论文阅读 - TResNet High Performance GPU-Dedicated Architecture
作者在摘要中所想的我们在工作中也观察到,尽管最近两年关于CNN网络的设计仍然有各式各样论文出现,比如Mobilenet / ShuffleNet,又或者是NAS搜索的网络结构如EfficientNet等,实际在GPU上使用起来并没有设想的那么high performance(latency / throughput),反而是ResNet系列历久弥新,真正经受住了工业界的考验,仍然是最常用的模型(可以很肯定没有之一),尤其是50,在速度和精度上达到了很好的trade off。
vanilla ResNet50 is usually significantly faster than its recent competitors, of- fering better throughput-accuracy trade-off.
深度学习技术现在早已经走出了学术象牙塔,在工业界广泛铺开。在精度已经没有太多提升空间的现在,网络的计算资源消耗 / latency / QPS等越来越成为大家关注的热点。这篇文章就试图在维持网络high performance的前提,提升网络的精度。这在现实问题中很有意义。
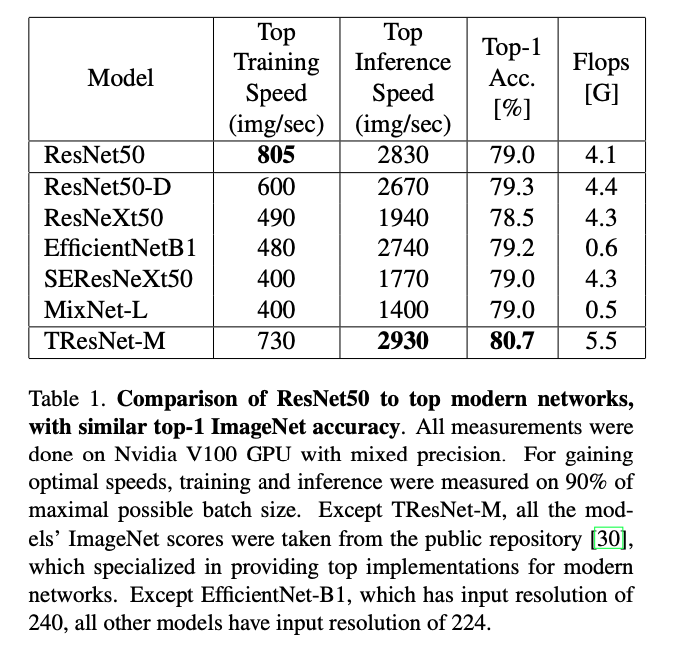
你们呐,还是Too young, too simple
见题图,作者比较了几种SOTA模型和ResNet-50在train和inference的速度(其实体现的是大批量时候的吞吐),可以看到最过分的是EfficientNet和MixNet,FLOPS比ResNet低了这么多,吞吐反而不如(如果没有Google的TPU加持,还是不要挑战EfficientNet了,我们的实测也是发现很坑)。
GPU的计算力越来越强,很多时候其实并不是FLOPS限制了网络的能力,而是访存。
- EfficientNet / ResNext / MixNet:使用分离卷积降低了FLOPS,但是实际考虑GPU吞吐量时,更重要的是访存,而不是节省的那一点FLOPS。就像这个帖子里面所讨论的那样 FP32 depthwise convolution is slow in GPU #18631
PS: Depthwise and group convolution is slower due to lower arithmetic intensity i.e. reduced data reuse (both leads to fragmented memory-accesses). Its a feature not a bug. Only specialized implementation can make it fast.
