` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT /"主键/", `name` VARCHAR(110) NOT NULL,PRIMARY KEY(`id`) )");
// 关闭语句对象
statement.close();
// 关闭连接对象
conn.close();
JDBC的DML操作
DML操作就是我们日常说的增、删、改操作。 其使用步骤和上面的DDL操作类似,区别在于SQL语句变化了。如下
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
Statement statement = conn.createStatement();
// 从这里我们可以看出, 就是SQL语句转变为 INSERT 语句啦
int row = statement.executeUpdate("INSERT INTO `JDBC_DEMO`(id, name) VALUES(2, 'xiaoming')");
if (row > 0) {
System.out.println("操作成功");
}
statement.close();
conn.close();
同理, 修改、删除操作就修改成相应的SQL语句即可
JDBC的DQL操作
ResultSet
互联网上大多数时候都是读多写少,因此, DQL操作需要格外留意一下。 对于DQL操作之前首先我们要认识一下 ResultSet 。
ResultSet 是我们在执行查询操作时返回的对于数据结果集的数据表封装,我们可以通过相应的方法来获取结果集中的数据。
获取结果集
ResultSet set = statement.executeQuery("SELECT * FROM JDBC_DEMO");
常用方法
① next
用来判断结果集中是否存在元素; 若有则返回true并且指针移动到下一个位置
set.next()
② close
关闭结果集
③ 类似 getXxx 方法,可以根据索引或者列名获取数据并转换成相应的数据类型
// 从结果集中获取当前指针的第一列数据, 该方式由于是根据索引去获取列数据,这可能会带来一定的风险。因此,假如日后列的索引位置发生了改变则代表所有相关代码都要修改一遍 set.getInt(1)
// 这种方式就比较好,通过索引名称来获取当前行对应列的数据,在这里Xxx是String则代表获取数据后需将其转换为String类型并返回
set.getString("name")
类似, 也存在 set.getObject(columnIndex) 、 set.getObject(columnLabel) 这样的方法,这种形式就是获取数据的类似都是Object类型,因此,需要我们主动去转换类型
DQL具体操作
在上面我们介绍了 ResultSet ,那么其实我们基本也介绍了DQL操作的基本方法,完整代码如下
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
Statement statement = conn.createStatement();
// 执行Select语句获取结果集,并通过next、getXxx方法获取相应数据
ResultSet set = statement.executeQuery("SELECT * FROM JDBC_DEMO");
while (set.next()) {
System.out.printf("id:%d name:%s", set.getInt("id"), set.getString("name"));
}
set.close();
statement.close();
conn.close();
PreparedStatement
什么是PreparedStatement
在上面我们已经说过了使用 statement 对象来进行数据库的DDL、DML、DQL等操作,但是,它主要是用来操作静态SQL。 这里我们要介绍一下 PreparedStatement 。
PreparedStatement 是可以将 预编译 的SQL存储起来的对象, 它可以高效地执行SQL并能够被传入不同参数多次调用。 它主要有以下特点
- 由于存储的是预编译的SQL,它的参数可以被很好地维护起来并按照一定规则去生成SQL调用
- 能够防止SQL注入
- 依靠
预编译特性可以极大地提高性能,不过,这在ORACLE是有效的,但是在MYSQL是不支持的
注意, 预编译SQL不是真实的SQL,而是含有占位符的SQL
关于为啥预编译会提高性能?
