Mybatis源码之美:3.8.探究insert,update以及delete元素的用法
在这篇文章中,我们主要学习一下 insert , update 以及 delete 元素的定义和作用.
insert和update元素
如果认真观察的话,我们可以发现 insert 和 update 两个元素具有 完全相同 的 DTD 定义:
<!ELEMENT insert (#PCDATA | selectKey | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST insert id CDATA #REQUIRED parameterMap CDATA #IMPLIED parameterType CDATA #IMPLIED timeout CDATA #IMPLIED flushCache (true|false) #IMPLIED statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED keyProperty CDATA #IMPLIED useGeneratedKeys (true|false) #IMPLIED keyColumn CDATA #IMPLIED databaseId CDATA #IMPLIED lang CDATA #IMPLIED > <!ELEMENT update (#PCDATA | selectKey | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST update id CDATA #REQUIRED parameterMap CDATA #IMPLIED parameterType CDATA #IMPLIED timeout CDATA #IMPLIED flushCache (true|false) #IMPLIED statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED keyProperty CDATA #IMPLIED useGeneratedKeys (true|false) #IMPLIED keyColumn CDATA #IMPLIED databaseId CDATA #IMPLIED lang CDATA #IMPLIED > 复制代码
相较于 select 元素来讲, insert 和 update 元素移除了用于配置返回结果的相关属性,新增了几个用于配置主键的属性.

(上图中, 红色标记 为移除属性, 绿色标记 为新增属性.)
在 Mybatis源码之美:3.7.深入了解select元素 一文中针对上诉的大部分属性,我们已经做了详细的介绍,因此这篇文章,我们主要看一下新增的用于配置主键的属性.
有些时候,在进行数据库表设计的时候,我们会将数据记录的主键生成行为交给数据库来完成,以此来避免类似于 主键冲突 之类的问题.
比如,针对 USER 表设计:
create table USER
(
id INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1 ),
name varchar(20),
PRIMARY KEY (id)
);
复制代码
我们在新增 USER 记录的时候,只需要指定 name 列的值即可,而无需关心 id 列的值.
但是,这样就产生了一个新的问题:在新增数据记录之后,我们可能需要新增数据的主键值,并以此进行后续的工作.
比如,在新增用户之后,我们可能会需要新增用户的 id 来关联用户角色表.
这时候,我们就需要获取到由数据库生成的主键值.
useGeneratedKeys 属性
自 JDBC3.0 开始, Statement 对象的 getGeneratedKeys() 可以获取因为执行 当前 Statement 对象而 生成的主键 ,如果 Statement 没有生成主键,则返回 空 的 ResultSet 对象.
/** * Retrieves any auto-generated keys created as a result of executing this * <code>Statement</code> object. If this <code>Statement</code> object did * not generate any keys, an empty <code>ResultSet</code> * object is returned. * *<p><B>Note:</B>If the columns which represent the auto-generated keys were not specified, * the JDBC driver implementation will determine the columns which best represent the auto-generated keys. * * @return a <code>ResultSet</code> object containing the auto-generated key(s) * generated by the execution of this <code>Statement</code> object * @exception SQLException if a database access error occurs or * this method is called on a closed <code>Statement</code> * @throws SQLFeatureNotSupportedException if the JDBC driver does not support this method * @since 1.4 */ ResultSet getGeneratedKeys() throws SQLException; 复制代码
mybatis 中 useGeneratedKeys 属性的作用就是通知 mybatis 使用 JDBC 自带的 getGeneratedKeys() 方法来获取 由数据库生成 的主键.
Statement 对象提供了三种执行 SQL 的方法,他们分别是: execute() , executeUpdate() 以及 executeLargeUpdate() .
这三个方法都提供了一个可以额外传入 int 类型的 autoGeneratedKeys 参数的重载实现.
