V8引擎详解(三)——从字节码看V8的演变
本文是V8引擎详解系列的第三篇,重点内容是关于了解字节码的概念,以及字节码在V8引擎演变过程中的重要影响,同时帮您梳理v8引擎的架构帮助您更好的了解V8引擎架构,文末会有已经完成的系列文章的链接,本系列文章还在不断更新欢迎持续关注。
字节码概念
一、什么是字节码
wiki百科中字节码的描述是这样的:
字节码(英语:Bytecode)通常指的是已经经过编译,但与特定机器代码无关,需要解释器转译后才能成为机器代码的中间代码。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
按照作者的对字节码的理解大概是这样:
计算机只能识别二进制代码,而二进制代码(指令集)是不合适人类书写和阅读的,不同的CPU架构对应的指令集也是完全不同的,为了克服这个问题,大神们就创造出了适合人类的语言,也就是所谓的 “高级” 语言,这些高级语言与人类的自然语言以及数学公式的使用是非常接近的,而且不用考虑CPU架构差异。而高级语言和二进制代码之间的差异是相当大的,直接转换会非常麻烦,这时就有了二者中间的代码—— 字节码 。
二、字节码的优点
要了解字节码的优点,最直观的方式就是直接看字节码给java带来了什么,早期java推广的口号就是Compile Once,Run anywhere(一次编译到处运行),Java源代码经过编译程序编译之后生成扩展名为.class的字节码文件。再通过JVM将字节码翻译为机器的计算机指令(目标机器必须要安装对应的JVM(java虚拟机))。
Java 语言使用字节码的方式,一定程度的解决了解释性语言执行效率低的问题,同时由于字节码不针对一种特定的机器,所以Java程序无须重新编译就可在多种不同的计算机上运行。
字节码的优点总结来说就是:
- 不针对特定CPU架构
- 比原始的高级语言转换成机器语言更快
V8的演变
一、V8早期架构