正常情况下 当我们使用客户端去访问ORACLE服务器并发送SQL语句,会经历 安全性检查、语义分析、语法编译、执行计划、返回结果等阶段。 而使用预编译后会将预编译SQL放入一块预编译池中,当下次有同样预编译SQL传入的时候就直接从预编译池捞回来并执行计划就可以了, 这样由于减少很多检查从而提高性能。
DDL、DML、DQL
使用步骤其实是和 Statement 对象是类似的, 首先是准备步骤
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
① DDL
PreparedStatement statement = conn.prepareStatement("CREATE TABLE JDBC_DEMO2(id int(11) NOT NULL AUTO_INCREMENT, name2 varchar(255) NOT NULL,PRIMARY KEY(`id`))");
② DML
生成 PreparedStatement 对象
PreparedStatement statement = conn.prepareStatement("INSERT INTO JDBC_DEMO(id,name) VALUES(?,?)");
设置SQL参数
// 根据索引设置对应位置的值 statement.setInt(1, 3); statement.setString(2, "xiaofeng")
执行更新
// 执行更新,这里我们与Statement对象比较可以发现,此时executeUpdate是无参的 statement.executeUpdate();
完整示例代码如下
Class.forName("com.mysql.cj.jdbc.Driver");
try (
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
PreparedStatement statement = conn.prepareStatement("INSERT INTO JDBC_DEMO(id,name) VALUES(?,?)");
){
statement.setInt(1, 3);
statement.setString(2, "xiaofeng");
statement.executeUpdate();
}catch(Exception e) {
e.printStackTrace();
}
③ DQL
生成 PreparedStatement 对象
PreparedStatement statement = conn.prepareStatement("select id,name from JDBC_DEMO where id = ?");
设置SQL参数
statement.setInt(1, 3);
执行查询
// 这里也要注意,执行的executeQuery是无参的饿 ResultSet set = statement.executeQuery();
完整代码示例
Class.forName("com.mysql.cj.jdbc.Driver");
try (
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
PreparedStatement statement = conn.prepareStatement("select id,name from JDBC_DEMO where id = ?");
){
statement.setInt(1, 3);
ResultSet set = statement.executeQuery();
if (set.next()) {
System.out.printf("id:%d name:%s/n", set.getInt("id"), set.getString("name"));
}
}catch(Exception e) {
e.printStackTrace();
}
当然,上面代码是查询单条数据, 多条数据同理获取即可。
事务
事务 是关系型数据库的一个重要特性,它的特点总结为 ACID
A (Atomicity)
原子性: 事务中的全部操作要么都成功,要么都失败
C (Consistency)
一致性: 事务必须使数据库从一个一致性状态转变为另一个一致性状态
I (Isolation)
隔离性: 多个事务之间是相互隔离的,一个事务的操作是不影响另外一个事务的操作的
D (Durability)
持久性: 事务一旦提交,它对数据库中数据的改变是永久性的
事务使用
① 开始事务
conn.setAutoCommit(false);
② 回滚事务
conn.rollback();
③ 提交事务
conn.commit();
批量操作
① 为啥使用批量操作?
正常情况我们是使用上面那种方式一个个去执行SQL, 这种方式是允许的。但是, 若是有很多类似的SQL, 例如 INSERT INTO JDBC_DEMO(id,name) VALUES (3, "xiaoming") 、 INSERT INTO JDBC_DEMO(id,name) VALUES (3, "xiaofeng") . . . , 假如我们也一个个执行SQL的话, 首先发送每一条SQL都有大量的网络耗时,而且可以看出其实这些SQL是很相似的。 那么这个时候就需要使用 批量操作 ,将这些SQL一次性传入数据库服务器来提高性能。
② 批量操作使用
-
Statement对象执行批量操作// 创建Statement对象 Statement statement = conn.createStatement(); // 批量添加SQL statement.addBatch("INSERT INTO JDBC_DEMO(id,name) VALUES(4, 'xiaoheng')"); statement.addBatch("INSERT INTO JDBC_DEMO(id,name) VALUES(5, 'xiaoyu')"); // 执行SQL statement.executeBatch(); -
PreparedStatement对象执行批量操作// 创建PreparedStatement对象 PreparedStatement statement = conn.prepareStatement("INSERT INTO JDBC_DEMO(id,name) VALUES(?,?)"); // 绑定参数 statement.setInt(1, 6); statement.setString(2, "xiaoxiao"); // 添加批次 statement.addBatch(); // 绑定参数 statement.setInt(1, 7); statement.setString(2, "xiaoaa"); // 添加批次 statement.addBatch() // 执行SQL statement.executeBatch()
③ 注意
-
ORACLE是支持批量操作的, 而MYSQL是不支持批量操作的 -
MySql的JDBC驱动,不是真正支持批量操作的,就算你在代码中调用了批量操作的方法,MySql的JDBC驱动也是按照一般操作来处理的。但是, 在 MYSQL JDBC驱动版本5.1.13之后可以通过添加rewriteBatchedStatements来提高一下// 添加rewriteBatchedStatements参数 Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP地址:3306/数据库?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