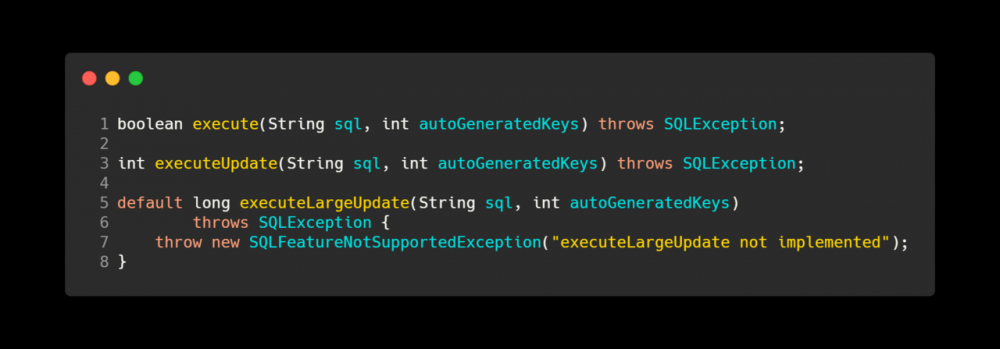
autoGeneratedKeys 参数的取值来自于 Statement 接口中的两个常量: RETURN_GENERATED_KEYS 和 NO_GENERATED_KEYS .
// 返回生成的主键 int RETURN_GENERATED_KEYS = 1; // 不返回生成的主键 int NO_GENERATED_KEYS = 2; 复制代码
其中 RETURN_GENERATED_KEYS 表示返回生成的主键, NO_GENERATED_KEYS 表示不返回生成的主键.
我们先感受一下原始的 JDBC 获取自增主键的方法:
数据初始化脚本:
/* ======================== 插入用户数据 =============================*/
drop table USER if exists;
create table USER
(
id INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1 ),
name varchar(20),
role_id int,
PRIMARY KEY (id)
);
insert into USER (name, role_id)
values ( 'Panda1', 1);
insert into USER (name, role_id)
values ( 'Panda2', 2);
复制代码
单元测试类:
@Test
@SneakyThrows
public void returnGeneratedKeysTest() {
// 获取连接
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
@Cleanup
Connection connection = sqlSession.getConnection();
assert connection.getMetaData().supportsGetGeneratedKeys();
// 执行插入
Statement statement = connection.createStatement();
// 插入一条新纪录
statement.executeUpdate("insert into USER ( name, role_id) values ('Panda', 1);", Statement.RETURN_GENERATED_KEYS);
ResultSet keys = statement.getGeneratedKeys();
while (keys.next()) {
log.debug("当前数据生成的ID是:{}", keys.getInt("ID"));
}
ResultSet select = statement.executeQuery("SELECT * FROM USER");
while (select.next()) {
System.out.print("查询结果:");
System.out.print(String.format("id=%d,", select.getInt("ID")));
System.out.print(String.format("name=%s,", select.getString("NAME")));
System.out.println(String.format("role_id=%d,", select.getInt("ROLE_ID")));
}
}
复制代码
因为在调用 executeUpdate() 方法时,我们传入了 Statement.RETURN_GENERATED_KEYS 参数,因此,我们可以通过 getGeneratedKeys() 方法获来取到到本次 Statement 语句生成的主键数据.
日志数据:
...省略... DEBUG [main] - 当前数据生成的ID是:3 查询结果:id=1,name=Panda1,role_id=1, 查询结果:id=2,name=Panda2,role_id=2, 查询结果:id=3,name=Panda,role_id=1, ...省略... 复制代码
但是,针对相同的测试代码,如果在调用 executeUpdate() 方法时.我们传入的是 Statement.NO_GENERATED_KEYS 参数, getGeneratedKeys() 方法就无法获取到主键信息了.
