Java:手写线程安全LRU缓存X探究影响命中率的因素
最近遇到一个需求,需要频繁访问数据库,但是访问的内容只是 id + 名称 这样的简单键值对。
频繁的访问数据库,网络上和内存上都会给数据库服务器带来不小负担。
于是打算写一个简单的LRU缓存来缓存这样的键值对。考虑到tomcat的用户办法访问是多线程进行的。
所以还要保证cache是线程安全的。避免在用户操作的时候修改了cache导致其他用户读到不合法的信息。
构思
一, 数据结构选取
思路:
1.最简单的是用链表,最新访问的元素所在节点插入到头节点的后面,当要回收的时候就去释放链表尾部节点。
问题 : 如果数据量巨大,那么这条链表就会十分长,即使是线性时间复杂度的查找,也会耗掉不少时间。
2.打散链表,采用散列法,将节点散列到散列表中,这样,我们一长条的链表就会被打散成若干长度更小的链表。
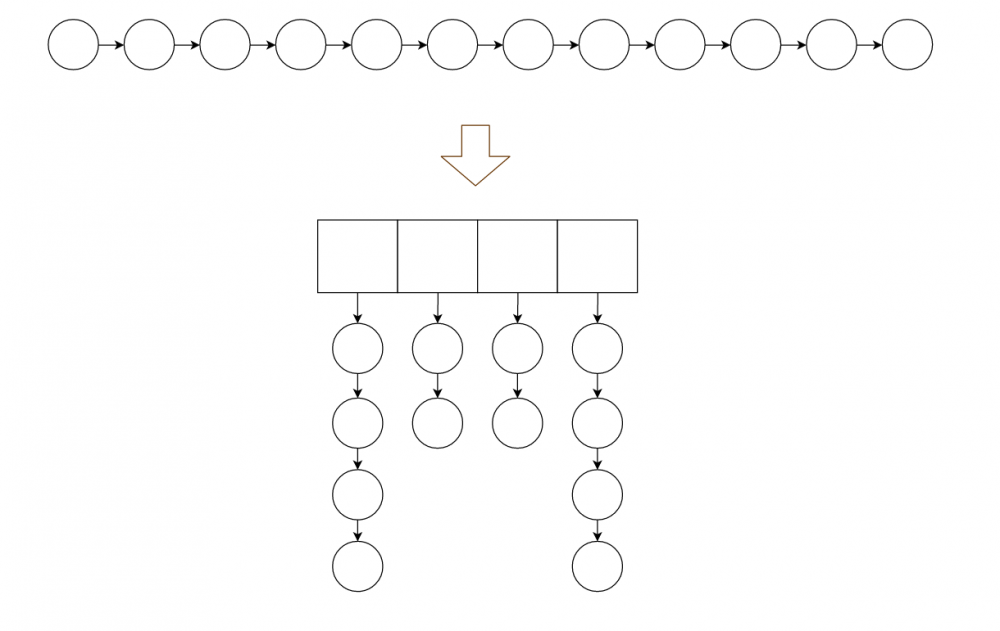
假如我们的散列算法设计得当,让整个链表均匀的洒在散列表上,那么所用时间最坏情况可以 变成原本的 1/m , m是散列表的大小。
3.在2中,虽然我们使用了散列表来打散,但是如果散列算法不当,或者正好碰到最坏情况,还是有可能节点集中在一条链上。
所以我们可以把链表设计成树,这样我们就保证了最坏时的logN级的查找复杂度。
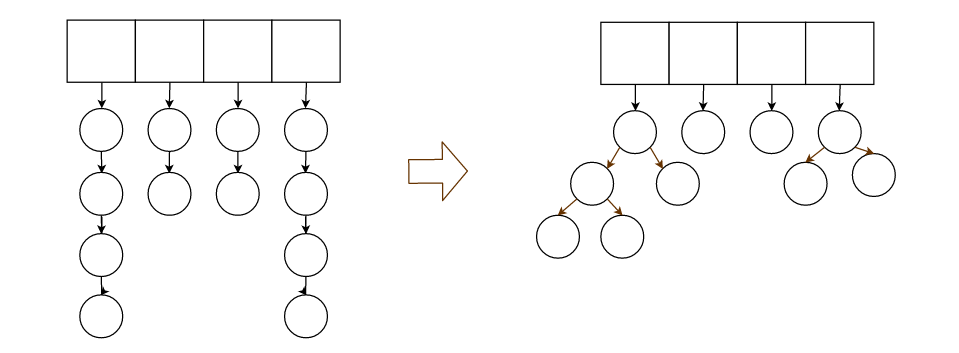
总体上方法3会比2高效,但是实现起来复杂得多,所以我们采用方法2。
二, 回收策略
回收的时候需要考虑到
1.怎么样让回收的内容在最近尽可能不被访问到,这可能需要结合自己的程序业务来决定,一般的做法是回收最近最少使用的内容,不可能准确预测某内容在不久
的将来不被访问。
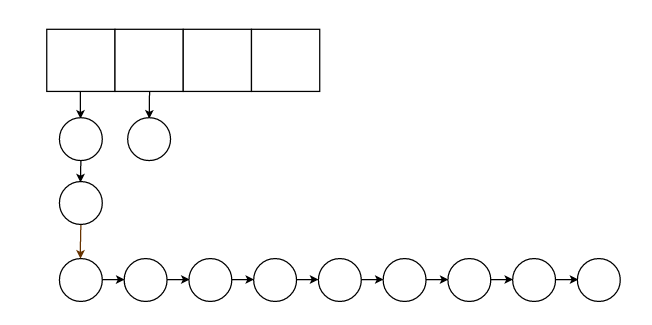
2.回收内容之后需要让整个存储结构尽可能均匀,尽可能不出现
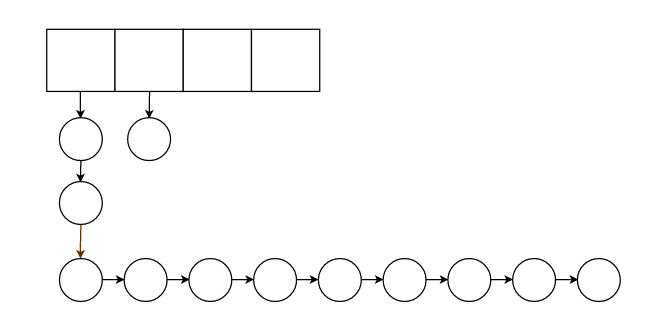
这种情况。
于是采取策略,回收最长的那个链表的末尾节点,这种做法不能说百分百可靠,
可能因为散列算法设计不合理,导致节点都聚集在某个槽中,这样的话那个槽的链表就会特别长。