获取自动生成主键
① 为什么要获取自动生成的主键
因为在某些场景需要我们获取到生成的主键,从而与另外一张表进行关联起来。比如,我们有下面的表结构
user 用户表
| id | name |
|---|---|
| 1 | xiaoming |
| 2 | xiaofeng |
integral 积分表
| id | value | user_id |
|---|---|---|
| 1 | 23 | 1 |
这个时候我们需要在插入一条 user 记录的时候,同时,也对应插入一条 integral 记录。 这个时候就需要用到 获取自动生成主键 的技巧了, 因为 integral 表中需要插入 user_Id (即user的主键ID)
② 获取主键
-
Statement对象获取主键Statement statement = conn.createStatement();
statement.executeUpdate("INSERT INTO JDBC_DEMO(name) VALUES('ff')", Statement.RETURN_GENERATED_KEYS); // 获取生成的结果集对象 ResultSet set = statement.getGeneratedKeys(); if (set.next()) { // 获取主键 System.out.println(set.getLong(1)); } -
PreparedStatement对象获取主键// 生成PreparedStatement对象需要加 Statement.RETURN_GENERATED_KEYS 参数 PreparedStatement statement = conn.prepareStatement("INSERT INTO JDBC_DEMO(id,name) VALUES(?,?)", Statement.RETURN_GENERATED_KEYS);statement.setInt(1, 23); statement.setString(2, "kkk"); statement.executeUpdate(); // 获取生成的结果集对象 ResultSet set = statement.getGeneratedKeys(); if (set.next()) { // 获取主键 System.out.println(set.getLong(1)); }
连接池
为什么要使用连接池
在正常情况我们每一次连接数据库的时候都需要建立连接并发送SQL语句, 而每一次建立连接的时间都需要耗费时间,可以想象假如现在有大量用户访问服务器的话会频繁产生大量的数据库连接, 这对于底层数据库的压力将非常大,严重情况下甚至可以导致数据库宕机。
因此, 为什么不将现有已经建立起来的连接对象缓存起来,当我们要使用的时候从连接池获取出来,这样就会减少每次连接数据库带来的开销,而这就是 连接池 概念的出现。
连接池概述
① 简介
在上面我们已经叙述了为啥要使用连接池,因此, Java就提供了一个 javax.sql.DataSource 接口。 要求各大数据库厂商遵循该接口并提供驱动jar包。
② 分类
目前实现 DataSource 接口主要有以下几种:
- C3P0 (Hibernate推荐) 性能极差,不推荐使用
- DBCP (Spring推荐) 纯粹一个连接池组件,性能还可以
- Druid (阿里巴巴出品) 目前来说可称之为宇宙第一强数据库连接池,不仅仅拥有基本连接池功能,而且自带监控等功能。(强烈推荐)
DBCP连接池(Spring推荐)
使用连接池主要是要获取到 DataSource 对象,通过它我们就可以从连接池中获取到 Connection 对象。具体使用步骤如下
① 下载jar包
http://commons.apache.org/pro... dbcp包
https://mirror.bit.edu.cn/apa... pool包
② 将上面两个包 Build Path 到 Java 路径
③ 得到 DataSource 并获取 Connection 对象
-
直接硬编码获取
// 获取DataSource BasicDataSource dataSource = new BasicDataSource(); dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver"); dataSource.setUrl("jdbc:mysql://数据库IP地址:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC"); dataSource.setUsername("用户名"); dataSource.setPassword("密码");// 获取Connection对象 Connection conn = dataSource.getConnection();
-
从properties文件加载并获取
Connection// 加载properties资源文件 ClassLoader loader = Thread.currentThread().getContextClassLoader(); InputStream in = loader.getResourceAsStream("dbcp.properties"); Properties p = new Properties(); p.load(in);// 获取DataSource对象 BasicDataSource dataSource = BasicDataSourceFactory.createDataSource(p);
Connection conn = dataSource.getConnection();
Druid连接池(阿里巴巴出品)
① 下载jar包
https://github.com/alibaba/dr... druid包
② 将jar包进行 Build Path
③ 得到 DataSource 并获取 Connection 对象
-
直接硬编码获取
DruidDataSource dataSource = new DruidDataSource(); dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver"); dataSource.setUrl("jdbc:mysql://数据库IP地址:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC"); dataSource.setUsername("用户名"); dataSource.setPassword("密码");Connection conn = dataSource.getConnection();
-
从properties文件加载并获取
Connection// 加载properties资源文件 ClassLoader loader = Thread.currentThread().getContextClassLoader(); InputStream in = loader.getResourceAsStream("dbcp.properties"); Properties p = new Properties(); p.load(in);DruidDataSource dataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(p);
Connection conn = dataSource.getConnection();
JDBCTemplate
