java垃圾回收
1.垃圾回收
垃圾回收是jvm代替我们回收内存的策略,我们选择垃圾回收方式时最主要考虑的指标就是停顿时间和碎片率。
如何判断对象可回收
1.引用计数法:记录对象被引用的次数,当引用次数为0时,表示对象可以被回收了。但如果对象间有互相引用,就会造成对象引用计数无法清零,对象不能被回收。虽然引用计数法不是jvm判断对象可用的方式,但还是有很多内存池的实现能保证对象不被循环引用,而使用引用计数法。
2.可达性分析:通过根节点对象(GC root),向下遍历所有引用关系,能到达的对象认为是存活的对象,不能到达的则认为可以回收。可达性分析是jvm判断对象存活的方式,其中根节点主要包括:虚拟机栈中引用的对象,方法区中类静态属性引用的对象,方法区中常量引用的对象,本地方法栈中Native方法引用的对象。
垃圾回收算法
1.标记清除:标记清除算法主要分为两步,通过可达性分析判断是否存活,再清理可回收的对象,只是简单地清除不做其他动作。但因为内存是连续的线性地址,我们每次分配对象的大小又不一致,所以会产生内存碎片。
2.复制算法:复制算法针对内存碎片的问题,在清理对象时,会开辟一块新的内存空间,把存活的对象移动到新的内存空间,然后旧的内存空间整个清理掉。相比标记清除没有内存碎片,但需要的内存会大很多。
3.标记整理:标记整理算法会在清理可回收对象的同时整理内存,移动存活的对象,让所有存活的对象都连续排列在一起,没有内存碎片。但移动对象相对复杂,消耗cpu资源比较多。
分代
我们在考虑应用垃圾回收算法时,针对他们各自的特点,例如复制算法因为需要开辟新内存,所以比较占用内存,但如果存活对象比例很少,占用的内存也就会很少,那什么情况下存活对象少呢?新创建的对象大概率方法执行后就可以回收了。所以复制算法适合新创建的对象。
标记整理算法因为需要移动整理,所以如果整理时需要移动的对象少就会相对少使用cpu,如果一个对象在经过几次垃圾回收后还存活,大概率就是被静态变量引用,所以越早创建的对象被回收的概率越小,越不需要整理,整理时只需要整理内存地址后段相对较新的对象。
所以针对不同时期的对象,适用的垃圾回收算法各不相同,针对这种情况,jvm对堆内存做了分代处理。
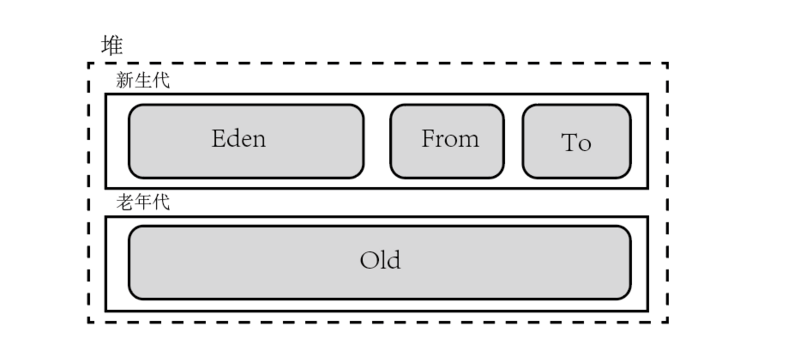
一个对象在eden区被创建后,当eden区满了会触发年轻代gc,会把eden区和survivor的From区存活对象移动到survivor的to区,再触发年轻代gc,再把eden区和survivor的to区移动到from区,对象被移动一定次数后(默认16次),会移动到old区。
不管什么gc策略,在年轻代都是这个复制算法,区别只是在并行或串行,是否可以和用户线程并发。
GC策略
gc策略会区分年轻代和年老代,不同的策略可以自由组合,不过有一定限制条件。
| 年轻代 | 年老代 |
|---|---|
| Serial | Serial old |
| Serial | cms |
| ParNew | cms |
| ParNew | Serial Old |
| Parallel Scavenge | Serial Old |
| Parallel Scavenge | Parallel Old |
| g1 | g1 |
1.Serial是串行gc,年轻代Serial采用复制算法,年老代采用标记整理算法,单线程标记、单线程回收,不能与用户线程并发执行,适用于单核cpu,没有线程切换的成本。
2.ParNew是一个年轻代的gc,在年轻代和serial的区别就是ParNew是多线程的,在多核cpu下表现更好。
3.Parallel是一个年轻代的gc,方式与ParNew类似,Parallel主要面向吞吐量,提供额外的最大停顿时间和gc时间比例等参数,也提供自适应的方式,由虚拟机控制eden和survivor区的比例,复制多少次晋升老年代等。
4.Parallel Old是Parallel对应的老年代策略,采用标记整理算法,多线程标记,多线程整理,不能与用户线程并发执行。
5.cms是一个老年代的gc,采用标记清除算法,cms是为了减少用户线程停顿时间,提高并发。
6.g1
2.CMS
cms是年老代的gc,采用标记清除算法,所以会有内存碎片,所以会用Serial old做备用的fullgc,当满足一定条件下会触发fullgc。
cms因为要给fullgc和并发的用户线程预留空间,所以不是在年老代满了的时候触发。
cms主要目的是降低用户线程停顿时间,cms会把gc分成七个阶段,不能与用户线程的阶段单独执行,可以和用户线程同时执行的并发执行,最大限度的减少停顿时间。
1.初始化标记
这个阶段会通过gc roots和年轻代所有对象标记那些老年代对象被引用(只标记老年代的第一层),这个阶段是stop the world的。
2.并发标记
通过第一阶段标记的对象向下递归遍历所有可达对象,这个阶段是可以和用户线程并发执行的。
3.并发预清理
这个阶段会通过扫描card table找到内部引用关系变化的对象,然后递归标记,最后清除card table。这个阶段是可以和用户线程并发执行的。
4.可中止的并发预清理
这个阶段会扫描年轻代和card table,尽可能锁的找到未被标记的可达对象。这个阶段是可以和用户线程并发执行的。
5.重新标记
通过gc roots,年轻代,card table,找到前几个阶段未标记的可达对象,这个阶段是stop the world的。
6.并发清理
清理所有未被标记的对象,回收被占用的空间,这个阶段是可以和用户线程并发执行的。
7.并发重置
清理本次gc的数据,为下次gc做准备,这个阶段是可以和用户线程并发执行的。
2.G1
概念
region:g1会把堆内存分成若干region,regin分为4类,eden、survivor、old、humongous。
rset:其他Region中指向本Region中所有对象的引用,但只有年轻代到年老代的引用会被rset记录。
cset:待回收的region。
回收过程
g1会触发三类垃圾收集,第一类会回收全部的年轻代region,第二类会回收全部的年轻代+部分年老代region,第三类fullgc扫描整个堆。
标记阶段:
1.扫描所有gc roots,类似cms,会stop the world。
2.扫描上一步对象引用的老年代对象,这一个过程是并发进行的。
3.标记整个堆的存活对象,并发阶段产生的变化会被SATB的write barrier记录下来。
4.扫描SATB,处理在上个阶段新的引用关系,会stop the world。
5.会计算每一个region里面存活的对象,并把完全没有存活对象的region直接放到空闲列表中。在该阶段还会重置rset。该阶段在计算region中存活对象的时候,是stop the world,而在重置rset的时候,是可以并行的。
迁移阶段:
1.合并rset与stab,会stop the world
2.确定region存活的对象
3.拷贝存活对象
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

