Mybatis源码之美:3.7.深入了解select元素
mybatis 提供了四种配置映射语句的元素,和 C , R , U , D 四种操作相对应,他们分别是 insert , select , update , delete .
其中配置查询语句的元素 select 是 myabtis 中最常用的元素之一,他负责从数据库中读取数据.
本篇文章我们就来详细的了解一下 select 元素的定义和使用.
通常来说,在使用 mybatis 的过程中,一个 select 元素通常会有一个与之对应的 Mapper 方法配置,但是 Mapper 方法配置并不是必须的,我们可以提供一个单独存在的 select 语句声明,但不为其提供相应的 Mapper 方法.
select 语句声明:
<select id="selectUserById" resultType="org.apache.learning.sql.User">
SELECT
id,name
FROM USER u
WHERE u.id=#{id}
</select>
复制代码
mapper 方法声明:
User selectUserById(Integer id); 复制代码
select元素的属性定义
select 元素具有十五个属性定义,其中部分属性经过前面的学习,我们已经有所了解,但是还有部分属性我们没有接触过.
<!ATTLIST select id CDATA #REQUIRED parameterMap CDATA #IMPLIED parameterType CDATA #IMPLIED resultMap CDATA #IMPLIED resultType CDATA #IMPLIED resultSetType (FORWARD_ONLY | SCROLL_INSENSITIVE | SCROLL_SENSITIVE | DEFAULT) #IMPLIED statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED fetchSize CDATA #IMPLIED timeout CDATA #IMPLIED flushCache (true|false) #IMPLIED useCache (true|false) #IMPLIED databaseId CDATA #IMPLIED lang CDATA #IMPLIED resultOrdered (true|false) #IMPLIED resultSets CDATA #IMPLIED > 复制代码
但是不要紧,现在我们来一一了解这些属性.
id属性
必填的 id 属性是当前 select 元素的唯一标志,在实际使用中,该属性的取值应该与其对应的 mapper 方法(如果存在)定义相匹配:
部分元素可以通过 id 属性来引用当前 selecet 元素.
parameterMap属性
parameterMap 属性用于配置入参映射关系,在文章 Mybatis源码之美:3.4.解析处理parameterMap元素 中,我们详细的解析了这个属性的用法,目前该属性已经被行内参数映射和 parameterType 属性所取代.
parameterType属性
parameterType 属性用于配置当前 select 元素的的入参类型,他的取值是传入这条语句的参数的全限定名称或者别名.
resultMap属性
resultMap 属性用于配置结果映射,在文章 Mybatis源码之美:3.5.6.resultMap元素的解析过程 中,我们已经非常详细的了解了该元素.
resultType属性
resultType 属性用于配置结果映射对象的类型,他的取值是返回对象的全限定名称或者别名.
resultSetType属性
resultSetType 属性用于控制 jdbc 中 ResultSet 对象的行为,他的取值对应着 ResultSetType 枚举对象的实例:
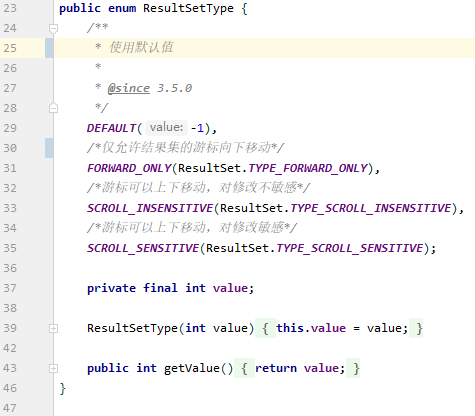
根据 JDBC 规范, Connection 对象创建 Statement 对象时允许传入一个 int 类型的 resultSetType 参数来控制返回的 ResultSet 对象类型.
在 mybatis 中,除了默认值 DEFAULT 之外, resultSetType 还有三个可选的值: FORWARD_ONLY , SCROLL_SENSITIVE 以及 SCROLL_INSENSITIVE .