JDBCTemplate是对于JDBC的一种封装技巧, 能够让我们更好地使用JDBC, 接下来让我们体验一下这段重构历程吧。
原始JDBC使用
在上古时代我们在使用如下方式去使用 JDBC
package com.fengyuxiang.sims.dao.impl;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.omg.PortableInterceptor.Interceptor;
import com.fengyuxiang.sims.dao.IStudentDAO;
import com.fengyuxiang.sims.domain.Student;
import com.fengyuxiang.template.JdbcTemplate;
public class StudentDAOImpl implements IStudentDAO {
private Statement statement;
public void setStatement(Statement statement) {
this.statement = statement;
}
public int save(Student stu) {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection("jdbc:mysql://数据库IP:3306/study?rewriteBatchedStatements=true&useSSL=false&serverTimezone=UTC", "用户名", "密码");
Statement statement = conn.createStatement();
// 从这里我们可以看出, 就是SQL语句转变为 INSERT 语句啦
int row = statement.executeUpdate("INSERT INTO `Student`(id, name) VALUES(2, 'xiaoming')");
if (row > 0) {
System.out.println("操作成功");
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
try {
if (statement != null) {
statement.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
可以想想在进行更新、删除、查询等操作都会很多这样重复的代码, 仔细想想 其实上面除了SQL不一样之外,其余都很类似。 所以我们首先进行第一轮改造,抽象出 JdbcUtil 工具类
JdbcUtil
JdbcUtil 工具类是将JDBC的一些常见操作封装起来然后提供给外界使用,让我们看一下下面的代码
package com.fengyuxiang.utils;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class JdbcUtil {
private static DruidDataSource dataSource = null;
// 静态代码块,会在类加载进JVM时被调用
static {
// 通过类加载器获取资源文件 dbcp.properties
ClassLoader loader = Thread.currentThread().getContextClassLoader();
InputStream inStream = loader.getResourceAsStream("dbcp.properties");
Properties p = new Properties();
try {
p.load(inStream);
// 通过Druid连接池获取DataSource对象
dataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(p);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
// 获取Connection对象
public static Connection getConn() throws SQLException {
Connection conn = null;
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
throw e;
}
return conn;
}
// 关闭资源
public static void close(Connection conn, Statement statement, ResultSet set) {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
try {
if (statement != null) {
statement.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
try {
if (set != null) {
set.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
通过上面代码后,对于关闭连接、获得连接等一系列操作直接通过 JdbcUtil 操作即可,让我们看一下使用 JdbcUtil 工具类简化后的代码
package com.fengyuxiang.sims.dao.impl;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.omg.PortableInterceptor.Interceptor;
import com.fengyuxiang.sims.dao.IStudentDAO;
import com.fengyuxiang.sims.domain.Student;
import com.fengyuxiang.template.JdbcTemplate;
import com.fengyuxiang.utils.JdbcUtil;
public class StudentDAOImpl implements IStudentDAO {
private Statement statement;
public void setStatement(Statement statement) {
this.statement = statement;
}
public int save(Student stu) {
// 通过JdbcUtil工具类获取Connection对象
Connection conn = JdbcUtil.getConn();
// 获取Statement对象
Statement statement = conn.createStatement();
int row = statement.executeUpdate("INSERT INTO `Student`(id, name) VALUES(2, 'xiaoming')");
if (row > 0) {
System.out.println("操作成功");
}
// 关闭资源
JdbcUtil.close(conn, statement, null);
}
}
通过这一步我们代码看上去是不是清爽许多了呀。但是, 问题又再次来到我们的面前。我们通过对于上述代码分析可以发现一些有趣的现象,除了SQL不一样外其余JDBC代码很相似。所以,接下来就让我们继续重构上面的代码,这就引出来 JdbcTemplate 类通过它来封装那些重复的SQL操作。