日志数据:
...省略... 查询结果:id=1,name=Panda1,role_id=1, 查询结果:id=2,name=Panda2,role_id=2, 查询结果:id=3,name=Panda3,role_id=1, ...省略... 复制代码
感受了原始的 jdbc 操作之后,我们再来感受一下 mybatis 中 useGeneratedKeys 属性的效果,不过在此之前,我们需要先了解一下 keyProperty 和 keyColumn 属性.
keyProperty和keyColumn属性
当我们决定配置 useGeneratedKeys 属性的值为 true ,以此来获取数据库生成的主键时,我们就需要着手配置 keyProperty 属性和 keyColumn 属性了.
keyProperty 属性的取值是 java 对象的属性名,当获取到新增数据记录的主键之后, mybatis 会将主键对应的值赋给 keyProperty 指向的属性,如果有多个属性,可以使用 , 进行分隔.
keyColumn 属性稍有不同,他只在 statementType 属性为 PREPARED 时才会生效.
keyColumn 属性用于指定当 Statement 执行完成后,需要返回的数据的数据列名称,如果有多个数据列的话,可以使用 , 进行分隔.
前面我们已经说过了 statementType 属性用于控制 Statement 实例的类型,其中 PREPARED 对应的是 PreparedStatement .
在 JDBC 中, Connection 通过 prepareStatement() 方法来创建 PreparedStatement 对象.
prepareStatement() 方法有多种重载实现,我们这里主要看下面两种:
方法一:
PreparedStatement prepareStatement(String sql, int autoGeneratedKeys)
throws SQLException;
复制代码
方法二:
PreparedStatement prepareStatement(String sql, String columnNames[])
throws SQLException;
复制代码
当我们通过方法一来获取 PreparedStatement 对象时,如果我们把 autoGeneratedKeys 参数设置为 1 , PreparedStatement 的 getGeneratedKeys() 方法返回的是本次 PreparedStatement 语句执行时创建的主键信息.
当我们通过方法二来获取 PreparedStatement 对象时, PreparedStatement 的 getGeneratedKeys() 方法返回的 columnNames 参数指定的数据列的数据信息.
在 statementType 属性的取值为 PREPARED 时,如果我们配置了 keyColumn 属性,那么 mybatis 将会通过方法二来创建 PreparedStatement 对象.
现在,我们先通过原始的 JDBC 操作来感受这两个方法的不同之处.
在创建 PreparedStatement 对象,我们明确指定了需要返回 NAME 属性.
@Test
@SneakyThrows
public void specifyTheReturnedDataColumnTest(){
// 获取连接
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
@Cleanup
Connection connection = sqlSession.getConnection();
assert connection.getMetaData().supportsGetGeneratedKeys();
// 执行插入
PreparedStatement statement = connection.prepareStatement("insert into USER ( name, role_id)/n" +
"values ('Panda3', 1);",new String[]{"NAME"});
statement.execute();
ResultSet keys = statement.getGeneratedKeys();
while (keys.next()) {
log.debug("当前数据生成的NAME是:{}", keys.getString("NAME"));
}
ResultSet select = connection.createStatement().executeQuery("SELECT * FROM USER");
while (select.next()) {
System.out.print("查询结果:");
System.out.print(String.format("id=%d,", select.getInt("ID")));
System.out.print(String.format("name=%s,", select.getString("NAME")));
System.out.println(String.format("role_id=%d,", select.getInt("ROLE_ID")));
}
}
复制代码
日志数据:
...省略... DEBUG [main] - 当前数据生成的NAME是:Panda3 查询结果:id=1,name=Panda1,role_id=1, 查询结果:id=2,name=Panda2,role_id=2, 查询结果:id=3,name=Panda3,role_id=1, ...省略... 复制代码
现在调整一下,让他返回主键:
@Test
@SneakyThrows
public void noSpecifyTheReturnedDataColumnTest(){
// 获取连接
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
@Cleanup
Connection connection = sqlSession.getConnection();
assert connection.getMetaData().supportsGetGeneratedKeys();
// 执行插入
PreparedStatement statement = connection.prepareStatement("insert into USER ( name, role_id)/n" +
"values ('Panda3', 1);",Statement.RETURN_GENERATED_KEYS);
statement.execute();
ResultSet keys = statement.getGeneratedKeys();
while (keys.next()) {
log.debug("当前数据生成的ID是:{}", keys.getInt("ID"));
}
ResultSet select = connection.createStatement().executeQuery("SELECT * FROM USER");
while (select.next()) {
System.out.print("查询结果:");
System.out.print(String.format("id=%d,", select.getInt("ID")));
System.out.print(String.format("name=%s,", select.getString("NAME")));
System.out.println(String.format("role_id=%d,", select.getInt("ROLE_ID")));
}
}
复制代码
日志数据:
...省略... DEBUG [main] - 当前数据生成的ID是:3 查询结果:id=1,name=Panda1,role_id=1, 查询结果:id=2,name=Panda2,role_id=2, 查询结果:id=3,name=Panda3,role_id=1, ...省略... 复制代码
useGeneratedKeys属性的使用
了解了 useGeneratedKeys , keyProperty 以及 keyColumn 属性之后,我们通过实际操作来看一下他们的效果.