- multi-path的使用。在训练的时候,需要为这些路径上的激活都储存相应的grad,造成显存占用上升,不利于大batch size,导致吞吐下降。
这里作者对访存的diss之前也看过其他人的分析,我并不是做体系结构的。不过据我所知,很多神经网络加速器也是在解决这个问题。随着芯片的计算能力越来越强,XXTFLOPS的能力,却会被mem访问速度限制。IC设计和半导体产业就这样,不断地在实际中发现问题解决问题,让我们从五十年前(现在看来)孱弱的计算力,一步步发展到今天便捷的手机和强大的GPU。而计算能力的提升,又不断地催生新的技术应用。提出新的问题。电气革命依靠的是对化石能源的利用,而信息革命离不开计算能力的不断发掘。摩尔定律万岁~

TResNet的设计
怎么说呢,这里的设计好像并没有什么太深入的东西。也是读到这里,让我对这篇文章的价值觉得没这么大了。
Stem设计
Stem指的是data输入到ResNet连读堆叠block之间的那个部分,起到的作用是迅速downsample输入。例如ResNet使用$7/times 7$,stride为2的conv和max pooling串联,将输入从224缩小到56。其他网络也都有类似的设计。在 Bag of tricks 这篇文章中,ResNet-D是将$7/times 7$的conv分解为两个$3/times 3$的conv,
这里TResNet使用了一个“Space-To-Depth” layer,将spatial转到depth维度上去,达到缩小尺寸的目的,再接一个$1/times 1$的conv,得到想要的channel数量。
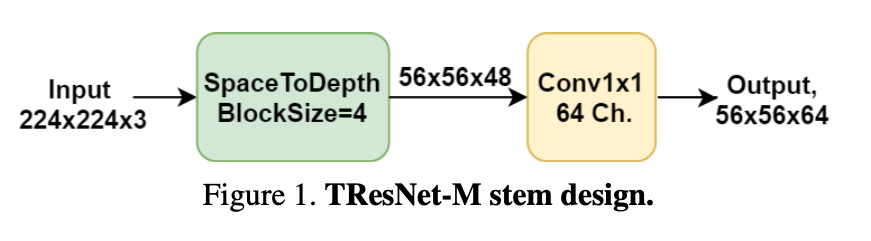
代码中有这个layer的具体实现方式。类似ShuffleNet,以H为例,会将其分为若干组,即 bs
,然后重组。
class SpaceToDepth(nn.Module):
def __init__(self, block_size=4):
super().__init__()
assert block_size == 4
self.bs = block_size
def forward(self, x):
N, C, H, W = x.size()
# reshape NCHW -> NCH'BW'B
x = x.view(N, C, H // self.bs, self.bs, W // self.bs, self.bs) # (N, C, H//bs, bs, W//bs, bs)
# transpose: NBBCH'W'
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # (N, bs, bs, C, H//bs, W//bs)
# reshape -> NC'H'W'
x = x.view(N, C * (self.bs ** 2), H // self.bs, W // self.bs) # (N, C*bs^2, H//bs, W//bs)
return x
这个操作来自于这篇文章 Non-discriminative data or weak model? On the relative importance of data and model resolution 。核心观点是“是网络内部的feature map的resolution影响网络acc,而不是输入”
In this paper, we show that up to a point, the input resolution alone plays little role in the network performance, and it is the internal resolution that is the critical driver of model quality. We then build on these insights to develop novel neural network architectures that we call /emph{Isometric Neural Networks}. These models maintain a fixed internal resolution throughout their entire depth.
抗混叠(anti-alias)下采样 - AA
将ResNet中的下采样换成一种比较经济的AA:stride为2的conv被替换为stride为1的conv,再接上stride为2的blur $3/times 3$的conv kernel
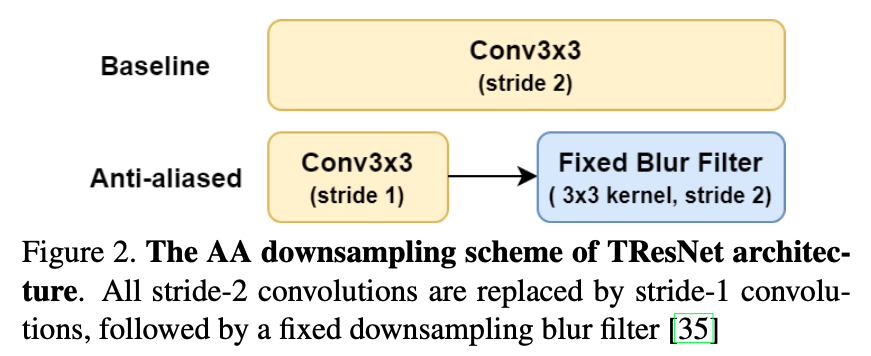
具体实现代码(只展示了blur的$3/times 3$conv)如下。可以看到这里直接使用了$3/times 3$的 高斯模糊kernel :
class Downsample(nn.Module):
def __init__(self, filt_size=3, stride=2, channels=None):
super(Downsample, self).__init__()
self.filt_size = filt_size
self.stride = stride
self.channels = channels
assert self.filt_size == 3
a = torch.tensor([1., 2., 1.])
