删除分布在整个微服务架构中的数据 - twitter
微服务架构倾向于在整个组织中分配数据责任。这对确保删除数据提出了挑战。常见的解决方案是为每个数据集或每个记录保留设置组织范围的标准。但是,始终会有跨越多个数据集和记录的数据。这些数据通常分布在您的微服务体系结构中,需要系统和团队之间的协调才能将其删除。
一种解决方案是将数据删除不视为事件,而是流程。在Twitter,我们将此过程称为“擦除erasure”,并使用擦除管道协调系统之间的数据删除。在本文中,我们将讨论如何建立擦除管道,包括数据可发现性,访问和处理。我们还将探讨常见问题以及如何确保擦除管道的持续维护。
可发现性
首先,您需要找到需要删除的数据。有关给定事件,用户或记录的数据可能位于联机或脱机数据集中,并且可能由组织的不同部门拥有。因此,您的第一项工作就是利用您对组织的了解,对等组织的专业知识以及组织范围内的沟通渠道来编制所有相关数据的列表。
数据访问和处理方法
您通常可以通过以下三种方式之一来访问找到的数据。可以通过(1)实时API或(2)异步更改器来更改在线数据。离线存储的数据将可以通过(3)并行分布的处理框架(如 MapReduce)进行更改 。为了获取每个数据,您的管道将需要支持这三种处理方法中的每一种。
通过实时API可变的数据是最简单的。您的擦除管道可以调用该API来执行数据删除任务。一旦对每条数据的API调用均成功,则数据已被删除并且擦除管道已完成。
这种方法的缺点是,它假设每个数据删除任务都可以在API调用的时间范围内完成,通常需要几秒钟或几毫秒,而这可能需要更长的时间。在这种情况下,您的擦除管道必须变得更加复杂。在API调用范围内无法删除的数据示例包括导出到脱机快照的数据或存在于多个后端系统和缓存中的数据。这种数据非规范化是微服务体系结构固有的,可以提高性能。这也意味着将数据生命周期的责任委托给拥有数据API和业务逻辑的团队。
您需要通知数据所有者需要进行数据删除。您的擦除管道可以将擦除事件发布到分布式队列,例如 Kafka ,合作伙伴团队可以订阅该队列以启动数据删除。他们将处理擦除事件,并致电您的团队以确认数据已删除。
最后,可能存在完全脱机的数据集,其中包含需要删除的数据,例如快照或模型训练数据。在这种情况下,您可以提供一个离线数据集,合作伙伴团队可以使用该数据集从其数据集中删除可擦除数据。此脱机数据集可以像擦除事件发布者保留的日志一样简单。
擦除管道
到目前为止,我们所描述的擦除管道具有一些关键要求。它必须:
- 接受传入的删除请求
- 跟踪并保存删除哪些数据
- 调用同步API删除数据
- 发布擦除事件以进行异步擦除
- 生成擦除事件的离线数据集
一个示例擦除管道可能如下所示:
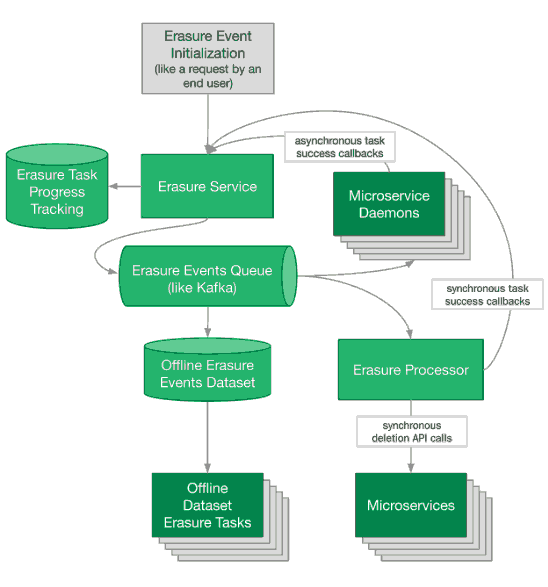
常见问题
第一个问题是服务中断和 网络分区 。擦除管道必须能够抵抗中断。它的目标是成功擦除,因此可以在恢复服务后重试其任务。一种简单的方法是确保所有擦除任务都是可重播的。发生中断时,我们只需重播掉掉的所有擦除事件。擦除跟踪系统知道哪些擦除事件尚未完全处理,可以重新发布这些事件。
有时,无论您重播一次擦除事件多少次,管道都无法完全完成。这些事件被“破坏”了。数据可能无法删除,例如因为一开始它是无效的。当您的数据拥有团队之一无法完成擦除任务时,擦除管道的完整性已超出您的控制范围。解决问题的责任需要委派给正确的团队。
维护
可以通过召集每个数据拥有团队执行其擦除任务来实现此委派。这样的管道维护(将不同的任务组合到一个 SLA 的管道中),只有在每个团队都承担擦除责任时才能进行维护。
在Twitter,我们希望拥有擦除任务的每个团队都会对任务的成功 发出警报 。我们会以几天或几周的SLA来警告擦除事件处理的整体成功,以此来补充这些信息。这使我们能够及时发现擦除流程中的问题,同时将有关单个擦除任务的问题直接交给负责的团队。
测试中
测试这样的分布式管道遵循我们一直在讨论的相同原则:每个数据拥有团队负责测试其擦除任务。作为擦除管道所有者,您需要做的就是生成他们可以响应的测试事件。
挑战在于协调合作伙伴团队拥有的系统中的测试数据创建。为了集成测试他们自己的擦除任务,这些伙伴需要在触发擦除事件之前存在测试数据。一种解决方案是测试框架,该框架将测试数据生成与cron作业配对,该cron作业在创建测试数据后的某个时间发布擦除事件。
未来方向
通过为生活在您的在线微服务和离线仓库中的 数据 [url=https://dl.acm.org/doi/10.1145/3241653.3241654]实现[/url]诸如 数据访问层 或数据目录之类 的抽象, 可以大大降低擦除管道的复杂性。Twitter正在 朝这个方向发展, 以简化复杂处理任务(如数据删除)所需的架构。数据访问层或数据目录对满足擦除请求并允许对该数据进行处理所需的数据编制索引。这将数据删除结果与数据所有权责任统一起来。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