他们分别对应着 JDBC 规范中的 TYPE_FORWARD_ONLY , TYPE_SCROLL_SENSITIVE 和 TYPE_SCROLL_INSENSITIVE .
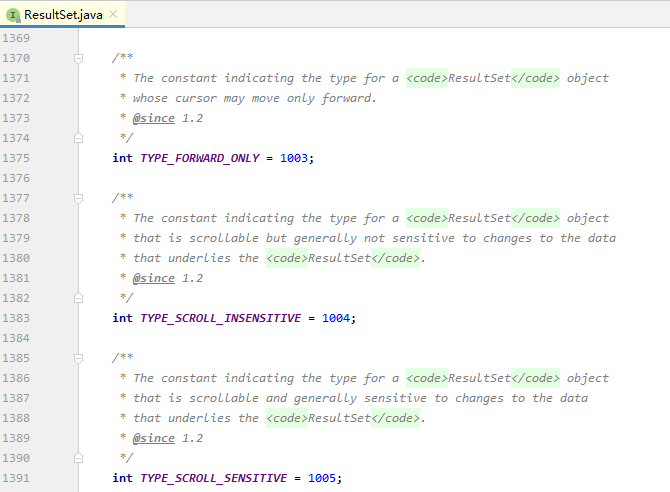
TYPE_FORWARD_ONLY 模式
其中, TYPE_FORWARD_ONLY 模式下的 ResultSet 对象只能前进不能后退,即,在处理结果集时,我们可以由第一行滚动到第二行,但是不能从第二行滚动到第一行.
TYPE_FORWARD_ONLY 模式下的 ResultSet 对象阉割了部分数据访问功能.
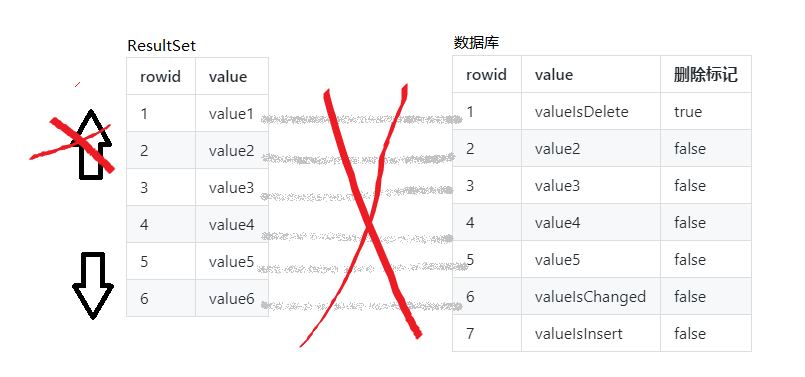
TYPE_SCROLL_INSENSITIVE 模式
TYPE_SCROLL_INSENSITIVE 模式下的 ResultSet 对象不仅可以前进,还可以后退,甚至还能通过相对坐标或者绝对坐标跳转到指定行.
但是 TYPE_SCROLL_INSENSITIVE 模式下的 ResultSet 对象会将数据库查询结果缓存起来,在下次操作时,直接读取缓存中的数据,所以,该模式下的 ResultSet 对象对底层数据的变化不敏感.
因此,如果在读取时,底层数据被其他线程修改, ResultSet 对象依然会读取到之前获取到的数据.
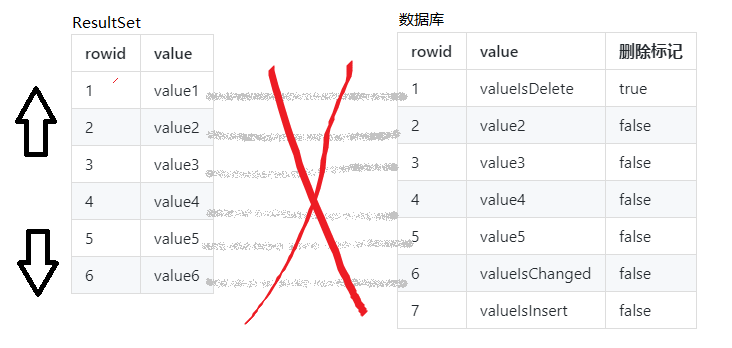
TYPE_SCROLL_SENSITIVE 模式
TYPE_SCROLL_SENSITIVE 模式下的 ResultSet 对象同样可以前进后退,可以跳转到任意行.
