Spring源码-循环依赖(附25张调试截图)
Spring 在哪些情况下会出现循环依赖错误?哪些情况下能自身解决循环依赖,又是如何解决的?本文将介绍笔者通过本地调试 Spring 源码来观察循环依赖的过程。
1. 注解属性注入
首先本地准备好一份 Spring 源码,笔者是从 Github 上 Clone 下来的一份,然后用 IDEA 导入,再创建一个 module 用于存放调试的代码。
本次调试有三个类,A、B 通过注解 @Autowired 标注在属性上构成循环依赖,Main 为主函数类。
@Component("A")
public class A {
@Autowired
B b;
}
复制代码
@Component("B")
public class B {
@Autowired
A a;
}
复制代码
public class Main {
public static void main(String[] args) {
ApplicationContext context =
new ClassPathXmlApplicationContext("spring-config.xml");
A a = (A) context.getBean("A");
B b = (B) context.getBean("B");
}
}
复制代码
可以先试着运行下,并不会报错,说明这种情况下的循环依赖能由 Spring 解决。
我们要观察如何解决循环依赖,首先需要知道 @Autowired 标注的属性是如何注入的 ,如 B 是怎么注入到 A 中的。
由于 A、B 的 scope 是 single,且默认 non-lazy,所以在 ClassPathXmlApplicationContext 初始化时会预先加载 A、B,并完成实例化、属性赋值、初始化等步骤。 ClassPathXmlApplicationContext 的构造方法如下:

其中 refresh 是容器的启动方法,点进去,然后找到我们需要的那一步,即实例化 A、B 的步骤:
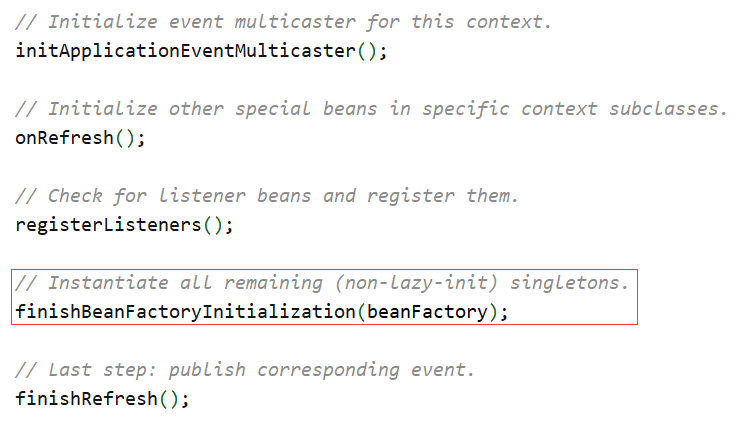
finishBeanFactoryInitialization 会先完成工厂的实例化,然后在最后一步实例化 A、B:

preInstantiateSingletons 将依次对 non-lazy singleton 依次实例化,其中就有 A、B:
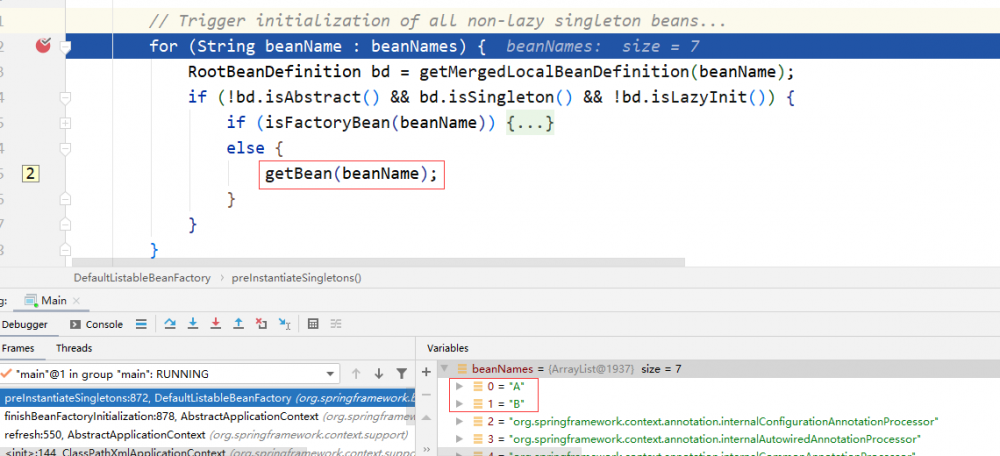
A、B 不是工厂类,则直接通过 getBean 触发初始化。首先会触发 A 的初始化。
getBean => doGetBean ,再通过 getSingleton 获取 Bean。注意在 doGetBean 中有两个 getSingleton 方法会先后执行,本文用 getSingleton-C 和 getSingleton-F 来区分。第一个是尝试从缓存中获取,这时缓存中没有 A,无法获得,则执行第二个,通过工厂获得。
public Object getSingleton(String beanName) 复制代码
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) 复制代码
这里会执行 getSingleton-F 来获取单例 Bean:
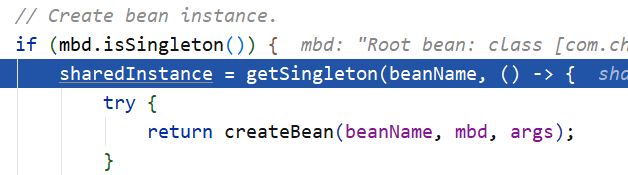