JdbcTemplate的出现
JdbcTemplate出现是为了解决 JDBC 代码重复的问题,最终我们期望是只要调用 JdbcTemplate 然后传入 SQL 语句可以直接操作数据库。所以,让我们看看写的 JdbcTemplate 类
package com.fengyuxiang.template;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import com.fengyuxiang.sims.domain.Student;
import com.fengyuxiang.utils.JdbcUtil;
public class JdbcTemplate {
public static int update(String sql, Object...params) throws SQLException {
Connection conn = JdbcUtil.getConn();
// 传入SQL并生成PreparedStatement对象
PreparedStatement statement = conn.prepareStatement(sql);
int paramLen = params.length;
for (int index = 0; index < paramLen; ++index) {
statement.setObject(index+1, params[index]);
}
// 执行更新
int row = statement.executeUpdate();
// 关闭
JdbcUtil.close(conn, statement, null);
return row;
}
public static List query(String sql, Object ...params) throws SQLException {
Connection conn = JdbcUtil.getConn();
PreparedStatement statement = conn.prepareStatement(sql);
int paramLen = params.length;
for (int index = 0; index < paramLen; ++index) {
statement.setObject(index+1, params[index]);
}
ArrayList<Student> list = new ArrayList<>();
// 执行查询
ResultSet set = statement.executeQuery();
while(set.next()) {
Student stu = new Student();
stu.setId(set.getInt("id"));
stu.setName(set.getString("name"));
list.add(stu);
}
// 关闭
JdbcUtil.close(conn, statement, set);
return list;
}
}
通过这一步的话,我们只要将SQL语句传入 JdbcTemplate 就可以直接操作数据库。如下
package com.fengyuxiang.sims.dao.impl;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.omg.PortableInterceptor.Interceptor;
import com.fengyuxiang.sims.dao.IStudentDAO;
import com.fengyuxiang.sims.domain.Student;
import com.fengyuxiang.template.JdbcTemplate;
import com.fengyuxiang.utils.JdbcUtil;
import com.fengyuxiang.template.JdbcTemplate;
public class StudentDAOImpl implements IStudentDAO {
private Statement statement;
public void setStatement(Statement statement) {
this.statement = statement;
}
public int save(Student stu) {
int row = 0;
try {
// 之前上面一大串复杂的JDBC代码,在这里只需要通过JdbcTemplate并执行一条SQL语句可以全部完成了,大家可以将这段代码和我们之前代码对比一样就看出其简洁性
row = JdbcTemplate.update("INSERT INTO Student(id,name) VALUES (?,?) ", stu.getId(), stu.getName());
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return row;
}
}
不过,尽管如此还是有一点美中不足就是在上面 JdbcTemplate 进行 DQL 语句操作时候,对应的 domain 对象是固定的,比如上面就只能操作 Student 对象。这样就显得 JdbcTemplate 操作范围特别有限,我们总不能对于每个不同的 domain 对象都写一个方法来解析吧。 所以, 这里我们就要重构这一部分,让JdbcTemplate显得通用些
JdbcTemplate进阶- 通用结果集的出现
通用结果集的出现主要是为了适应不同的 DAO 的查询,通过一个方法就可以获取不同的数据结果。在这里就需要使用到泛型以及 JavaBean 的知识了。
① 定义一个结果集接口
package com.fengyuxiang.sims.dao;
import java.sql.ResultSet;
public interface IResultSetHandle<T> {
<T> T handle(ResultSet set);
}
② 实现 IResultSetHandle 接口,这里指处理单行记录
package com.fengyuxiang.sims.dao.impl;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.omg.PortableInterceptor.Interceptor;
import com.fengyuxiang.sims.dao.IResultSetHandle;
public class ResultSetHandle<T> implements IResultSetHandle<T> {
// 待组装domain元素的Class对象
private Class classType;
ResultSetHandle(Class classType) {
this.classType = classType;
}
@Override
public <T> T handle(ResultSet set) {
try {
// 利用反射实例化对象
Object obj = this.classType.newInstance();
// 获取JavaBean
BeanInfo beanInfo = Introspector.getBeanInfo(this.classType, Object.class);
// 获取属性描述符
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
if (set.next()) {