但是和 TYPE_SCROLL_INSENSITIVE 模式不同的是, TYPE_SCROLL_SENSITIVE 模式缓存的是数据记录的 rowid ,在下次操作时 ResultSet 会根据缓存的 rowid 重新从数据库读取数据,所以 TYPE_SCROLL_SENSITIVE 模式能够实时感知底层数据的变化.
这里提到的底层的数据变化是指更新操作,不包含删除和新增操作.
因为绝大多数数据库的删除操作都是标记删除,而不是物理删除,因此当数据被删除时,我们依然可以通过被缓存的 rowid 来获取该条数据.
至于新增的数据,因为在查询时没有缓存对应的 rowid ,所以同样不能被感知.

在 JDBC 规范中, resultSetType 的默认取值为 TYPE_FORWARD_ONLY .
我们可以通过 DatabaseMetaData 对象的 supportsResultSetType() 方法来检索当前数据库是否支持给定的结果集类型.
/** * Retrieves whether this database supports the given result set type. * * @param type defined in <code>java.sql.ResultSet</code> * @return <code>true</code> if so; <code>false</code> otherwise * @exception SQLException if a database access error occurs * @see Connection * @since 1.2 */ boolean supportsResultSetType(int type) throws SQLException; 复制代码
Connection 对象的 getMetaData() 方法可以获取 DatabaseMetaData 对象.
statementType属性
select 元素的 statementType 属性用于控制 mybatis 创建 Statement 对象的行为.
public enum StatementType {
STATEMENT/*硬编码*/,
PREPARED/*预声明*/,
CALLABLE/*存储过程*/
}
复制代码
statementType 属性有三个取值: STATEMENT , PREPARED 以及 CALLABLE ,默认值为 PREPARED .
这三个取值分别对应着 JDBC 中 Statement 的三种不同定义:
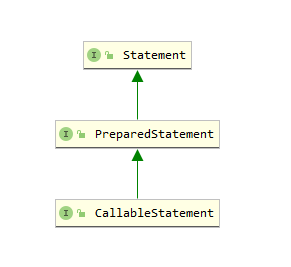
其中 Statement 对象是最基础的定义,他提供了执行语句和获取结果的基本方法,它用于处理普通的静态 sql ,每次执行,数据库都会重新编译对应的 sql 语句,在单次查询中,效率高于 PreparedStatement 对象.
PreparedStatement 对象是 Statement 对象的扩展,他额外提供了处理参数的方法.他一般用于动态 sql 的处理,可以有效的防止 sql 注入, PreparedStatement 对象的 sql 是预编译的,因此在多次执行同 sql 查询时,效率高于 Statement .
CallableStatement 对象扩展了 PreparedStatement ,额外添加了调用存储过程和处理出参的方法.他主要用于调用存储过程.
实际上,在 mybatis 中,定义了 StatementHandler 接口来接管对 Statement 对象的操作:
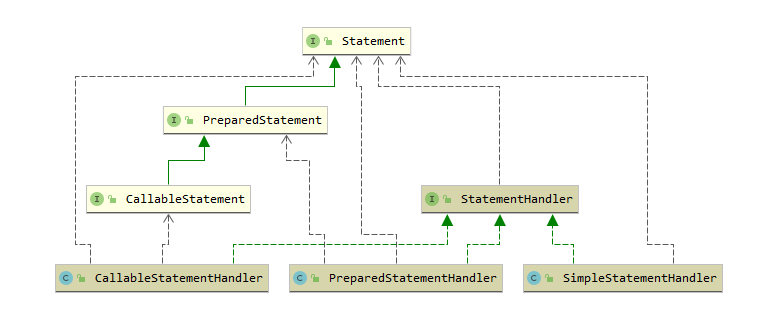
关于 StatementHandler 接口,我们会在后面的文章中进行解析.
fetchSize属性
fetchSize 属性用于控制 JDBC 批量获取数据时,每次加载数据的行数,其默认值为 0 .