这时这个链表上的节点总是要访问的,但是我们回收的是最长的链表,那么我们总是在回收最近要访问的内容
就很不合理,但是如果我们的散列算法得当,那么我们就能回收的同时保持整个散列表结构逻辑上均匀。
绝对均匀也不好,因为如果绝对均匀,那么就没有一个较长的链表,可以缓存尽可能多,最近被频繁访问的内容。
所以,散列算法的设计十分重要。
三, 线程安全
线程安全,这里是简单地采用 ReentrantReadWriteLock,分为读写两把锁,在读取缓存但不写的时候,占用读锁。
如果没命中,需要向散列表中写新内容,或修改,则占用写锁。
注意点:
并发编程使用 ReentrantReadWriteLock 无法做到锁升级,需要释放读锁之后再获取写锁。
在释放读锁到获取写锁之间,需要考虑到所有其他线程获取写锁修改某些我们需要的量的情况。
比如我们对A访问用读写锁R
R.readLock().lock();
M = null;
//0
if(A != null){
M = A;
}
R.readLock().unlock();
//1
R.writeLock().lock();
//2
function(M);
A = new XX();
在1处,可能有其他线程先占有了写锁,并且执行完了2之后的代码,所以我们在0处的判断就失效了。
所以在2之后还需要判断
//2
if(A != null){
M = A;
}
也就是要考虑释放读锁与获取写锁之间,其他线程可能获取写锁修改某些共享量。
在下面的代码注释中有详细说明
开始编写
首先,我们要实现我们选取的数据结构,这里选的是2中的数据结构。
3中的数据结构读者可以自行实现,需要注意的是,树如果旋转,则需要把旋转后的根节点挂到散列表上
1.链表设计
我们知道,链表的脱链和挂入有时候需要检查前驱后继节点是否非空。这使得我们的代码实现起来很复杂,而且维护的时候阅读也不方便。
于是我们打算让一根链表生来就有头和尾节点,这两个节点存放的值是无用的,这两个节点是闲置的,这样我们删除链表中的某个节点时
就不用检查他的前驱后继是否非空,因为有一开始的两个头尾节点,前驱后继肯定非空。
我们回收的时候回收的是尾节点的前一个节点。有一种特殊情况,如果头节点和尾节点之间没有其他节点呢?回收的不就是头节点?
