JVM深入理解-内存调优与GC日志
CPU飚高分析
一般可以使用
- ps -Lfp pid
- ps -mp pid -o THREAD, tid, time
- top -Hp pid
[root@redis webapps]# top -Hp 22272 top - 10:09:30 up 9 days, 22:10, 1 user, load average: 0.00, 0.00, 0.00 Tasks: 30 total, 0 running, 30 sleeping, 0 stopped, 0 zombie Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 3923196k total, 3795588k used, 127608k free, 153056k buffers Swap: 6160376k total, 0k used, 6160376k free, 3079244k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22272 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22278 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22279 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22282 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22283 root 20 0 2286m 122m 11m S 0.0 3.2 3:01.48 java 22287 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22288 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22289 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java 22290 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.03 java 22291 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.34 java 22292 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.06 java 22299 root 20 0 2286m 122m 11m S 0.0 3.2 0:06.37 java 22301 root 20 0 2286m 122m 11m S 0.0 3.2 1:09.73 java 17034 root 20 0 2286m 122m 11m S 0.0 3.2 0:00.00 java
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为22283 的线程。
用 printf “%x/n” 22283
[root@redis webapps]# printf ‘%x/n’ 22283 570b得到22283 的十六进制值为570b。
下一步轮到jstack上场了,它用来输出进程22272 的堆栈信息,然后根据线程ID的十六进制值grep,如下:
[root@redis webapps]# jstack 22272 | grep 570b “SchedulerThread” prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait()
可以看到CPU消耗在SchedulerThread这个类的Object.wait(),定位到下面的代码:
// Idle wait
synchronized(sigLock) {
try {
if(!halted.get()) {
sigLock.wait(timeUntilContinue);
}
}
catch (InterruptedException ignore) {
}
}
它是轮询任务的空闲等待代码,上面的sigLock.wait(timeUntilContinue)就对应了前面的Object.wait()。
总结:可以通过PID找到对应的的线程,然后通过JVM的jstack找到栈里对应的线程信息。通过找到对应的代码一般就能分析出CPU占用高的原因。
利用JVM命令分析
jstat -gcutil