这里为 getSingleton-F 传入了个 Lambda 表达式给 ObjectFactory 接口类型的 singletonFatory 。
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) 复制代码
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
复制代码
所以将会创建一个 ObjectFactory 的匿名类对象 singletonFactory ,而其 getObject 方法的实现将调用 createBean 。
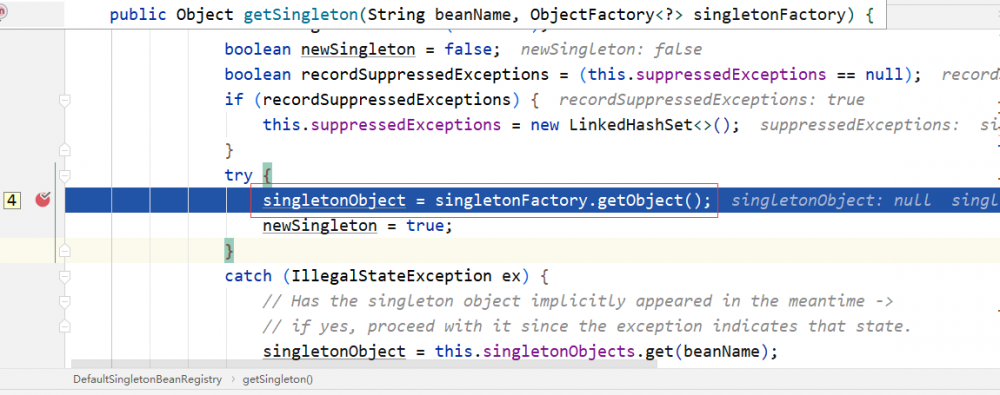
getObject => createBean => doCreateBean ,创建 A 的 Bean,关于 doCreateBean ,在 《如何记忆 Spring 的生命周期》 中有进行介绍。主要有 4 个步骤:(1)实例化,(2)属性赋值,(3)初始化,(4)注册回调函数。下面看下 B 是在哪一步注入到 A 中。
首先看下是不是实例化。
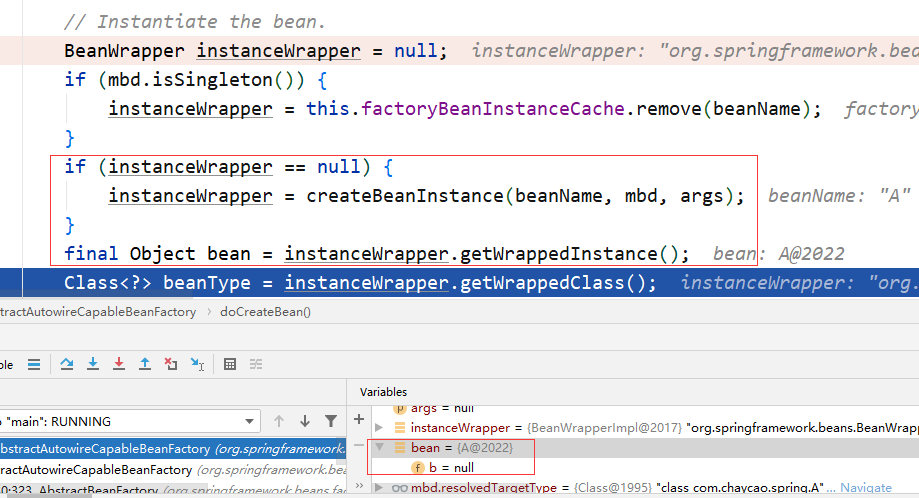
在实例化完成后,bean 中的 b 仍为 null,说明不是实例化。那再看下一步,属性赋值。
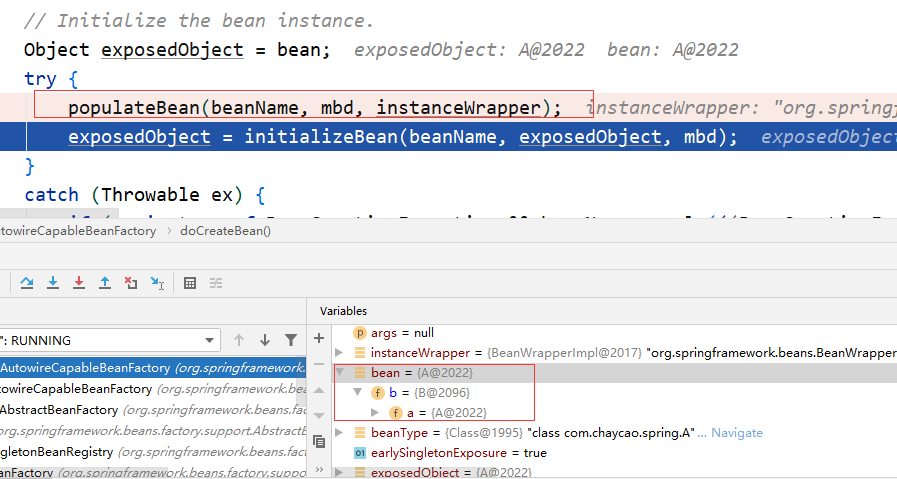
在 populateBean 执行后,bean 中的 b 不再是 null 了,而已经是 B 的对象了,而且 b 的 a 属性也不是 null,是此时正在创建的 bean,说明已经成功完成了依赖注入。所以 " @Autowired 标注的属性是如何注入的 " 和 " Spring 如何解决循环依赖 " 两个问题的答案都在 populateBean 这一步中。那再重新进入 populateBean 看下。