我们的回收策略是回收长度最长的链表中的节点,并且当整个散列表的大小到达了特定值才会回收,所以一般不会回收头节点。
虽然多了头和尾两个节点,但是相比于我们成千上万的数据,微不足道。
private class Node{
/**
* 当前节点的id
*/
long now;
/**
* id - 名称键值对中的名称
*/
String name;
/**
* 前驱
*/
Node pre;
/**
* 后继
*/
Node next;
}
2.每条链表的管理结构
为了管理每个链表,比如记录链表的长度信息,保存链表的头尾指针(引用)。我们需要用一个数据结构管理链表
private class HeadManager{
/**
* 链接前一个管理结构(链表长度小于等于当前链表)和后一个管理结构(链表长度大于等于当前链表)
*/
HeadManager pre, next;
/**
* 当前链表的长度
*/
int size = 0;
/**
* 链表中闲置的头节点
* */
Node head = new Node();
/**
* 链表中闲置的尾节点
*/
Node tail = new Node();
{
/*
* 一开始让首尾相连
*/
head.next = tail;
tail.pre = head;
}
}
这些管理结构是按照各自的链表长度大小组织成一条链表的,我们暂且称之为管理链表。当我们要回收节点的时候,就去找管理链表末尾的管理结构,把他的倒数第二个节点释放(尾节点闲置)。同样我们也需要闲置的管理结构头节点和尾节点来简化我们的代码。
总体框架:
public class PlatformCache {
/**
* 当整个散列表中的值超过这个大小,就会开始回收
*/
private static final int MAX_SIZE = 1024;
/**
* 散列表所在数组的初始大小
*/
private static final int INIT_SIZE = 64;
private static Double rate = 0.0;
private static Double time = 0.0;
/**
* 读写锁
*/
private ReentrantReadWriteLock reentrantReadWriteLock;
/**
* 整个散列表中的节点数
*/
private int size;
/**
* 散列表
*/
private HeadManager[] tables;
/**
* 管理结构链表中的闲置头
*/
private HeadManager inOrderHead;
/**
* 管理结构链表中的闲置尾
*/
private HeadManager inOrderTail;
/**
* 单例
*/
private static PlatformCache instance;
}
/**
* 获取单例
*/
public static PlatformCache getInstance(){
if(instance == null){
synchronized (PlatformCache.class){
if(instance == null){
instance = new PlatformCache();
}
}
}
return instance;
}
public String getName(long id){
try {//锁读锁 防止读入时修改
reentrantReadWriteLock.readLock().lock();
//简单散列
int index = hash(id);
HeadManager manager = tables[index];
//如果管理结构不在散列表中 就让fresh = true
boolean fresh = false;
if(manager != null){
Node head = manager.head.next;
while(head != null && head != manager.tail){
//命中
if(id == head.now){
reentrantReadWriteLock.readLock().unlock();
reentrantReadWriteLock.writeLock().lock();
//到这里的时候,可能有其他线程操作过我们命中了的节点
//所以需要看一下我们的节点有没有被删除(前驱后继为空)
if(head.pre == null || head.next == null){
//如果删除了,就跳出循环,和没命中合并成同一种情况
reentrantReadWriteLock.readLock().lock();
reentrantReadWriteLock.writeLock().unlock();
break;
}
//移到前面 表示最近访问过
moveForward(manager, head);return head.name;
}
head = head.next;
}
}else{
fresh = true;
}
//访问数据库
Platform platform = mapper.selectByPrimaryKey(id);
if(platform != null){
reentrantReadWriteLock.readLock().unlock();
//1
reentrantReadWriteLock.writeLock().lock();
//这里的检查很重要 因为在1处可能别的线程获得了锁
//修改了我们要访问的index下标处的内容
if(tables[index] == null){
//创建新的 管理结构 并挂到散列表上