[root@xxxx-nccz8-b57dd64fc-nt9dj logs]# jstat -gcutil 1 2000 20 S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 0.00 8.64 2.62 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 2.81 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 2.81 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 2.81 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.06 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.10 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.10 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.21 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.22 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 3.61 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 6.47 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 6.76 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 6.81 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.07 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.08 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.38 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.38 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.62 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.62 27.32 80.59 73.86 1350 22.705 5 1.449 24.154 0.00 8.64 7.76 27.32 80.59 73.86 1350 22.705 5 1.449 24.154
S0:Heap上的 Survivor space 0 区已使用空间的百分比
S1:Heap上的 Survivor space 1 区已使用空间的百分比
E:Heap上的 Eden space 区已使用空间的百分比
O:Heap上的 Old space 区已使用空间的百分比
M:Metaspace 区已使用空间的百分比
YGC:从应用程序启动到采样时发生 Young GC 的次数
YGCT:从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC:从应用程序启动到采样时发生 Full GC 的次数
FGCT:从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT:从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
jmap -heap
[root@xxxx-nccz8-b57dd64fc-nt9dj startup]# jmap -heap 1 Attaching to process ID 1, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.191-b12 using parallel threads in the new generation. using thread-local object allocation. Concurrent Mark-Sweep GC Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 2147483648 (2048.0MB) NewSize = 805306368 (768.0MB) MaxNewSize = 805306368 (768.0MB) OldSize = 1342177280 (1280.0MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 268435456 (256.0MB) CompressedClassSpaceSize = 260046848 (248.0MB) MaxMetaspaceSize = 268435456 (256.0MB) G1HeapRegionSize = 0 (0.0MB) Heap Usage: New Generation (Eden + 1 Survivor Space): capacity = 724828160 (691.25MB) used = 284988360 (271.7860794067383MB) free = 439839800 (419.4639205932617MB) 39.318058503687276% used