// Statement.java
/**
* Gives the JDBC driver a hint as to the number of rows that should
* be fetched from the database when more rows are needed for
* <code>ResultSet</code> objects generated by this <code>Statement</code>.
* If the value specified is zero, then the hint is ignored.
* The default value is zero.
*
* @param rows the number of rows to fetch
* @exception SQLException if a database access error occurs,
* this method is called on a closed <code>Statement</code> or the
* condition {@code rows >= 0} is not satisfied.
* @since 1.2
* @see #getFetchSize
*/
void setFetchSize(int rows) throws SQLException;
复制代码
但是当我们查看与之相对应的 getFetchSize() 方法时:
// Statement.java /** * Retrieves the number of result set rows that is the default * fetch size for <code>ResultSet</code> objects * generated from this <code>Statement</code> object. * If this <code>Statement</code> object has not set * a fetch size by calling the method <code>setFetchSize</code>, * the return value is implementation-specific. * * @return the default fetch size for result sets generated * from this <code>Statement</code> object * @exception SQLException if a database access error occurs or * this method is called on a closed <code>Statement</code> * @since 1.2 * @see #setFetchSize */ int getFetchSize() throws SQLException; 复制代码
我们会发现 fetchSize 取决于具体的数据库驱动,比如: oracle 数据库的默认值为 10 .
我们可以通过调整 fetchSize 的值来控制数据库每次加载的数据量,进而手动控制查询时间和内存空间的阈值.
timeout属性
timeout 属性用于配置 JDBC 中 Statement 对象的请求超时时间,单位:秒.
在未抛出异常的前提下,每次数据操作, jdbc 驱动都会等待指定 timeout 时长.
flushCache和useCache属性
flushCache 和 useCache 两个属性都用于控制 myabtis 的缓存行为.
其中 flushCache 属性用于控制 清除 缓存的行为,当 flushCache 属性为 true 时, mybatis 在执行语句之前将会清除当前语句所匹配的二级缓存和以及所有的一级缓存.
针对 select 类型的语句, flushCache 属性的默认值为 false ,其余类型的语句默认值为 true .
useCache 属性用于控制 mybatis 将 查询语句 的结果写入二级缓存的行为,当 useCache 属性的值为 true 时,当前语句的执行结果将会被存入到二级缓存中.
databaseId属性和lang属性
databaseId 属性用于配置当前 selecet 元素对应的数据库类型.
lang 属性用于指定解析当前 select 元素使用的脚本驱动.
在 Mybatis源码之美:3.6.解析sql代码块 一文中,我们已经对 databaseId 属性和 lang 属性做了一个简单了解.
resultOrdered属性
在 Mybatis源码之美:3.5.4.唯一标标识符--id元素 一文中,我们提供了一个因为错误配置 id 元素导致数据丢失的问题.
在这篇文章中,我们指出: id元素可以通过临时缓存对象来提高在嵌套结果映射中处理数据的性能.
这是一种典型的用空间换时间的解决方案,通过临时缓存, mybatis 提高了对数据的解析速度,但是势必会消耗更多的内存.
当我们执行大数量的操作时,可能就会导致 OOM ( OutOfMemoryError )的发生.
为此, mybatis 为我们提供了一个 resultOrdered 属性.
resultOrdered 属性是一个标志性的属性,用户可以通过配置该属性的值为 true 来告知 mybatis 当前 select 语句的查询结果针对于 <id> 元素的配置是有序的,即,多个相同 <id> 属性是分组且连续的.