V8未诞生之前,早期最主流的JavaScript引擎是JavaScriptCore引擎。javasSriptCore是通过生成字节码再将字节码转化成二进制代码的方式运行的,而V8诞生的使命就是性能的极致,Google觉得这这种架构生成字节码会浪费时间,V8早期采用了直接生成机器码的方式如下图:

我们一起来看一下V8早期架构如何执行js代码的:
- 第一步,将js源代码转化成AST(抽象语法树)
- 第二步,通过Full-Codegen引擎编译AST变成二进制文件,然后直接执行这些二进制文件。
- 第三步,在执行二进制代码的过程中,标记重复执行的函数,将标记的代码通过Crankshaft引擎进行优化编译生成效率更高的二进制代码,再次运行到这个函数时使用效率更高的二进制代码。
同时采用了将二进制代码缓存(缓存到内存和硬盘上)的策略来省去重复编译的时间,在初期这种架构的确带来了速度上的改善。
二、为什么要引入字节码
随着网页的复杂化以及移动端的流行,早期的架构也带来非常多的问题,
1.内存占用问题
最核心的问题就是空间占用问题,在V8执行的过程会将js源代码转化成二进制代码并且将二进制代码存储到内存中,退出进程后会将二进制代码存储到硬盘上。
将js源码转化成的二进制代码占用的内存空间是非常巨大的,如果说一个js源码的文件大小是1M,那么生成的二进制代码可能就是十几M,而早期手机的内存普遍不高,过度占用会导致性能大大降低。

2.代码复杂度太高
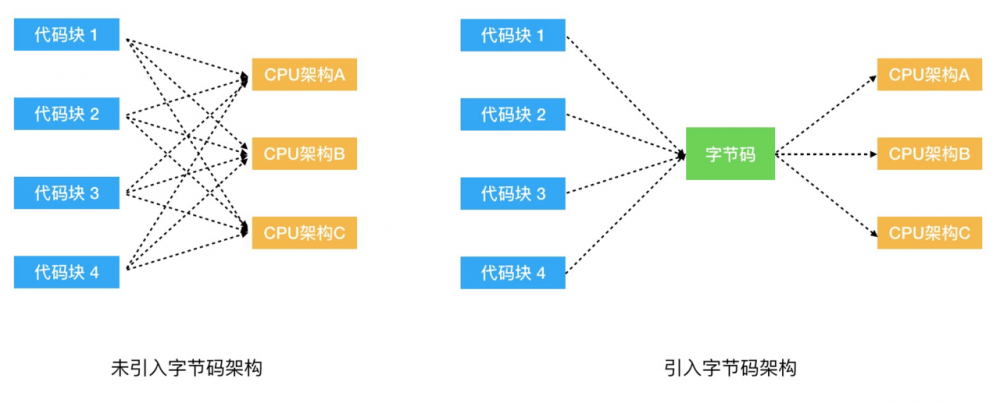
上文提到过不同的CPU架构对应的指令集是完全不同的,而市面上CPU架构的种类又非常多,那么将AST转化为二进制代码的Full-Codegen引擎以及优化编译的Crankshaft引擎要针对不同的CPU架构编写代码,这个复杂程度及工作量可想而知,而对字节码进行编译可以大大的减少这个工作量,大概如下图:
3.一个Bug
我们先来看一下这个 bug ,大概描述是这样的:
Bug的报告人在当时的Chrome浏览器下重复加载Facebook,并打开了各项监控发现:第一次加载时 v8.CompileScript 花费了 165 ms,而重复加载时发现真正耗时高的js代码并没有被缓存,导致重复加载时编译的时间和第一次加载的消耗大致相同。