manager = new HeadManager();
tables[index] = manager;
}else{
//如果其他线程创建了管理结构
//那么他们可能把我们想要的节点放到链表中了
//所以再次遍历节点,看看能否找到
manager = tables[index];
fresh = false;
Node head = manager.head.next;
while(head != null && head != manager.tail){
//命中
if(id == head.now){
//下面不用加写锁因为当前已经获得写锁
//移到前面 表示最近访问过
moveForward(manager, head);
return head.name;
}
head = head.next;
}
}
//新建一个Node
Node more = new Node();
more.name = platform.getPlatformName();
more.now = platform.getPlatformId();
//插入到链表中闲置头节点的下一位
Node now = manager.head.next;
manager.head.next = more;
more.next = now;
now.pre = more;
more.pre = manager.head;
//更改管理结构管理的链表大小和总大小
manager.size ++;
size ++;
if(fresh){
//如果新建了管理结构 就把管理结构挂入到大小队列
insertBeforeHead(manager);
}
//管理结构的链表大小增加时排序管理结构队列
whenInc(manager);
//超出了我们的预算,则进行回收
if(size > MAX_SIZE){
if(inOrderTail.pre == inOrderHead){
logger.error("缓存中头和尾之间没有缓存节点!");
throw new ServiceException("缓存错误已经记录日志");
}
//删除链表长度最大的管理结构的链表尾节点的前一个节点
//inOrderTail是闲置的管理结构尾节点
//inOrderTail.pre是链表长度最大的管理结构
//inOrderTail.pre.tail是链表闲置的尾节点
//inOrderTail.pre.tail.pre真正需要回收的节点
deleteNode(inOrderTail.pre.tail.pre);
//管理结构的链表长度和散列表总大小均-1
inOrderTail.pre.size --;
size --;
whenDec(inOrderTail.pre);
}
return platform.getPlatformName();
}
return null;
}finally {
//释放所有锁
try {
//保险起见 固定释放读写锁
try {
if(reentrantReadWriteLock.writeLock().isHeldByCurrentThread()){
reentrantReadWriteLock.writeLock().unlock();
}
}catch (Exception e){
}
try {
reentrantReadWriteLock.readLock().unlock();
}catch (Exception e){
}
}catch (Exception e){
//可以写入日志
}
}
}
辅助性方法外提:
private void deleteNode(Node node){
Node next = node.next;
node.pre.next = next;
next.pre = node.pre;
node.pre = node.next = null;
}
/**
* 往后找,找到链表长度比自己小的管理结构,并且插到他后面
*/
private void whenInc(HeadManager manager){
HeadManager back = manager.next;
while(back.size < manager.size && back != inOrderTail){
back = back.next;
}
manager.pre.next = manager.next;
manager.next.pre = manager.pre;
HeadManager pre = back.pre;
pre.next = manager;
manager.pre = pre;
back.pre = manager;
manager.next = back;
}
private void insertBeforeHead(HeadManager manager) {
HeadManager now = inOrderHead.next;
inOrderHead.next = manager;
manager.next = now;
now.pre = manager;
manager.pre = inOrderHead;
}
private int hash(Long id){
Long tmp = id;
id ^= tmp >>> 32;
id ^= tmp >>> 16;
id ^= tmp >>> 8;
id ^= tmp >>> 4;
return Math.toIntExact(id & (tables.length - 1));
}
/**
* 往前找,找到链表长度比自己大的管理结构,并且插到他前面
*/