Eden Space: capacity = 644349952 (614.5MB) used = 275398000 (262.63999938964844MB) free = 368951952 (351.86000061035156MB) 42.74043928228616% used From Space: capacity = 80478208 (76.75MB) used = 9590360 (9.146080017089844MB) free = 70887848 (67.60391998291016MB) 11.916716634644748% used To Space: capacity = 80478208 (76.75MB) used = 0 (0.0MB) free = 80478208 (76.75MB) 0.0% used concurrent mark-sweep generation: capacity = 1342177280 (1280.0MB)
通过heap命令能看出当前整个堆的一个使用情况,used与free的一个实际占用比。
jmap -dump
jmap -dump:live,format=b,file=xxxxxx.20200707.hprof 1
我们一般会在Dockerfile里面配置好如果出现OOM的情况,保留一下现场。 -XX:HeapDumpPath=/alidata1/admin/xxxxx/logs
利用JProfiler分析
发现大对象,这里是因为我们用了Jeager链路跟踪,但是用过多线程导致ThreadLocal没有释放掉。
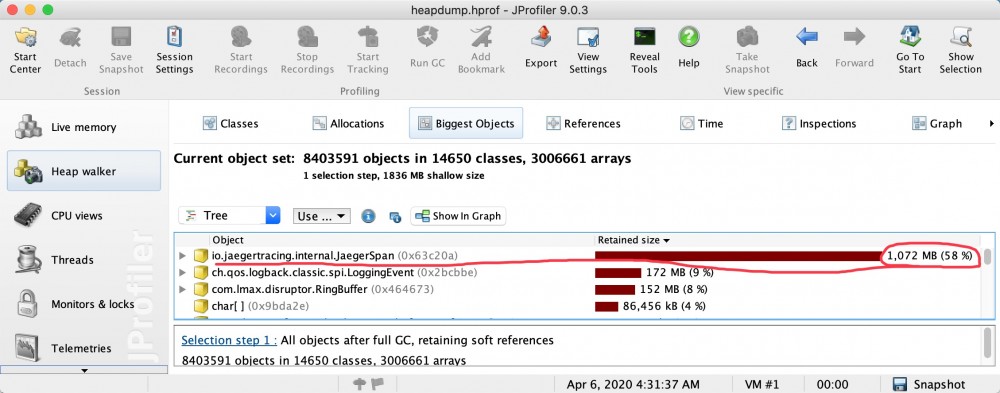
发现char[]占用比较多,并且找出是从哪儿产生的?
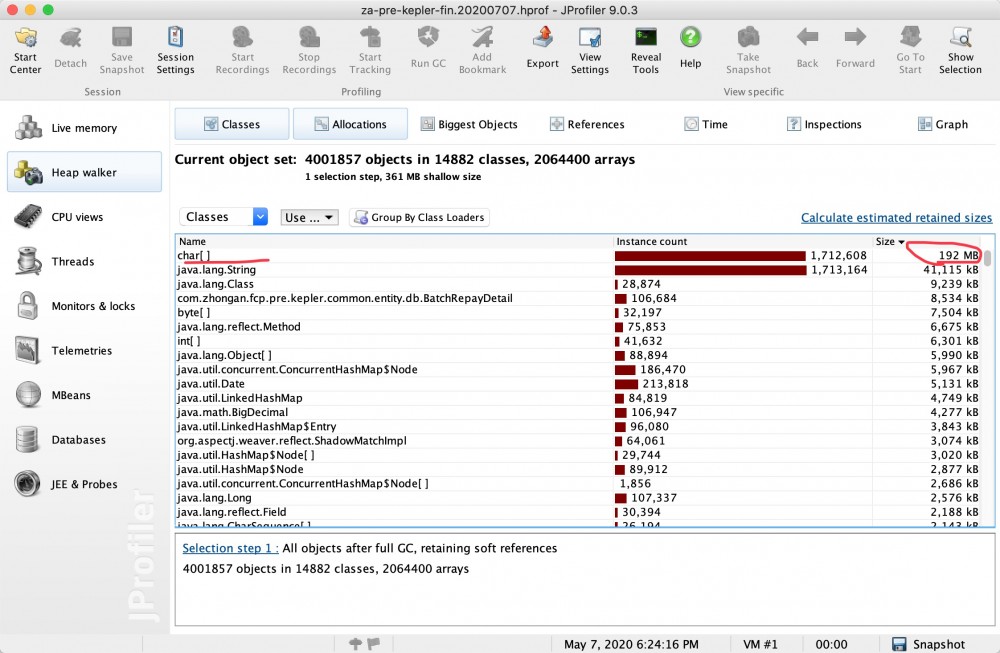
通过Outgoing references找到具体的实例情况。
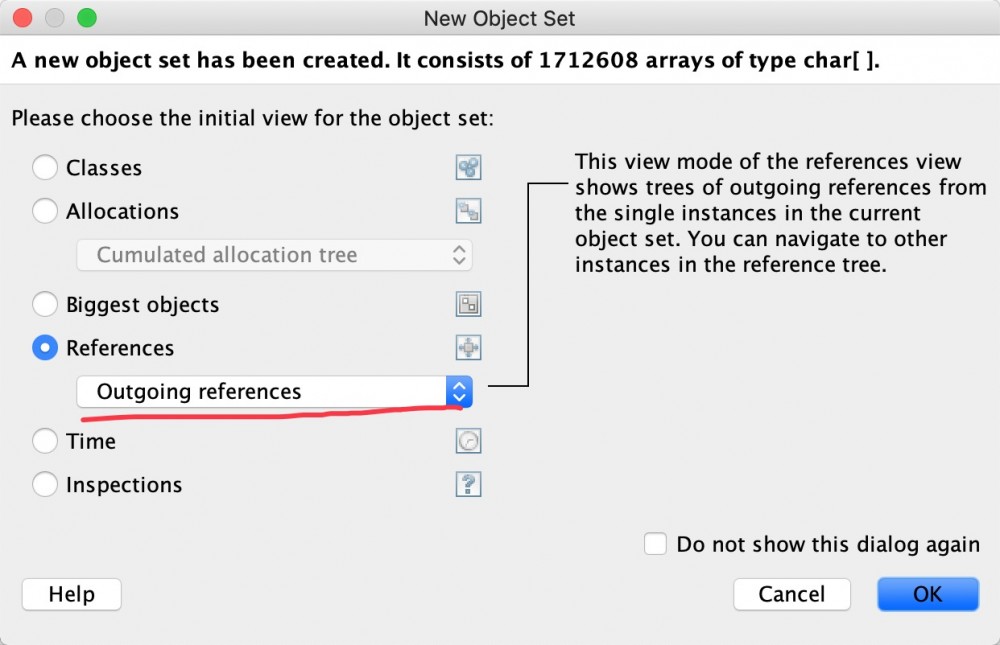
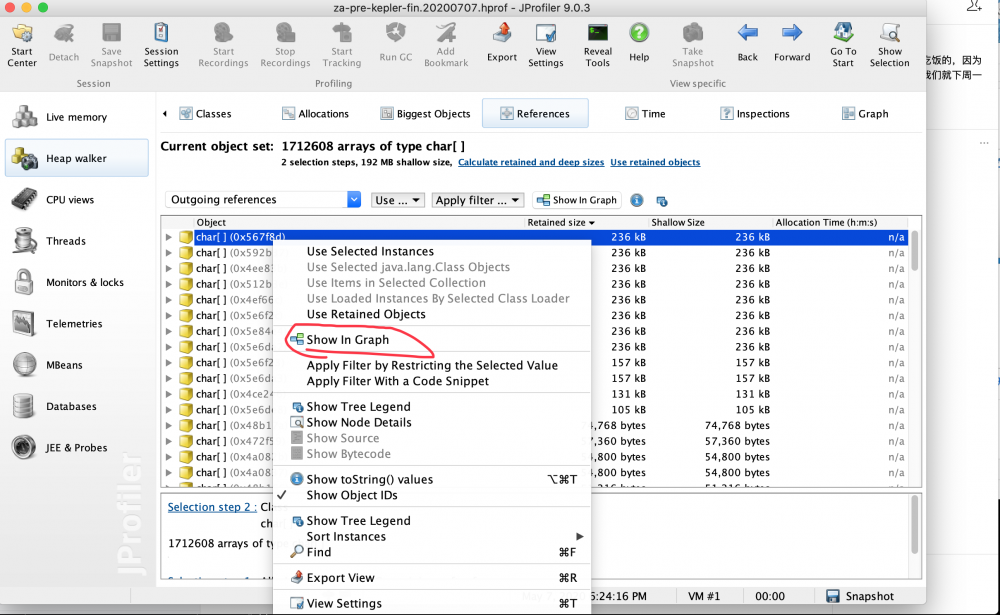
什么是outgoing references与incoming references?让我们通过示例来了解有关 Incoming references 和 Outgoing references 的更多知识。例如,一个应用程序的源代码如下所示:
public class A {
private C c1 = C.getInstance();
}
public class B {
private C c2 = C.getInstance();
}
public class C {
private static C myC = new C();
public static C getInstance() {
return myC;
}
private D d1 = new D();
private E e1 = new E();
}
public class D {
}
public class E {
}
public class SimpleExample {
public static void main (String argsp[]) throws Exception {
A a = new A();
B b = new B();
}
}
- 对象 A 和对象 B 持有对象 C 的引用
- 对象 C 持有对象 D 和对象 E 的引用
在这个示例项目中,让我们具体分析下对象 C 的 Incoming references 和 Outgoing references 。
对象 C 的 Incoming References
拥有对象 C 的引用的所有对象都称为 Incoming references。在此示例中,对象 C 的“Incoming references”是对象 A、对象 B 和 C 的类对象 。
对象 C 的 Outgoing References
对象 C 引用的所有对象都称为 Outgoing References。在此示例中,对象 C 的“outgoing references”是对象 D、对象 E 和 C 的类对象。
然后通过 Show in graph 的菜单,一层一层的点击。直到你看到你最熟悉的类。

如何看GC日志
设置gc日志配置
-XX:+PrintGC 输出简要GC日志 -XX:+PrintGCDetails 输出详细GC日志 -Xloggc:gc.log 输出GC日志到文件 -XX:+PrintGCTimeStamps 输出GC的时间戳(以JVM启动到当期的总时长的时间戳形式) -XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800) -XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息 -verbose:gc -XX:+PrintReferenceGC 打印年轻代各个引用的数量以及时长
-XX:+PrintGC
如果只设置 -XX:+PrintGC 那么打印的日志如下所示:
[GC (Allocation Failure) 61805K->9849K(256000K), 0.0041139 secs] 1、GC 表示是一次YGC(Young GC) 2、Allocation Failure 表示是失败的类型 3、61805K->9849K 表示年轻代从61805K降为9849K 4、256000K表示整个堆的大小 5、0.0041139 secs表示这次GC总计所用的时间 在JDK 8中,-verbose:gc是-XX:+PrintGC一个别称,日志格式等价与:-XX:+PrintGC,。
-XX:+PrintGCDetails
[GC (Allocation Failure) [PSYoungGen: 53248K->2176K(59392K)] 58161K->7161K(256000K), 0.0039189 secs] [Times: user=0.02 sys=0.01, real=0.00 secs] 1、GC 表示是一次YGC(Young GC) 2、Allocation Failure 表示是失败的类型 3、PSYoungGen 表示年轻代大小 4、53248K->2176K 表示年轻代占用从53248K降为2176K 5、59392K表示年轻带的大小 6、58161K->7161K 表示整个堆占用从53248K降为2176K 7、256000K表示整个堆的大小 8、 0.0039189 secs 表示这次GC总计所用的时间 9、[Times: user=0.02 sys=0.01, real=0.00 secs] 分别表示,用户态占用时长,内核用时,真实用时。 时间保留两位小数,四舍五入。
-XX:+PrintGCTimeStamps
1.963: [GC (Allocation Failure) 61805K->9849K(256000K), 0.0041139 secs]
如果加上 -XX:+PrintGCTimeStamps 那么日志仅仅比1.1介绍的最前面多了一个时间戳: 1.963 , 表示从JVM启动到打印GC时刻用了1.963秒。
-XX:+PrintGCDateStamps
2019-03-05T16:56:15.108+0800: [GC (Allocation Failure) 61805K->9849K(256000K), 0.0041139 secs]
如果加上 -XX:+PrintGCDateStamps 那么日志仅仅比1.1介绍的最前面多了一个日期时间: 2019-03-05T16:56:15.108+0800 , 表示打印GC的时刻的时间是 2019-03-05T16:56:15.108+0800 。+0800表示是东8区。
CMS GC日志详细分析
[GC (CMS Initial Mark) [1 CMS-initial-mark: 19498K(32768K)] 36184K(62272K), 0.0018083 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] [CMS-concurrent-mark-start] [CMS-concurrent-mark: 0.011/0.011 secs] [Times: user=0.02 sys=0.00, real=0.00 secs] [CMS-concurrent-preclean-start] [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] [CMS-concurrent-abortable-preclean-start] CMS: abort preclean due to time [CMS-concurrent-abortable-preclean: 0.558/5.093 secs] [Times: user=0.57 sys=0.00, real=5.09 secs] [GC (CMS Final Remark) [YG occupancy: 16817 K (29504 K)][Rescan (parallel) , 0.0021918 secs][weak refs processing, 0.0000245 secs][class unloading, 0.0044098 secs][scrub symbol table, 0.0029752 secs][scrub string table, 0.0006820 secs][1 CMS-remark: 19498K(32768K)] 36316K(62272K), 0.0104997 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] [CMS-concurrent-sweep-start] [CMS-concurrent-sweep: 0.007/0.007 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] [CMS-concurrent-reset-start] [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