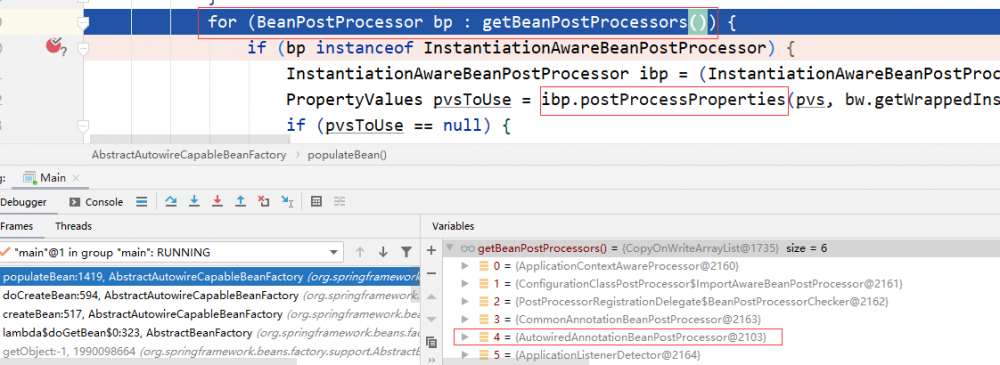
其中会依次调用 BeanPostProcessor 的 postProcessProperties 方法。在 getBeanPostProcessors 返回的 List 中有 AutowiredAnnotationBeanPostProcessor ,将负责 @Autowired 的注入。
AutowiredAnnotationBeanPostProcessor 的 postProcessProperties 方法如下所示:
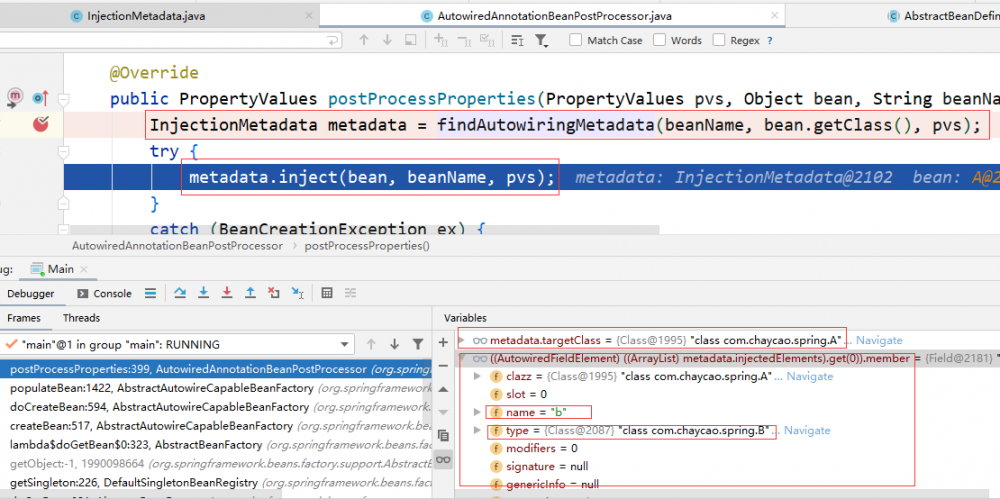
先找到被 @Autowired 标注的 b 属性,再通过 inject 注入。
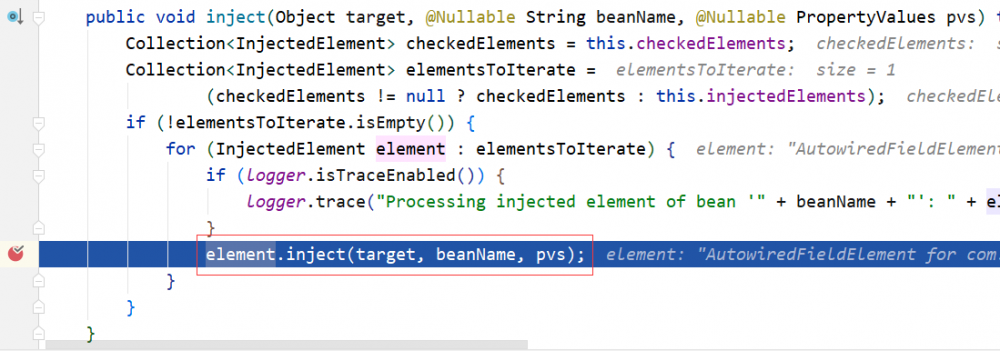
进入 inject 方法,由于 A 依赖 B,这里将通过 beanFactory.resolveDependency 获得 B 的 bean。
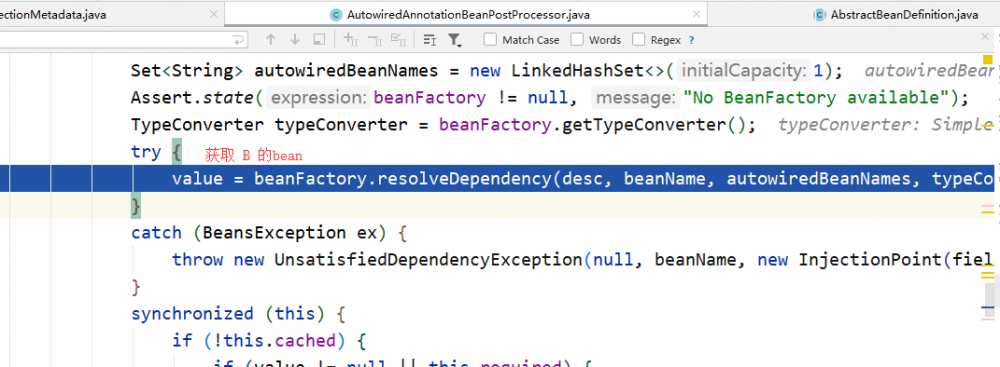
在成功获取 B 的 Bean 后,再通过反射注入。

现在需要关注的就是 resolveDependency ,这里解决 A => B 的依赖,需要去获取 B,将仍然通过 getBean 获取,和之前说 getBean 获取 A 的过程类似,只是这次换成了 B,调用栈如下:
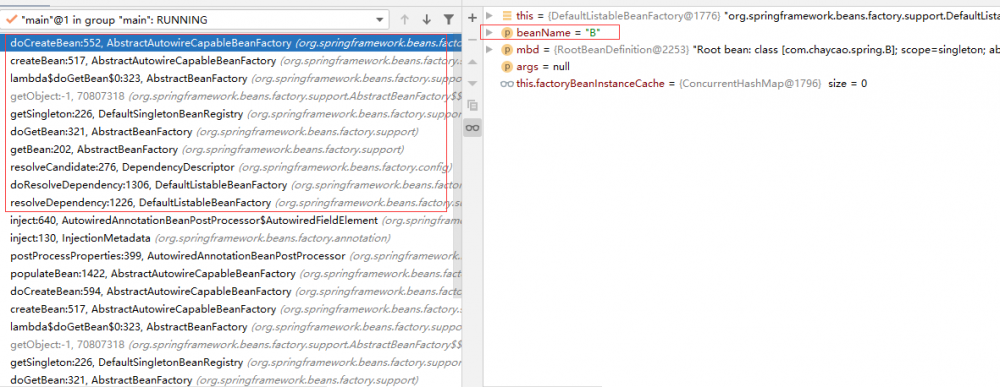
仍然将通过 doCreateBean 来创建 B 的 bean。