新建一个简单的映射配置:
<insert id="insert" parameterType="org.apache.learning.sql.select.use_generaed_keys.User"
useGeneratedKeys="true"
keyProperty="id"
>
insert into USER (name, role_id)
values (#{name}, #{roleId})
</insert>
复制代码
在这个映射配置中,我们启用了 useGeneratedKeys ,同时指定了表的主键对应着 User 对象的 id 属性.
因此,从理论上讲, mybatis 在执行完 insert 语句之后,需要将新增数据的 id 值回填到入参的 User 对象的 id 属性上.
针对这个理论,我们提供一个简单的单元测试:
@Test
public void insertTest() {
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
Mapper mapper = sqlSession.getMapper(Mapper.class);
// 新建用户
User user = new User();
user.setName("panda2");
user.setRoleId(2);
// 执行数据库操作
int count = mapper.insert(user);
assert count > 0;
assert user.getId() != null;
log.debug("新增用户ID为:{}",user.getId());
}
复制代码
单元测试成功运行,同时在运行完 insert 方法之后, user 对象的 id 属性被赋值为 3 .
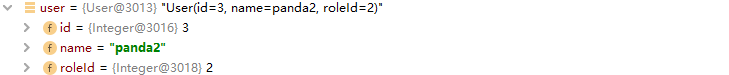
理论验证通过,这是关键运行日志:
...省略... DEBUG [main] - 新增用户ID为:3 ...省略... 复制代码
接下来,我们修改上面的映射配置,为其添加 keyColumn 属性配置,为了确定 keyColumn 属性的作用,这里我们将其配置为 name :
<insert id="insert" parameterType="org.apache.learning.sql.select.use_generaed_keys.User"
useGeneratedKeys="true"
keyProperty="id"
keyColumn="name"
>
insert into USER (name, role_id)
values (#{name}, #{roleId})
</insert>
复制代码
再次运行上面的单元测试,我们会得到一条异常信息:
incompatible data type in conversion: from SQL type VARCHAR to java.lang.Integer, value: panda2 复制代码
很明显,报错信息中的 panda2 是我们为 user 对象的 name 属性配置的值,这表明我们配置的 keyColumn 属性生效了.
selectKey子元素
除了 useGeneratedKeys 之外,我们还可以通过配置 selectKey 元素来获取数据库主键.
selectKey 元素的用法有点像是一个阉割版的 select 元素,他可以配置一个简单的查询语句, mybatis 会通过该查询语句来获取指定数据列的值.:
<!ELEMENT selectKey (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST selectKey resultType CDATA #IMPLIED statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED keyProperty CDATA #IMPLIED keyColumn CDATA #IMPLIED order (BEFORE|AFTER) #IMPLIED databaseId CDATA #IMPLIED > 复制代码
KeyGenerator接口定义
在 mybatis 中,无论是 useGeneratedKeys 属性配置还是 selectKey 元素配置,最终都会被转换成 KeyGenerator 接口的实现,该接口用于在执行指定 sql 之前或者之后,通过执行一些额外的操作,获取并处理指定数据列的值.