private void whenDec(HeadManager manager){
HeadManager front = manager.pre;
while(front.size > manager.size && front != inOrderHead){
front = front.pre;
}
manager.pre.next = manager.next;
manager.next.pre = manager.pre;
HeadManager next = front.next;
front.next = manager;
next.pre = manager;
manager.pre = front;
manager.next = next;
}
//被访问的节点放在链表头部
private void moveForward(HeadManager manager, Node head){
Node now = manager.head;
Node next = head.next;
head.pre.next = next;
next.pre = head.pre;
head.pre = now;
head.next = now.next;
now.next.pre = head;
now.next = head;
}
测试
测试了一下,不是很OK。
测试环境:
硬件: i5 4核CPU 内存8G
软件: Jmeter 300线程,每次请求使用limit 随机数,50 请求50条数据,数据库表中总共有3300条数据
tomcat7.0
JDK8.0
散列表的大小是64
最大容纳Node个数是1024
系统跑到稳定的时候,命中率平均大概只有40%
其中稳定后的一组:
命中率: 0.3817002017558209
各个链表长度:
0 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 0 Manager总数: 64
Node总数: 1024.0
方差: 8.0
散列表大小:64
可以看出我们每个管理结构的链表长度都相等,整个散列表均匀,但是命中率实在太低。
我们改变一些量来尝试提高命中率。
尝试1.改变散列算法
原本的散列法:
散列算法1:
int index = Math.toIntExact((id & (tables.length - 1)));
直接用以散列表长度-1 做为掩码取后几位做为下标。
我们采用新的散列算法:
将id每一位的特征都用上。
散列算法2:
private int hash(Long id){
id |= id >> 8;
id |= id >> 8;
id |= id >> 8;
id |= id >> 8;
return Math.toIntExact(id & (tables.length - 1));
}
看看命中率会不会提高。
运行稳定后,命中率上升到50%左右。
运行稳定后的一组数据:
命中率: 0.5101351858242434
各个链表长度:
0 1 2 3 6 7 7 7 8 8 9 9 9 9 9 10 10 11 11 12 14 16 16 16 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 21 21 21 21 21 21 21 21 21 21 21 21 21 21 0Manager总数: 63
Node总数: 1024.0
方差: 43.465388506960714
散列表大小 : 64
我们发现,虽然均匀程度下降,但是命中率有所上升,因为充分利用了元素标识id的特征。元素散列到散列表中的位置更有独特性。
当然,因为我们用的是按位或,所以元素会往数组下标大的方向聚集。
所以进一步改进我们的hash算法
散列算法3:
private int hash(Long id){
Long tmp = id;
id ^= tmp >>> 32;
id ^= tmp >>> 16;
id ^= tmp >>> 8;
id ^= tmp >>> 4;
return Math.toIntExact(id & (tables.length - 1));
}
我们让每一位都参与到特征值的生成中,但是减少了往下标大的地方聚集的趋势
稳定后结果:
命中率: 0.561265216523648
各个链表长度:
0 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 0 Manager总数: 64
Node总数: 1024.0
方差: 8.0
散列表大小 : 64
我们发现散列表变得均匀,命中率相应也上升了不少。
与散列算法1比起来,散列表都是均匀的,为什么命中率高了接近20%呢?
原因可能是因为 :算法1的散列表均匀是回收算法造成的,算法1散列的结果仍然很不均匀,导致散列出的下标集中在某些地方。
频繁地对这些地方进行访问,可能频繁的在这些地方插入节点,所以这些活跃区域,也是长度增长最快的区域,而回收的时候又
总是回收这些活跃区域,导致我们不久之前刚刚创建的节点总是被回收,导致命中率下降。
算法2虽然也是保持散列表均匀,但是对散列表的访问因为散列算法散列得得当,所以分散得比较开,所以是
“在均匀情况下,增加一个,回收一个,而且大大减少了回收的是最近访问过的节点的概率”
尝试2.改变散列表的大小,但不改变最大Node数量
最大节点数还是1024,而散列表的槽数增加成128。
运行稳定后,命中率没有明显的上升。
原因可能是因为就算增加了槽数,但总的节点数不变,该回收还是回收,导致命中率没有明显上升。
但是链表的平均长度减小,在链表中遍历查询元素的时间减少。
使用散列算法2.