那么问题来了,之前说过 doCreateBean 会进行属性赋值,那么由于 B 又依赖 A,所以需要将 A 注入到 B 中,可是 A 也还正在进行 doGetBean 。那么 Spring 是怎么解决的循环依赖,关注 B 的 populateBean 就能知道答案了。
由于 B 依赖于 A,所以需要将 A 注入 B,该过程和前面说的 ”将 B 注入 A“类似,通过 getBean 来获得 A。
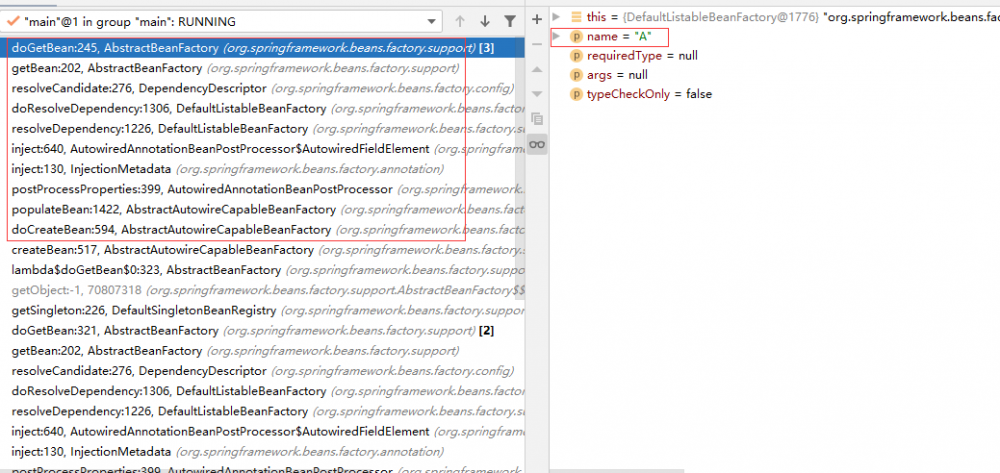
getBean => doGetBean => getSingleton ,又是熟悉的步骤,但这次 getSingleton-C 中发生了不一样的事,能够成功获得 A 的缓存。
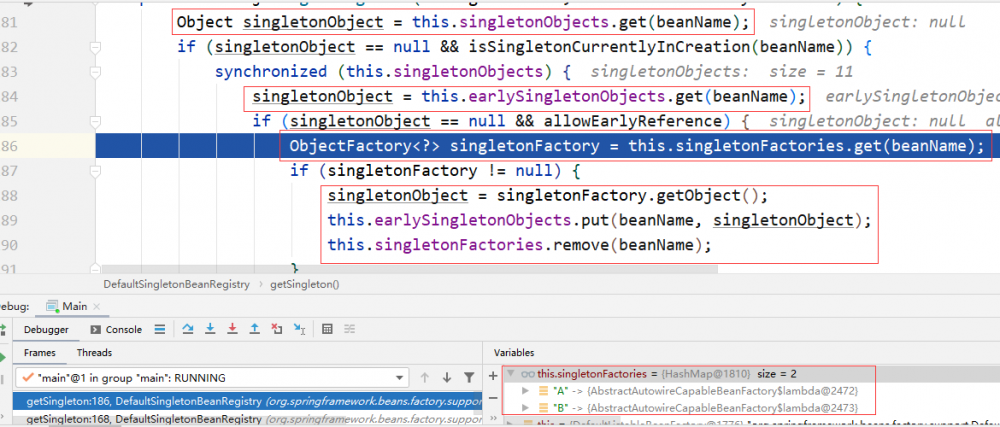
首先尝试在 singletoObjects 中获取,失败。接着尝试从 earlySingletonObjects 中获取,失败。最后在 singletonFactories 中获取到 singletonFactory ,并通过 getObject 获取到 A 的 bean。
这三者被称作 三级缓存 ,在 getSingleton-C 方法中会依次从这三级缓存中尝试获取单例 Bean。当从第三级缓存获取到 A 后,会将其从第三级缓存中移除,加入到第二级缓存。
/** Cache of singleton objects: bean name to bean instance. */ // 缓存单例Bean private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); /** Cache of early singleton objects: bean