/**
* 主键生成器
*
* @author Clinton Begin
*/
public interface KeyGenerator {
/**
* 前置生成主要只要用户oracle等使用序列机制的ID生成方式
*
* @param executor SQL执行器
* @param ms 映射的声明语句
* @param stmt 声明语句
* @param parameter 参数
*/
void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
/**
* 后置生成主要用于mysql等使用自增机制的ID生成方式
*
* @param executor SQL执行器
* @param ms 映射的声明语句
* @param stmt 声明语句
* @param parameter 参数
*/
void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
}
复制代码
KeyGenerator 接口中定义了两个方法,其中 processBefore() 方法在执行指定 sql 之前被调用, processAfter() 方法在执行指定 sql 之后调用.
在 selectKey 元素中,有一个比较特别的 order 属性,该属性有 BEFORE 和 AFTER 两个取值,就分别对应着上面的两个方法.
mybatis 默认为 KeyGenerator 接口提供了三种实现:
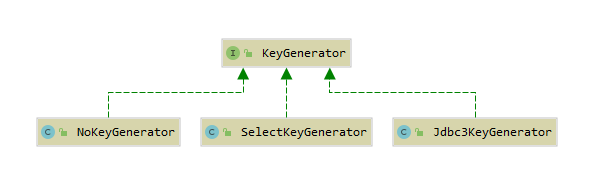
其中 Jdbc3KeyGenerator 是针对 useGeneratedKeys 属性配置的实现, SelectKeyGenerator 是针对 selectKey 元素配置的实现, NoKeyGenerator 是默认的空实现.
关于 KeyGenertor 实现类的更多细节,我们会在后面的文章给出.
selectKey元素的使用
selecetKey 元素的用法并不复杂,它的大部分属性定义,我们在其他元素中都已经有所了解,现在让我们来体验一下它的实际使用效果.
<select id="selectAll" resultType="org.apache.learning.sql.select.use_generaed_keys.User">
SELECT * FROM USER
</select>
<insert id="insertWithSelectKey" parameterType="org.apache.learning.sql.select.use_generaed_keys.User">
<selectKey order="BEFORE" keyProperty="id" resultType="int">
select max(id) + 1 from USER
</selectKey>
insert into USER
(name, role_id)
values (#{name}, #{roleId})
</insert>
复制代码
我们在 insertWithSelectKey 中通过配置 selectKey 指定了一条查询语句来为 id 属性赋值,同时通过 selectKey 元素的 order 属性配置了赋值行为在执行 insert 语句之前完成.
在数据库初始化脚本中,我们已经插入了两条记录,所以 select max(id) + 1 from USER 的返回值为 3 .
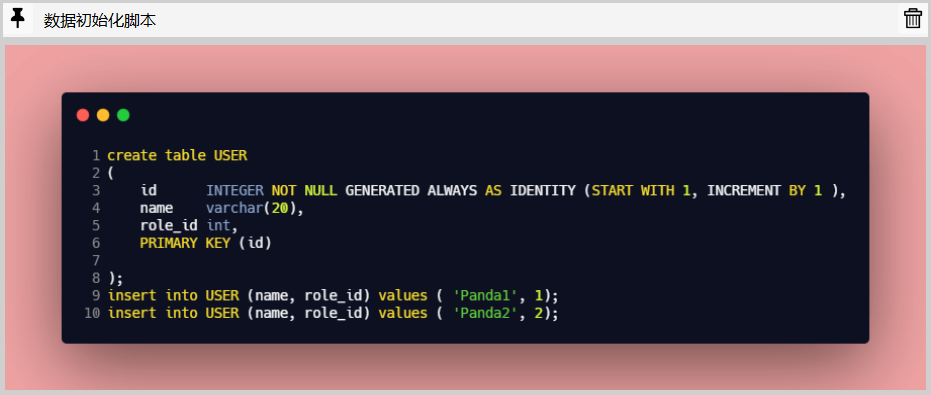
所以针对下面的单元测试,理论新增用户 ID 和实际新增用户 ID 应该是一致的:
@Test
public void insertWithSelectKey() {
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
Mapper mapper = sqlSession.getMapper(Mapper.class);
User user = new User();
user.setName("panda2");
user.setRoleId(2);
int count = mapper.insertWithSelectKey(user);
assert count > 0;
assert user.getId() != null;
log.debug("理论新增用户ID为:{}", user.getId());
List<User> users = mapper.selectAll();
users.stream().max(Comparator.comparingInt(User::getId)).ifPresent((u) -> {
log.debug("实际新增用户ID为:{}", u.getId());
});
}
复制代码
在实际运行中,两个 ID 也的确是一致的,均为 3 :