命中率: 0.5074192929043583
各个链表长度:
0 1 1 1 1 1 2 2 2 3 3 3 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 7 7 8 8 8 8 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 11 11 11 11 11 11 11 11 11 11 11 11 11 0Manager总数: 125
Node总数: 1024.0
方差: 9.836877824000004
使用散列算法3.
命中率: 0.5587484035759898
各个链表长度:
0 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 0 Manager总数: 128
Node总数: 1024.0
方差: 1.0
尝试3.散列表大小不变,增加节点个数
这个方法大概率是会增加命中率的,因为减少了回收次数,而且节点数接近我们记录总数的时候,命中率甚至可能接近100%。
最大节点数增加成是2048,散列表的槽数为128。
运行稳定后: 命中率接近100%
使用散列算法2.
命中率: 0.9811895632415405
各个链表长度:
0 1 1 1 1 1 2 2 2 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 6 7 8 8 8 8 8 9 9 9 10 10 10 11 11 11 11 11 11 11 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 13 14 14 14 15 15 15 15 15 16 16 16 17 18 18 18 18 18 20 20 20 20 20 21 21 22 22 23 25 34 35 37 37 37 37 38 38 39 40 40 40 41 41 42 45 46 49 49 49 49 50 50 50 0 Manager总数: 125
Node总数: 2048.0
方差: 198.067511296
尝试4.改变回收策略
简单的采取回收当前位置的末尾节点。
比如我们在0号位置插入一个新增的Node,导致整个散列表节点数超过了最大值,那么就直接回收0号位置的末尾节点(不是真正的末尾节点,真正的末尾节点被闲置)
使用散列算法2
命中率: 0.5508982035928144
0 0 0 0 0 0 0 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 8 8 8 8 9 9 10 10 10 10 10 10 11 11 11 11 12 12 12 13 13 14 15 16 16 17 18 19 20 20 20 20 21 21 22 23 23 24 25 28 29 29 31 34 0
Manager总数: 125
Node总数: 1024.0
方差: 57.676877824
散列表大小 : 128
使用散列算法3
命中率: 0.561866802451144
0 1 4 4 4 4 4 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 11 11 11 11 11 11 11 11 11 11 12 12 12 12 13 14 0
Manager总数: 128
Node总数: 1024.0
方差: 5.578125
散列表大小 : 128
命中率并没有多大的变化,但是散列表均匀程度下降。
扩容与重散列:
明天考试,以后再更
最终采用了:
1.散列算法3,保证散列的均匀性
2.回收最长链表
3.最大节点数 : 采用总数据量的45%。比如总共有1000条数据,则最多有450个节点。选取的理由是命中率可以达到80%,满足我的业务需求
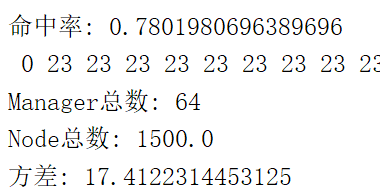
1500 / 3300 约等于 45%
当然,这是我的鸡肋业务,如果真的要用到海量数据的业务中去,则仅供参考。
有不妥之处,多谢指出。
正文到此结束
- 本文标签: UI 测试环境 App java 并发编程 数据库 cache 代码 Select node http map 缓存 JMeter rmi 快的 mapper 多线程 遍历 tab src 安全 synchronized 注释 软件 https ORM 管理 selectByPrimaryKey 代码注释 测试 final cat id 时间 组织 tomcat Service 数据 并发 HTML 服务器 锁 线程 IO 需求 key db 删除
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

