LinkedHashMap部分源码分析
在Jdk源码中可以看到,LinkedHashMap本身的方法并不多,大多数都是父类HashMap所提供的方法,在HashMap底层基础数据结构是哈希桶实现,为此在LinkedHashMap中也是通过一个Entry<K,V>对象实现,但是在这个对象中增加了二个属性,before指向前一个Entry对象,after指向后一个Entry对象,通过这二个属性维护一条双向链表,从而可以达到顺序遍历与顺序保存一致性,同时LinkedHashMap对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存Lru特性就是使用LinkedHashMap实现;其实将HashMap中的思想把握了,对于学习LinkedHashMap的成本就降低很多;
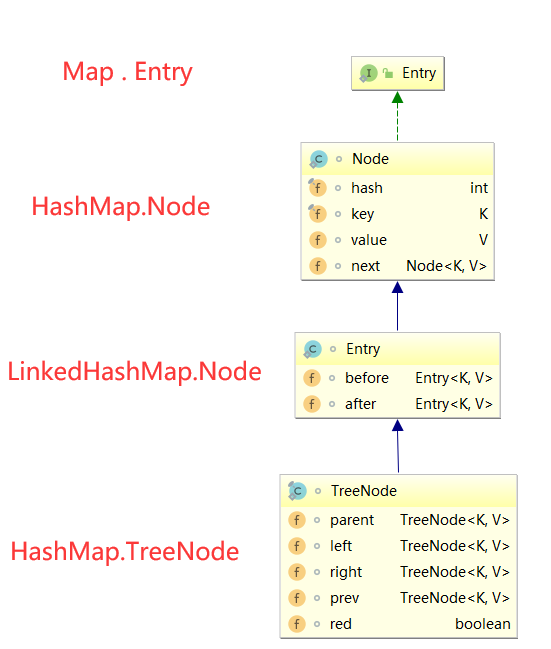
Map实现类中的对象
当你看过一遍Map主要实现类的源码之后,应该会对这几个对象比较熟悉,HashMap 内部类Node实现了内部接口Map.Entry; LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力,至于每一个成员变量的含义在对应的文章中已经说明了;
LinkedHashMap添加元素
下面我们也是像学习HashMap一样的来学习LinkedHashMap,首先我们会惊奇的发现在LinkedHashMap中没有增加对象的方法,那么就看看它的父类HashMap,竟然在LinkedHashMap中重写了newNode,那么LinkedHashMap是如何添加对象,以及最后如何在HashMap的基础上维护一条双向链表?
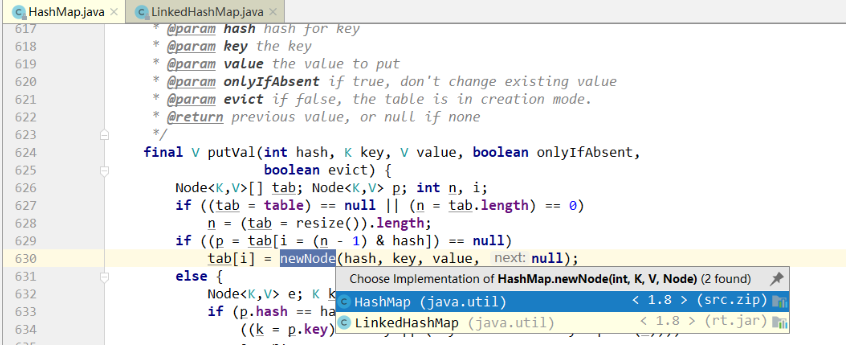
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
//创建对象
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//增加元素
linkNodeLast(p);
return p;
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
//HashMap中Node的构造方法
super(hash, key, value, next);
}
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//定义一个节点指向原LinkedHashMap对象中的尾节点
LinkedHashMap.Entry<K,V> last = tail;
//传入的对象指向最后一个节点
tail = p;
//如果没有尾节点,证明是一个新的LinkedHashMap对象,就直接给头节点指向传入的对象
if (last == null)
head = p;
//尾插法,类似于LinkedList
else {
//传入对象的前节点指向原对象尾节点
p.before = last;
//原对象的后节点指向传入的对象
last.after = p;
}
}
复制代码
三个代表
不知道大家有没有注意到在HashMap中声明了三个方法,但是这三个方法什么事情都没有做,然后在子类LinkedHashMap中重写了这三个方法,俗话云:父亲开辟了土地,至于是否能收货啥,就看子孙的造化,咱LinkedHashMap虽然很多方法都是使用父类,但是对这三个方法的重写让LinkedHashMap的威力增加了40%,下面我们看看:
在HashMap中存在三个方法
// Callbacks to allow LinkedHashMap post-actions LinkedHashMap的回调函数
void afterNodeAccess(Node<K,V> p) { } //将被访问节点移动到链表最后
void afterNodeInsertion(boolean evict) { } // 根据条件判断是否移除最近最少被访问的节点
void afterNodeRemoval(Node<K,V> p) { } //删除节点,然后实现该节点前后相连
复制代码
afterNodeAccess() 将访问的节点移到最后
void afterNodeAccess(Node<K,V> e) { // move node to last
//定义一个节点
LinkedHashMap.Entry<K,V> last;
//accessOrder为一个成员变量 e不为最后一个节点
if (accessOrder && (last = tail) != e) {
//将传入节点前后节点指向 a b ,待把e移动到尾节点之之后,需要将 a b 互联
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null){
head = a;
}else{
b.after = a;
}
if (a != null){
a.before = b;
}else{
last = b;
}
if (last == null){
head = p;
}else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
复制代码
afterNodeInsertion() 重写方法可以实现删除访问最少的节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//重写此方法可以实现移除访问量少的节点
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
复制代码
afterNodeRemoval() 删除节点
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
复制代码
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