导致这个问题的原因其实也很好理解,之前提到过因为二进制代码占用内存空间大,根据惰性编译的优化原则,所以V8并不会将所有代码进行编译只会编译最外层的代码,而在函数内部的代码会在第一次调用时编译,比如:

如果浏览器只缓存最外层代码,那么对我们前端高度工程化的模块来说会导致里面的关键代码却无法被缓存,这也是导致上述bug的主要原因。
三、V8现有架构
为了解决上述的问题,V8开始采用引入字节码的架构,最终采用了如下图的架构:
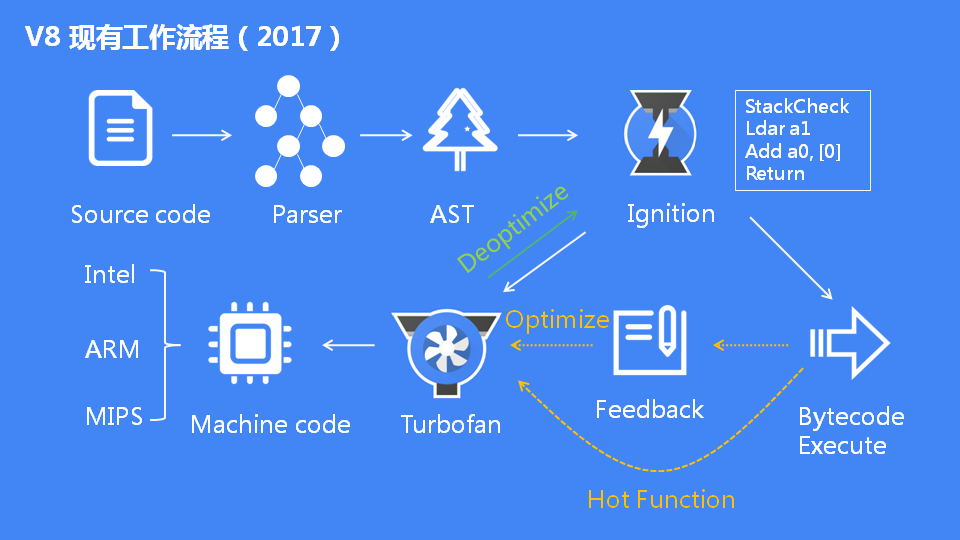
(图片来源: blog.itpub.net/69912579/vi…
我们来一起看一下V8现有架构是如何执行js代码的:
- 第一步,将js源代码转化成AST(抽象语法树)
- 第二步,通过Ignition解释器将AST编译成字节码,开始逐句对字节码进行解释成二进制代码并执行。
- 第三步,在解释执行的过程中,标记重复执行的热点代码,将标记的代码通过Turbofan引擎进行编译生成效率更高二进制代码,再次运行到这个函数时便只执行高效代码而不再解释执行字节码。
V8引入了字节码的架构模式后明显的解决了如下问题:
- 启动时间较长:启动时只需要编译出字节码,然后逐句执行字节码,编译出字节码的速度可远远快于编译出二进制代码的速度。
- 内存占用较大:字节码的空间占用也是远远低于二进制代码的空间占用。
- 代码复杂度太高:大大降低了V8适应不同CPU所需要的代码复杂程度。
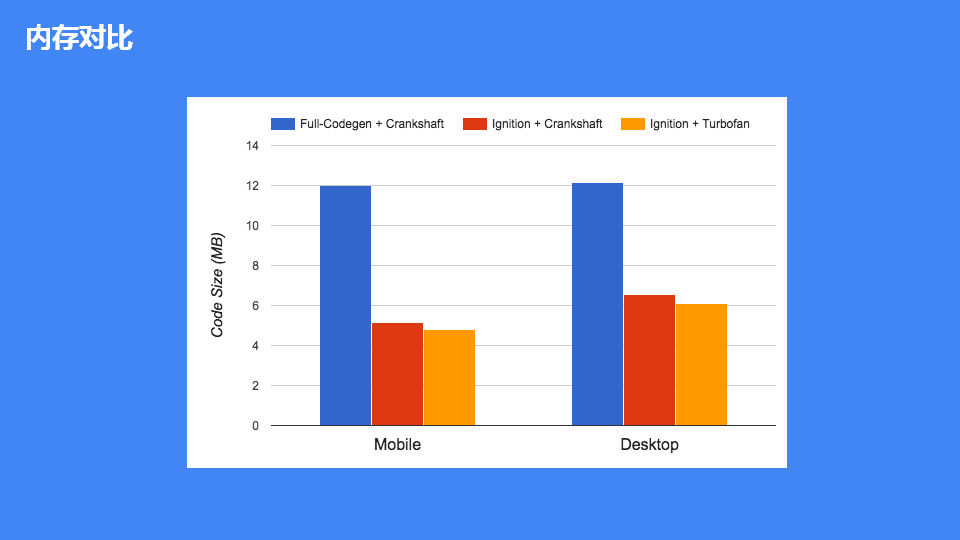
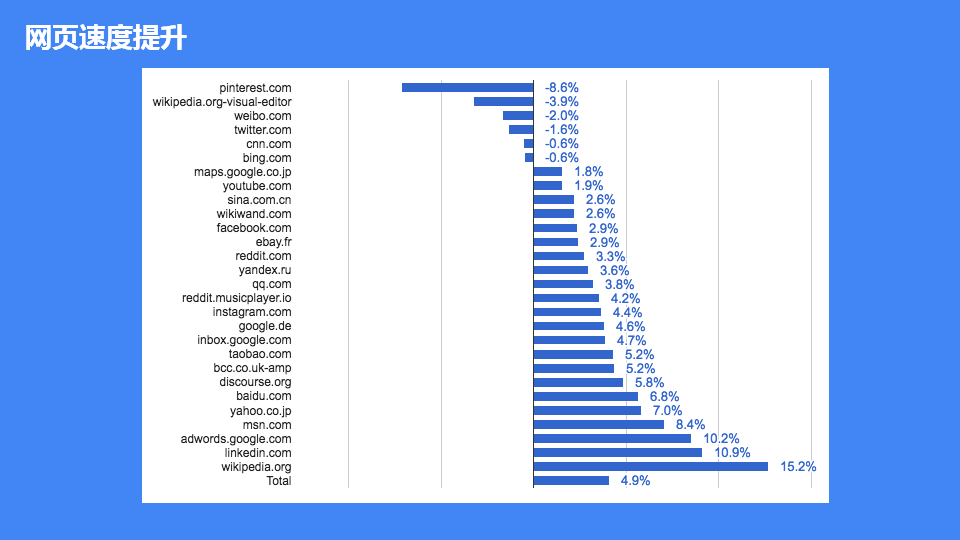
最后我们再来看一下新架构和原有架构比较带来的效果:
- 内存占用
- 网页速度
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