"""
In [2]: a = torch.tensor([1., 2., 1.])
In [3]: filt = (a[:, None] * a[None, :])
In [4]: filt
Out[4]:
tensor([[1., 2., 1.],
[2., 4., 2.],
[1., 2., 1.]])
"""
filt = (a[:, None] * a[None, :])
filt = filt / torch.sum(filt)
# self.filt = filt[None, None, :, :].repeat((self.channels, 1, 1, 1))
self.register_buffer('filt', filt[None, None, :, :].repeat((self.channels, 1, 1, 1)))
def forward(self, input):
input_pad = F.pad(input, (1, 1, 1, 1), 'reflect')
return F.conv2d(input_pad, self.filt, stride=self.stride, padding=0, groups=input.shape[1])
Inplace Activated BN (Inplace ABN)
把所有的BN+ReLU结构换成了Inplace Activated BN,节省训练时候的显存消耗,并使用Leaky ReLU替换了plain ReLU。使用Inplace ABN增大了少许计算量,不过大大增加了batch size,从而增大了网络的吞吐。
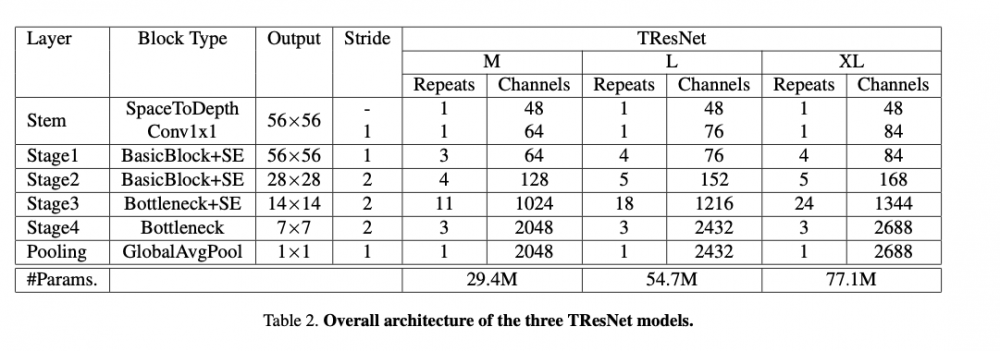
Block 选择
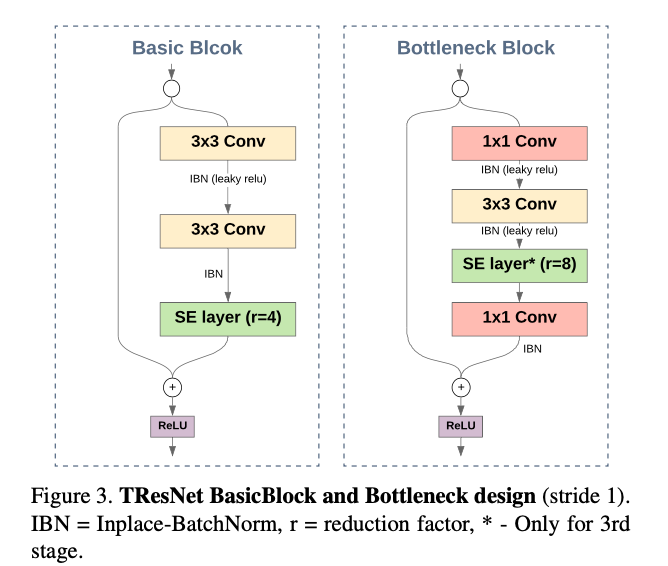
ResNet论文中,对于不同深度的网络,采取了两种不同的Block构造方法,plain是指bypass直接堆叠$3/times 3$的两个conv。bottleneck指bypass首尾使用$1/times 1$来reduce depth,中间使用单个$3/times 3$的conv。对于18和34层网络,使用plain;对于50及以上使用bottleneck。
这里作者认为plain结构有更大的感受野,所以放在网络浅层(前两个stage);bottleneck放在网络深层(后两个stage)。具体网络结构见下图:
SE op