for (PropertyDescriptor propertyDescriptor : propertyDescriptors) {
// 获取属性值
String propertyName = propertyDescriptor.getName();
// 获取属性对应的setter方法
Method writeMethod = propertyDescriptor.getWriteMethod();
// 调用属性的setter方法以及结果集的getObject,进行值注入
writeMethod.invoke(obj, set.getObject(propertyName));
}
}
// 通过上面的方式,我们就可以传入的class对象实例化并进行返回
return (T) obj;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IntrospectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
}
② 实现 IResultSetHandle 接口,这里指处理多行记录
package com.fengyuxiang.sims.dao.impl;
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import com.fengyuxiang.sims.dao.IResultSetHandle;
public class ResultSetListHandle<T> implements IResultSetHandle<List<T>> {
// 待组装domain元素的Class对象
private Class<T> classType;
public ResultSetListHandle(Class<T> classType) {
// TODO Auto-generated constructor stub
this.classType = classType;
}
@Override
public List<T> handle(ResultSet set) {
// TODO Auto-generated method stub
try {
// 创建一个ArrayList集合用来装T类型的对象
ArrayList<T> list = new ArrayList<>();
while(set.next()) {
// 实例化对象
T obj = this.classType.newInstance();
// 根据class对象获取bean信息
BeanInfo beanInfo = Introspector.getBeanInfo(this.classType, Object.class);
// 获取JavaBean的属性描述符
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor propertyDescriptor : propertyDescriptors) {
// 获取属性名称
String propertyName = propertyDescriptor.getName();
// 获取属性的stter方法
Method method = propertyDescriptor.getWriteMethod();
// 调用属性的setter方法以及结果集的getObject,进行值注入
method.invoke(obj, set.getObject(propertyName));
}
// 将组装好的obj对象,放入到list集合里面并返回
list.add(obj);
}
return list;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IntrospectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
}
通过上面三步我们就实现一套代码能够处理不同domain对象结果集的情况。 首先让我们看一下没有使用通用结果集下的DQL语句
public static List query(String sql, Object ...params) throws SQLException {
Connection conn = JdbcUtil.getConn();
PreparedStatement statement = conn.prepareStatement(sql);
int paramLen = params.length;
for (int index = 0; index < paramLen; ++index) {
statement.setObject(index+1, params[index]);
}
ArrayList<Student> list = new ArrayList<>();
// 执行查询
ResultSet set = statement.executeQuery();
while(set.next()) {
// 只能处理固定的domain对象
Student stu = new Student();
stu.setId(set.getInt("id"));
stu.setName(set.getString("name"));
list.add(stu);
}
// 关闭
JdbcUtil.close(conn, statement, set);
return list;
}
而使用结果集的DQL语句
public static <T> T query(String sql, IResultSetHandle<T> handler, Object ...params) throws SQLException {
Connection conn = JdbcUtil.getConn();
PreparedStatement statement = conn.prepareStatement(sql);
int paramLen = params.length;
for (int index = 0; index < paramLen; ++index) {
statement.setObject(index+1, params[index]);
}
ResultSet set = statement.executeQuery();
T list = handler.handle(set);
JdbcUtil.close(conn, statement, set);
return list;
}
当我们使用的时候就就可以这样使用
// 这里我们就可以处理Student类型对象
Student stu = JdbcTemplate.queryOne("SELECT * FROM Student WHERE ID = ? LIMIT 1", new ResultSetHandle<Student>(Student.class), id);
// 这里我们就可以处理Order类型对象
Order stu = JdbcTemplate.queryOne("SELECT * FROM Student WHERE ID = ? LIMIT 1", new ResultSetHandle<Order>(Order.class), id);
// 这里我们就可以处理Good类型对象
Good stu = JdbcTemplate.queryOne("SELECT * FROM Student WHERE ID = ? LIMIT 1", new ResultSetHandle<Good>(Good.class), id);
....