...省略... DEBUG [main] - ==> Preparing: select max(id) + 1 from USER DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 1 DEBUG [main] - ==> Preparing: insert into USER (name, role_id) values (?, ?) DEBUG [main] - ==> Parameters: panda2(String), 2(Integer) DEBUG [main] - <== Updates: 1 DEBUG [main] - 理论新增用户ID为:3 DEBUG [main] - ==> Preparing: SELECT * FROM USER DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 3 DEBUG [main] - 实际新增用户ID为:3 ...省略... 复制代码
仔细看上面的日志信息,很明显 select max(id) + 1 from USER 语句先执行, insert into USER (name, role_id) values (?, ?) 语句后执行.
如果我们调整上面 selectKey 元素的 order 属性配置为 AFTER :
...省略... DEBUG [main] - ==> Preparing: insert into USER (name, role_id) values (?, ?) DEBUG [main] - ==> Parameters: panda2(String), 2(Integer) DEBUG [main] - <== Updates: 1 DEBUG [main] - ==> Preparing: select max(id) + 1 from USER DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 1 DEBUG [main] - 理论新增用户ID为:4 DEBUG [main] - ==> Preparing: SELECT * FROM USER DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 3 DEBUG [main] - 实际新增用户ID为:3 ...省略... 复制代码
insert into USER (name, role_id) values (?, ?) 语句将会在 select max(id) + 1 from USER 语句之前执行,这时候我们就得到了一个错误的用户 ID 数据.
因此,当使用 selectKey 元素的时候,我们需要 正确配置 其 order 属性.
selectKey 元素也拥有 keyProperty 和 keyColumn 两个属性定义,在运行过程中, mybatis 将会从 selectKey 元素对应的查询结果对象中取出 keyColumn 指定的属性,并将其赋值给通过 keyProperty 属性来指定的方法入参对象的属性.
上面这句话可能比较绕,我们通过一个测试代码来看一下:
<insert id="insertWithSelectKeyAndKeyColumn" parameterType="org.apache.learning.sql.select.use_generaed_keys.User">
<selectKey order="AFTER" keyProperty="id,name,roleId" keyColumn="id,name,roleId" resultType="org.apache.learning.sql.select.use_generaed_keys.User">
select id, name +'_suffix' as name ,role_id as roleId from USER ORDER BY id DESC LIMIT 0,1
</selectKey>
insert into USER
(name, role_id)
values (#{name}, #{roleId})
</insert>
复制代码
单元测试类:
@Test
public void insertWithSelectKeyAndKeyColumn() {
@Cleanup
SqlSession sqlSession = sqlSessionFactory.openSession();
Mapper mapper = sqlSession.getMapper(Mapper.class);
User param = new User();
param.setName("panda2");
param.setRoleId(2);
log.debug("原始param对象数据为:{}",param);
assert mapper.insertWithSelectKeyAndKeyColumn(param) >0;
log.debug("语句执行后对象数据为:{}",param);
}
复制代码
单元测试的关键运行日志如下:
DEBUG [main] - 原始param对象数据为:User(id=null, name=panda2, roleId=2) DEBUG [main] - Opening JDBC Connection DEBUG [main] - Setting autocommit to false on JDBC Connection [org.hsqldb.jdbc.JDBCConnection@1cf2fed4] DEBUG [main] - ==> Preparing: insert into USER (name, role_id) values (?, ?) DEBUG [main] - ==> Parameters: panda2(String), 2(Integer) DEBUG [main] - <== Updates: 1 DEBUG [main] - ==> Preparing: select id, name +'_suffix' as name ,role_id as roleId from USER ORDER BY id DESC LIMIT 0,1 DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 1 DEBUG [main] - 语句执行后对象数据为:User(id=3, name=panda2_suffix, roleId=2) 复制代码
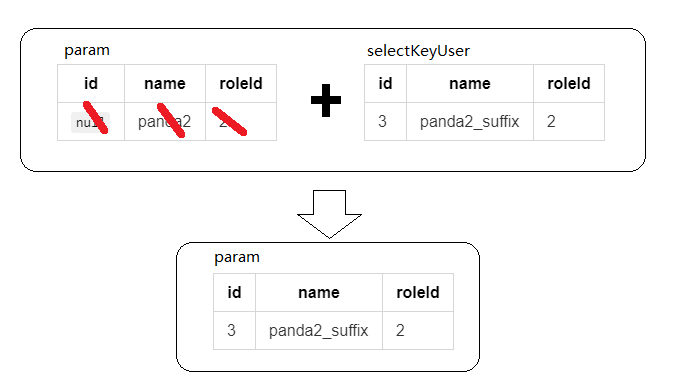
在上面的单元测试中,我们创建了一个名为 param 的 User 对象:
| id | name | roleId |
|---|---|---|
null |
panda2 | 2 |
并将该对象作为入参传递给了 insertWithSelectKeyAndKeyColumn() 方法,在方法执行完毕之后,我们的 param 对象数据发生了变化,不仅被填充了 id 属性,就连 name 属性的值也和原来不同了:
| id | name | roleId |
|---|---|---|
| 3 | panda2_suffix | 2 |
这其中究竟发生了什么呢?
注意看上面 insertWithSelectKeyAndKeyColumn() 方法的 xml 配置,根据其中 selectKey 元素的配置,在 insert 语句执行完毕之后,将会执行 select 语句来获取 id 最大的 User 记录,并把该记录转换为 User 对象,这里将查询到的 User 对象称之为 selectKeyUser .
select 语句:
select id, name +'_suffix' as name ,role_id as roleId from USER ORDER BY id DESC LIMIT 0,1 复制代码
selectKeyUser 的数据记录:
| id | name | roleId |
|---|---|---|
| 3 | panda2_suffix | 2 |
之后根据 selectKey 元素的 keyProperty 和 keyColumn 属性的配置, selectKeyUser 对象的 id , name , roleId 这三个属性的值,将会赋给 param 对象中的同名属性:

因此,当 insertWithSelectKeyAndKeyColumn() 方法执行完成之后, param 对象的数据就发生了奇妙的变化:
delete元素
相对而言, delete 元素的 DTD 定义比 insert/update 还要简单一些:
<!ELEMENT delete (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST delete id CDATA #REQUIRED parameterMap CDATA #IMPLIED parameterType CDATA #IMPLIED timeout CDATA #IMPLIED flushCache (true|false) #IMPLIED statementType (STATEMENT|PREPARED|CALLABLE) #IMPLIED databaseId CDATA #IMPLIED lang CDATA #IMPLIED > 复制代码
delete 元素用于配置删除语句,通常来说,完成数据删除操作之后,我们并不需要获取被删除数据的主键信息,因此 delete 元素不支持用于配置主键的属性.

除此之外, delete 元素和 insert/update 元素并无不同之处.
正文到此结束
- 本文标签: XML stream java src tar SqlSessionFactory 代码 session REST 源码 ACE map cache 实例 单元测试 rmi Connection ORM IDE bug list 测试 删除 sql sqlsession Select ResultSet mysql 主键值 https Property 数据 id value apache http 数据库 SQL执行 App Statement 参数 db autocommit UI IO key tk update entity Oracle mapper CTO JDBC mybatis tab 文章 配置 executor
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