SENet提出的SE改进用的比较多了。这里作者加进来主要是为了提高网络的acc。具体见下吧,没什么好说的:

最后,TResNet的单个block进化成了这个样子:
Code optimization
作者这里花了不少的篇幅讲如何使用jit等trick在PyTorch中加速TResNet。据我们的使用经验,jit是有用,但是会被TRT落下一大截。所以用PyTorch native模型去部署并没有什么意思。TResNet中的操作也都是可以TensorRT化的,然而我对它TensorRT的速度持怀疑态度。
所以这里其实我并没有看。有兴趣的话可以对照代码学习下,包括jit的使用。
实验
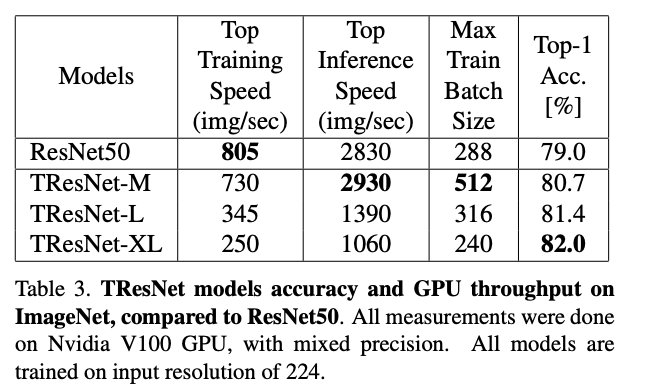
实验结果这里贴一下。作者构造了M / L / XL三个系列(大杯,超大杯?),其实M是用来和ResNet-50打擂台的。
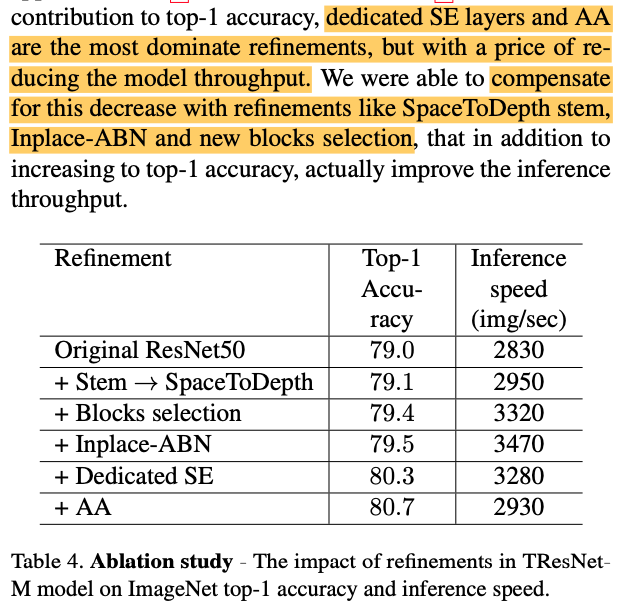
下面的消融实验我觉得还是有一定意义的。
此外,增大input的分辨率一般也能提升网络acc,当然也会拖慢网络。这里作者进行了测试。发现TResNet-M在输入size为448情况下,也能有很大的提升。具体数据这里不贴了。
后面和EfficientNet的比较不多说了。不用TPU,EfficientNet并没有多实用。
总结
这篇文章读下来,并没有标题和摘要那般有意义。又是ResNet-50被拉出来打,最后其实速度也没提升多少。训练速度其实我们并不太care;inference速度的话和ResNet-50不相上下,而acc其实也高了一点而已。据我们实际工作观察,有TRT加持的ResNet-50的速度更是起飞(nv对ResNet做了很多对应的trick加速,甚至有block级别的plugin加速支持。。见 ResNet50 Benchmark )。所以其实如果用TRT部署,目测这篇文章的模型结构是拼不过ResNet的。
TResNet把前人的工作做了一个杂烩。又想快又想acc高怎么办?增大吞吐。然而对于GPU这种已经定型的硬件,其实就是增大batch size。。。简单总结下:
- 提升acc:auti-alias downsampling,leaky-relu,se
- 提升吞吐:spatial-to-depth,inplace-ABN,se不全用,plain / bottleneck 混用
当然,上面两个具体内容是有交叉的。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