name to bean instance. */ // 缓存正在创建,还未创建完成的单例Bean private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); /** Cache of singleton factories: bean name to ObjectFactory. */ // 缓存单例bean的工厂 private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); 复制代码
我们可以看到 singletonFactories 中存有 A 和 B,它们是什么时候被加到三级缓存中的呢?就是在 doCreateBean 中做 populateBean 的前一步通过 addSingeletonFactory 把 beanName 和 ObjectFactory 的匿名工厂类加入到第三级缓存中。当调用 singletonFactory.getObject 方法时,将调用 getEarlyBeanReference 获取 A 的 Bean。

getEarlyBeanReference 会返回 A 的引用 ,虽然 A 还在创建,未完成。
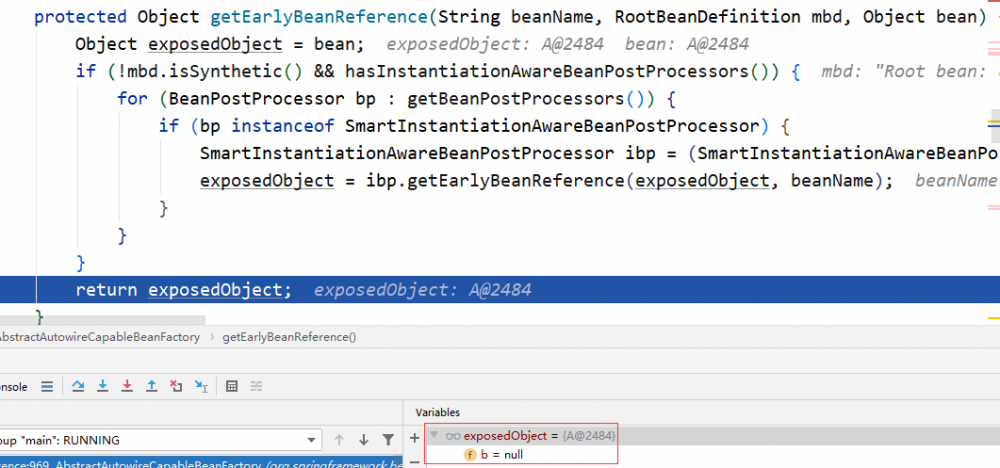
让我们想下后面会发生的事:
doCreateBean
最后 A、B 的 Bean 都完成创建。
之所以通过注解属性注入不会存在循环依赖问题,是因为 Spring 记录了正在创建的 Bean,并提前将正在创建的 Bean 的引用交给了需要依赖注入的 Bean,从而完成闭环,让 B 创建成功,不会继续尝试创建 A。