可以看出来, 通过一套代码我们就能够操作不同的domain对象并返回,而且代码看来显得更加优雅。
DAO
DAO出现背景
在我们没有没有DAO的时候,如果我们需要查询数据的时候, 那么在项目上我们将大量使用如下代码:
位置1
ResultSet set = statement.executeQuery("SELECT * FROM JDBC_DEMO");
while (set.next()) {
System.out.printf("id:%d name:%s", set.getInt("id"), set.getString("name"));
}
位置2
ResultSet set = statement.executeQuery("SELECT name FROM JDBC_DEMO");
while (set.next()) {
System.out.printf("id:%d name:%s", set.getInt("id"), set.getString("name"));
}
....
可以想象随着项目业务渐渐庞大,类似这些的代码将会越来越多。假如有一天产品经理跑来跟你说 需求发生变化了, 这个时候你不得不将这些代码再改造一遍, 这感觉会疯的。
那么是否可以将那些类似的、重复的代码封装起来一个类,然后我们通过该类来统一访问数据库呢? 答案是yes。 而这个类就是 DAO
什么是DAO
DAO 其实是基于JDBC对相关的、重复的业务的再一次封装, 它提供 统一访问数据库 的接口规范以及实现类。
DAO设计规范
若是我们要设计 DAO 需要遵循一些规范,遵循规范便于程序员之间沟通交流。假设现在我们设计一个 Student 的 DAO
① 包规范
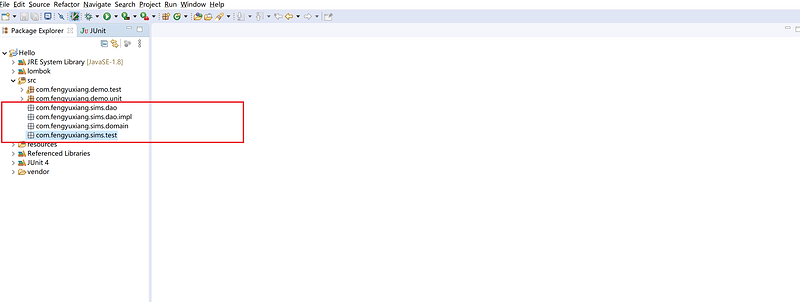
com.fengyuxiang.sims.dao : 代表DAO的接口
com.fengyuxiang.sims.dao.impl : 代表DAO的接口实现
com.fengyuxiang.sims.domain : 代表数据模型,用来描述对象的
com.fengyuxiang.sims.test : 一些相关的测试类
② 起名规范
DAO接口: 接口起名使用 IXxxDAO/IXxxDao 比如: IStudentDAO、IStudentDao
DAO实现类: 使用 XxxDAOImpl/XxxDaoImpl 比如: StudentDAOImpl 、StudentDaoImpl
DAO测试类: 使用XxxDAOTest/XxxDaoTest 比如: StudentDAOTest、StudentDaoTest
③ 对象起名规范
IStudentDAO studentDAO = new StudentDAOImpl();
正文到此结束
- 本文标签: value ArrayList db druid 压力 dataSource IDE ACE 解析 IO 服务器 开发 JDBC https 阿里巴巴 src 代码 kk spring key 索引 tab 数据库 C3P0 stream 数据 Word 程序员 自动生成 rewrite 参数 连接池 git cat lib GitHub autocommit mysql 实例 一致性 测试 Oracle DBCP 缓存 UI 删除 CTO bean apache REST 类加载器 struct UTC 产品 build API 下载 Select 模型 编译 tar 总结 ResultSet sql http 时间 Property update list JVM ip 并发 互联网 Connection 大数据 数据模型 DOM id ssl final Statement 安全 DDL 需求 Atom java
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