CMS日志分为两个STW(stop the world)
分别是 init remark (1) 与 remark (7)两个阶段。一般耗时比YGC长约10倍(个人经验)。
(1)、 [GC (CMS Initial Mark) [1 CMS-initial-mark: 19498K(32768K)] 36184K(62272K), 0.0018083 secs][Times: user=0.01 sys=0.00, real=0.01 secs]
会STW(Stop The World),这时候的老年代容量为 32768K, 在使用到 19498K 时开始初始化标记。耗时短。
(2)、 [CMS-concurrent-mark-start]
并发标记阶段开始
(3)、 [CMS-concurrent-mark: 0.011/0.011 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
并发标记阶段花费时间。
(4)、 [CMS-concurrent-preclean-start]
并发预清理阶段,也是与用户线程并发执行。虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从 新生代 晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。
(5)、 [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
并发预清理阶段花费时间。
(6)、 [CMS-concurrent-abortable-preclean-start] CMS: abort preclean due to time [CMS-concurrent-abortable-preclean: 0.558/5.093 secs][Times: user=0.57 sys=0.00, real=5.09 secs]
并发可中止预清理阶段,运行在并行预清理和重新标记之间,直到获得所期望的eden空间占用率。增加这个阶段是为了避免在重新标记阶段后紧跟着发生一次垃圾清除
(7)、 [GC (CMS Final Remark) [YG occupancy: 16817 K (29504 K)][Rescan (parallel) , 0.0021918 secs][weak refs processing, 0.0000245 secs][class unloading, 0.0044098 secs][scrub symbol table, 0.0029752 secs][scrub string table, 0.0006820 secs][1 CMS-remark: 19498K(32768K)] 36316K(62272K), 0.0104997 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
会STW(Stop The World),收集阶段,这个阶段会标记老年代全部的存活对象,包括那些在并发标记阶段更改的或者新创建的引用对象
(8)、 [CMS-concurrent-sweep-start]
并发清理阶段开始,与用户线程并发执行。
(9)、 [CMS-concurrent-sweep: 0.007/0.007 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
并发清理阶段结束,所用的时间。
(10)、 [CMS-concurrent-reset-start]
开始并发重置。在这个阶段,与CMS相关数据结构被重新初始化,这样下一个周期可以正常进行。
(11)、 [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
并发重置所用结束,所用的时间。
参考地址
- https://mp.weixin.qq.com/s/bSv2YDqOJsWYj6ZjAnf1ew
- https://blog.csdn.net/preterhuman_peak/article/details/43674037
- https://juejin.im/post/5c80b0f451882532cd57b541
如果大家喜欢我的文章,可以关注个人订阅号。欢迎随时留言、交流。如果想加入微信群的话一起讨论的话,请加管理员简栈文化-小助手(lastpass4u),他会拉你们进群。

正文到此结束
- 本文标签: 2019 多线程 总结 tar ACE java线程 Region 空间 root src IO 进程 并发 管理 final jstack Dockerfile 配置 时间 web example 线程 cache synchronized redis Docker js http bug map 代码 java 详细分析 grep ORM Full GC 数据 实例 https ECS id apr SDN Webapps swap 文章 JVM UI App tab ask 垃圾回收 cat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