在这个过程中最关键的是 Bean 的引用,而要有 Bean 的引用便必须完成 doCreateBean 中的第一步 实例化 。
我们这里是将 @Autowired 标注在属性上,而依赖注入发生在第二步 属性赋值 ,这时才能成功获取到引用。
下面我们试下修改 A、B 为构造器注入,让依赖注入发生在第一步实例化中。
2. 构造器注入
@Component("A")
public class A {
B b;
@Autowired
public A(B b) {
this.b = b;
}
}
复制代码
@Component("B")
public class B {
A a;
@Autowired
public B(A a) {
this.a = a;
}
}
复制代码
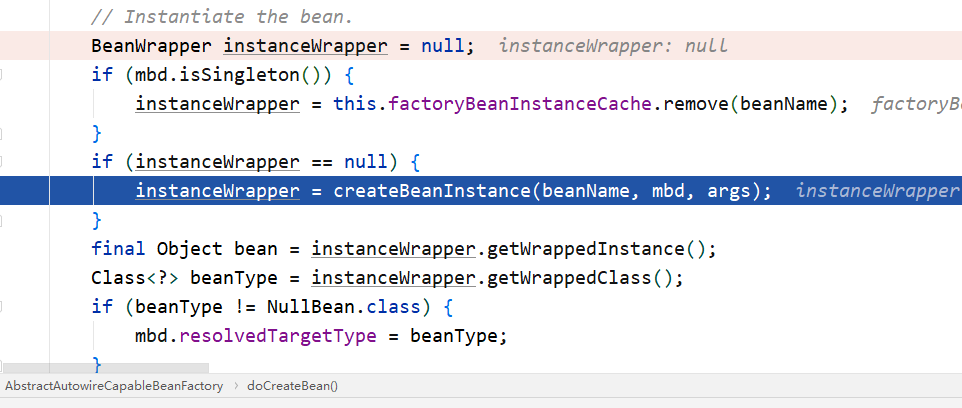
构造器的注入将发生在 doCreateBean 的第一步 createBeanInstance ,具体方法如下:
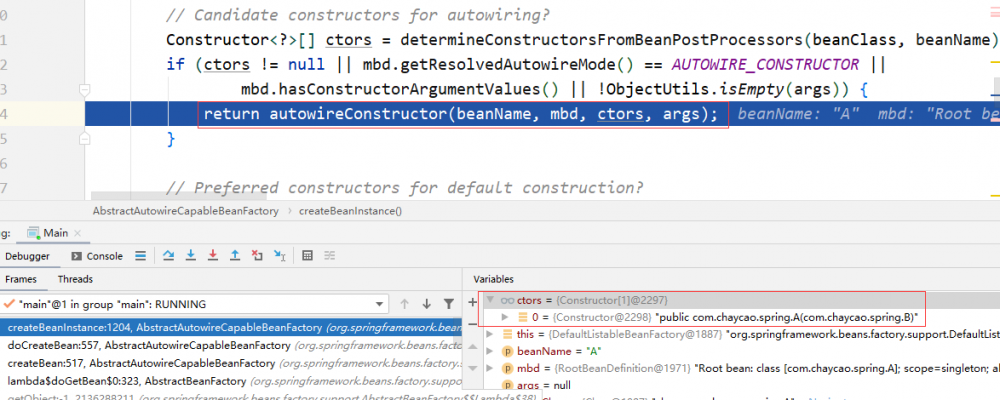
获取 A 的构造器,执行 autowireConstructor 。然后调用 ConstructorResolver 的 createArgument 方法处理构造函数的参数,由于构造器被 @Autowired 标注,将使用 resolveAutowiredArgument 处理注入参数,接着又是熟悉的步骤,调用栈如下:
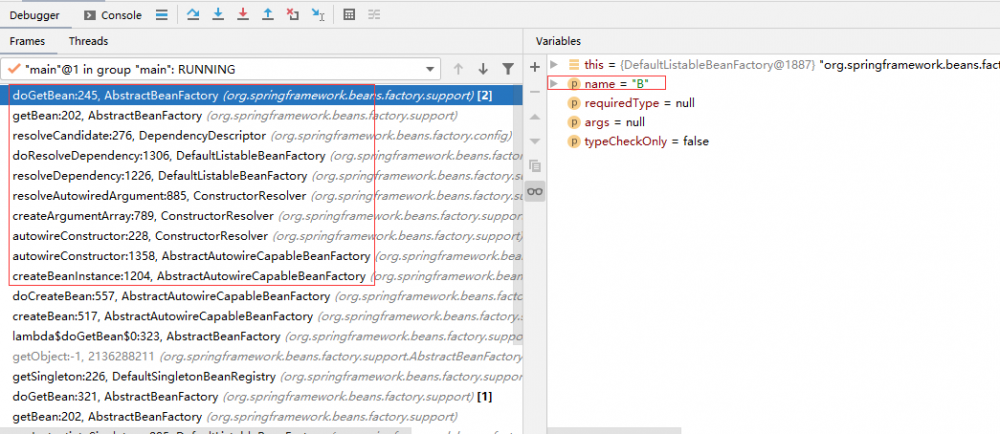
处理依赖注入,会通过 getBean 获得 B,在 doCreateBean 中进行 B 实例化。
那我们就再进入 B 实例化的第一步 createBeanInstance 方法,调用栈如下:
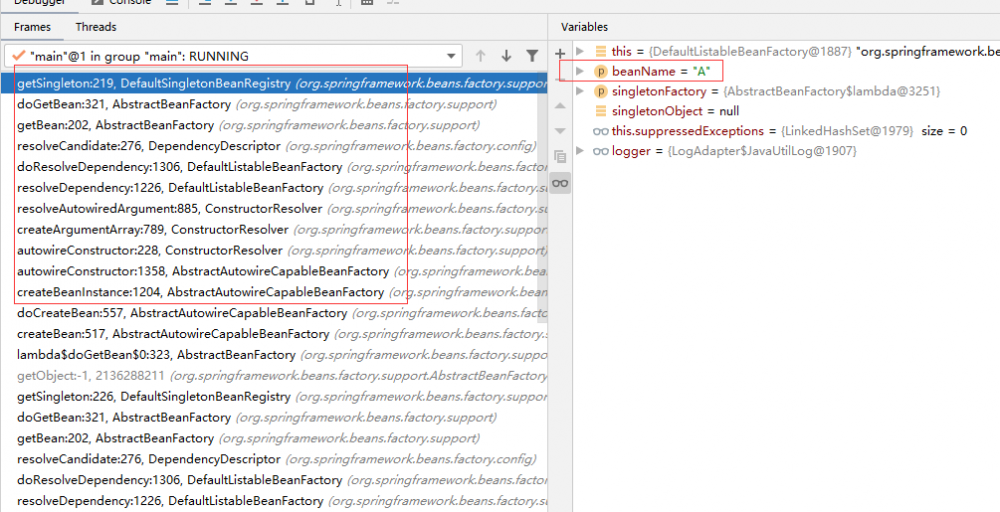
B 的构造方法依赖 A,则尝试通过 doGetBean 获取 A。由于 A 没有在 doCreateBean 中完成实例化,所以 getSingleton-C 中无法获得 A 的缓存,则只能通过 getSingleton-F 方法尝试获得 A。
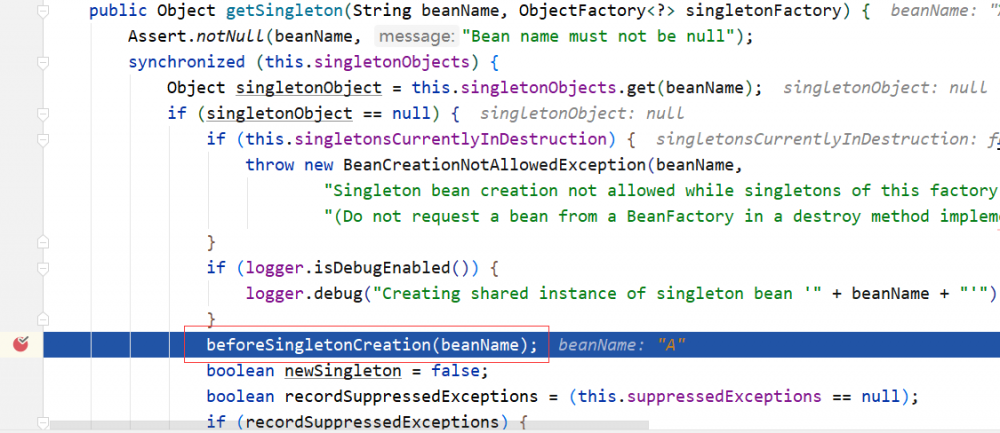
但在 getSingleton-F 中的 beforeSingletonCreation 方法将对循环依赖进行检查。
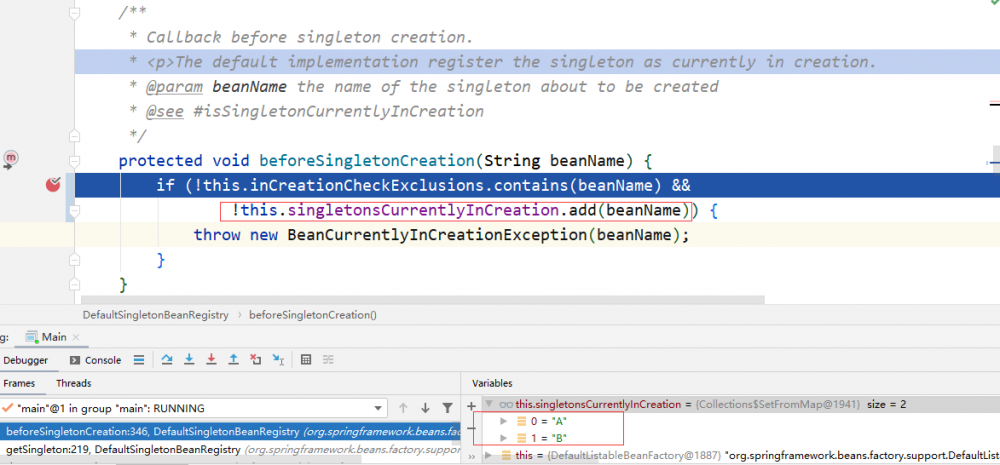
singletonsCurrentlyInCreation 是一个 set,由于 A 已经 都在 getSingleton-F 中执行过一遍了,已经被添加到了 singletonsCurrentlyInCreation ,所以这里第二次通过 getSingleton-F 获取 A 时,add 返回 false,将抛出 BeanCurrentlyInCreationException 异常。
小结
对比以上两种方式 “属性注入” 和 “构造器注入”,都是 A => B => A,区别在于 B => A 时,“属性注入” 在 getSingleton-C 中会通过缓存获取到 A 的引用,而 “构造器注入”,则由于不存在 A 引用,也自然无法通过缓存获得,便会尝试再次通过 getSingleton-F 获取,而及时被 beforeSingletonCreation 检查抛出循环依赖异常。

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

