关于Java两点需要更新的知识
HashMap的初始容量
背景
很多人可以把HashMap的原理描述的很溜。比如JDK1.7之前,底层数据结构是数组+链表。JDK1.8之后,出于效率上的考虑,在数组长度大于64,链表长度大于8的时候,会转换为红黑树。
甚至知道对于赋值了容量的都会做一个变成2的n次方的操作。它的hash方法为了防止高位变化大或者低位变化大将它本身hash值右移16位和自身原hash值做一个按位异或操作再与容量-1做按位与。还知道默认的负载因子是0.75,这个值是经过概率论统计出来的,最好不要改。
了解的这么清楚,我就想问一下为什么从数据库中取出来一个list,之后转换成hashmap。直接用的是Map map = new HashMap()或者是Map map = Maps.newHashMap(),为什么不赋初始容量呢?
分析
容量的大小会在put过程中发生resize操作。如果初始不赋值。默认容量是16。那比如从数据库中取出来1000个元素。put过程中会从16->32->64->128……,运行多次resize操作。resize操作数组,需要将所有元素进行复制和rehash,效率是很低的。
所以也有一些同学考虑到这个问题,代码是这么写的: Map map = new HashMap(list.size());
这个写法也有问题,因为resize并不是到达容量上限才resize。为了尽量避免hash冲突,是超过阈值threshold就扩容。而这个threshold=容量*负载因子。
所以我更建议的写法是Map map = new HashMap(list.size()/负载因子)。
这样理论上可以比Map map = new HashMap(list.size())减少一次resize。
总结
在可以确定HashMap容量时,最好Map map = new HashMap(list.size()/负载因子)来初始化,避免自动扩容带来的性能损耗。
思考
ConcurrentHashMap怎么来更合理的初始化?
JVM内存结构和 Java内存模型
背景
前段时间偶然看到有篇文章批判很多人对「JVM内存模型」这个概念不清楚,说这个经典的图并不是内存模型而是内存结构。
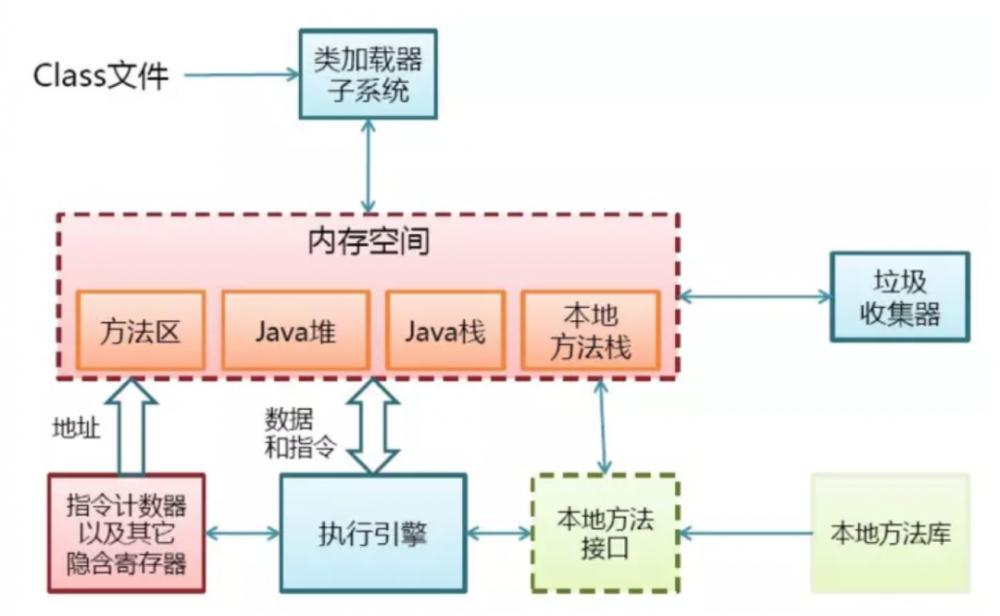
而内存模型应该是JSR133规范里介绍的volatile、final和synchronized等关键字的内存语义。
分析
这个非常富有淘金式思维的作者却搞混了一个概念,看看下面JSR-133规范里是怎么说的:JSR133规范里讲的Java内存模型,并没有说是JVM的内存模型啊。

Java内存模型讲的是Java语言本身的规范,这个规范包含了各个Java标准关键字在JVM里是怎样运作的。而JVM内存模型描述的是Java虚拟机怎样运行字节码的。所以上面经典的图说是JVM内存模型也不为过。不过根据官网,叫JVM内存结构更为标准。证据如下:
https://docs.oracle.com/javase/specs/jvms/se14/html/jvms-2.html#jvms-2.5
在oracle官网里,介绍了这个概念
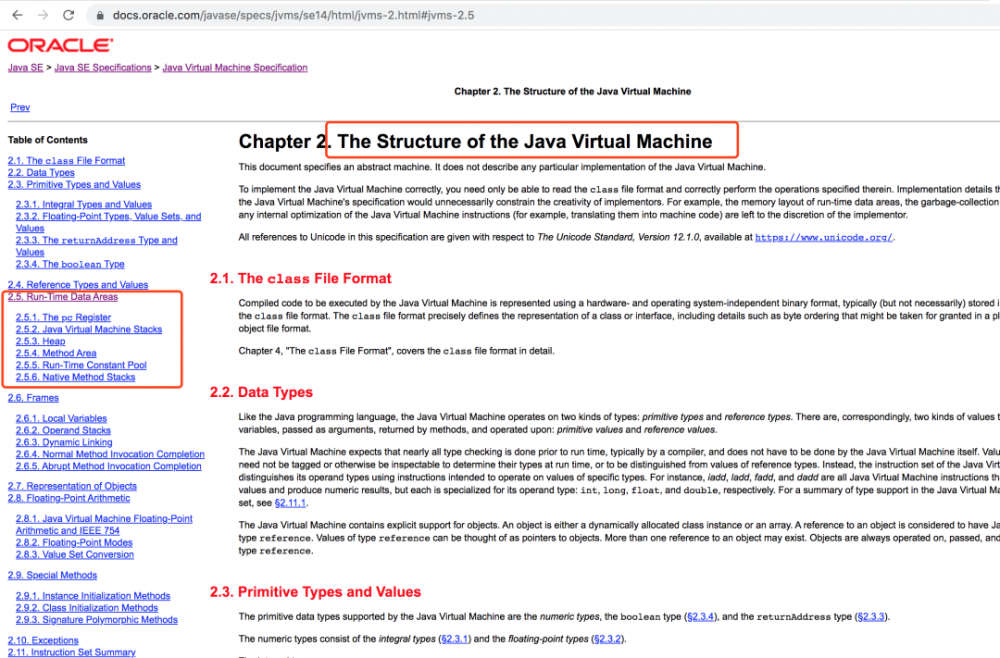
总结
Java内存模型和JVM内存模型是两个概念。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