比如:
| key | value |
|---|---|
| A | 数据1 |
| A | 数据2 |
| A | 数据3 |
| A | 数据4 |
| B | 数据5 |
| B | 数据6 |
| B | 数据7 |
| B | 数据8 |
这样 mybatis 在解析数据时,根据 <id> 元素的配置最多只会缓存一行数据,降低了内存的使用量,因此降低了 OOM 的发生几率.
针对上面的数据记录来讲, mybatis 在解析 数据1 时,会将 数据1 对应的记录缓存起来,之后的的 数据2 , 数据3 以及 数据4 因为具有相同的 key 值,因此都能命中缓存,避免了重复解析数据.
但是在处理 数据5 时,因为 key 值为 B ,无法命中缓存, 数据1 的缓存将会被移除, 数据5 对应的记录被放入缓存中.
在这种处理方式下,因为相同 Key 值的数据分组在一起,因此效率高的同时还降低了内存的使用.
但是,针对数据记录:
| key | value |
|---|---|
| A | 数据1 |
| B | 数据2 |
| A | 数据3 |
| B | 数据4 |
| A | 数据5 |
| B | 数据6 |
| A | 数据7 |
| B | 数据8 |
具有相同 key 值的数据并没有分组在一起,而是交叉出现,因此虽然 mybatis 在解析 数据1 时,会将 数据1 对应的记录缓存起来,但是因为 数据2 的 key 值为 B ,不能命中缓存,因此 数据1 的缓存将会被移除, 数据2 对应的记录进入缓存.
依次类推,每一条数据记录都不能命中缓存,都需要重新解析.
针对这种场景,虽然降低了内存使用量,但是大大降低了数据解析的效率.
resultSets属性
在文章 Mybatis源码之美:3.5.2.负责一对一映射的association元素和负责一对多映射的collection元素 中我们已经对 select 元素的 resultSets 做了较深入的了解.
这里我们简单回顾一下其中比较重要的知识点:
通常来说,一次数据库操作只能得到一个 ResultSet 对象,因此一条 select 语句通常对应一个结果集.
但是因为一些额外的原因,一条 select 语句是可以返回多个结果集的.
比如:
- 部分数据库支持在一次查询中返回多个结果集
- 部分数据库支持在存储过程中返回多个结果集
- 部分数据库支持一次性执行多个语句
因此,如果我们想操作不同结果集中的数据,我们就有必要区分出每个结果集对象.
mybaits 为这种场景提供了一个解决方案,它允许我们在配置 select 元素的时候,通过配置其 resultSets 属性来为每个结果集指定名称.
结果集的名称和 resultSets 属性定义顺序对应,如果有多个结果集的名称需要配置,名称之间使用 , 进行分隔.
属性总结
至此,我们算是对 select 元素的所有属性都有了一定的了解.
其实, insert , select , update , delete 这四个元素他们具有很多相同的属性定义,在了解了 select 元素的属性之后,剩余三个元素的属性定义相对学习起来就比较简单了.
select元素的子元素定义
看完属性定义之后,让我们看一下 select 元素的子元素定义.
<!ELEMENT select (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> 复制代码
根据 DTD 定义来看, select 元素和 sql 元素竟然拥有完全相同的子元素定义:
<!ELEMENT sql (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> 复制代码
他俩拥有同样的 PCDATA 标记,因此和 sql 元素一样, select 元素中的文本定义,也是允许子元素和普通文本混排的.
至于剩余的子元素定义,我们将在了解了 insert , update 以及 delete 元素之后,进行深入的了解.
正文到此结束
- 本文标签: UI ResultSet key update http 数据库 IO 空间 参数 tab myabtis 配置 Statement 实例 java src Oracle 一级缓存 时间 mybatis 源码 mapper map JDBC Select Connection 二级缓存 代码 list 编译 文章 sql id 解析 总结 https cache 数据 缓存 value apache 删除 线程 Collection App 一对多 db StatementHandler
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

